
Το MapReduce προσφέρει έναν αποτελεσματικό, ταχύτερο και οικονομικό τρόπο δημιουργίας εφαρμογών.
Αυτό το μοντέλο χρησιμοποιεί προηγμένες έννοιες όπως η παράλληλη επεξεργασία, η τοποθεσία δεδομένων κ.λπ., για να παρέχει πολλά οφέλη σε προγραμματιστές και οργανισμούς.
Αλλά υπάρχουν τόσα πολλά μοντέλα προγραμματισμού και πλαίσια στην αγορά που είναι δύσκολο να διαλέξετε.
Και όσον αφορά τα Μεγάλα Δεδομένα, δεν μπορείτε απλά να επιλέξετε τίποτα. Πρέπει να επιλέξετε τέτοιες τεχνολογίες που μπορούν να χειριστούν μεγάλα κομμάτια δεδομένων.
Το MapReduce είναι μια εξαιρετική λύση σε αυτό.
Σε αυτό το άρθρο, θα συζητήσω τι είναι πραγματικά το MapReduce και πώς μπορεί να είναι επωφελές.
Ας αρχίσουμε!
Πίνακας περιεχομένων
Τι είναι το MapReduce;
Το MapReduce είναι ένα μοντέλο προγραμματισμού ή ένα πλαίσιο λογισμικού εντός του πλαισίου Apache Hadoop. Χρησιμοποιείται για τη δημιουργία εφαρμογών ικανών να επεξεργάζονται μαζικά δεδομένα παράλληλα σε χιλιάδες κόμβους (που ονομάζονται συμπλέγματα ή πλέγματα) με ανοχή και αξιοπιστία σε σφάλματα.
Αυτή η επεξεργασία δεδομένων πραγματοποιείται σε μια βάση δεδομένων ή ένα σύστημα αρχείων όπου αποθηκεύονται τα δεδομένα. Το MapReduce μπορεί να λειτουργήσει με ένα σύστημα αρχείων Hadoop (HDFS) για πρόσβαση και διαχείριση μεγάλων όγκων δεδομένων.
Αυτό το πλαίσιο εισήχθη το 2004 από την Google και είναι δημοφιλές από τον Apache Hadoop. Είναι ένα επίπεδο ή μηχανή επεξεργασίας στο Hadoop που εκτελεί προγράμματα MapReduce που έχουν αναπτυχθεί σε διαφορετικές γλώσσες, όπως Java, C++, Python και Ruby.
Τα προγράμματα MapReduce στο cloud computing τρέχουν παράλληλα, επομένως είναι κατάλληλα για την εκτέλεση ανάλυσης δεδομένων σε μεγάλη κλίμακα.
Το MapReduce στοχεύει στο διαχωρισμό μιας εργασίας σε μικρότερες, πολλαπλές εργασίες χρησιμοποιώντας τις λειτουργίες «χάρτης» και «μείωσης». Θα αντιστοιχίσει κάθε εργασία και στη συνέχεια θα τη μειώσει σε αρκετές ισοδύναμες εργασίες, κάτι που έχει ως αποτέλεσμα μικρότερη ισχύ επεξεργασίας και επιβάρυνση στο δίκτυο συμπλέγματος.
Παράδειγμα: Ας υποθέσουμε ότι ετοιμάζετε ένα γεύμα για ένα σπίτι γεμάτο καλεσμένους. Έτσι, αν προσπαθήσετε να ετοιμάσετε όλα τα πιάτα και να κάνετε όλες τις διαδικασίες μόνοι σας, θα γίνει ταραχώδες και χρονοβόρο.
Ας υποθέσουμε όμως ότι εμπλέκετε μερικούς από τους φίλους ή τους συναδέλφους σας (όχι καλεσμένους) για να σας βοηθήσουν να ετοιμάσετε το γεύμα κατανέμοντας διαφορετικές διαδικασίες σε άλλο άτομο που μπορεί να εκτελέσει τις εργασίες ταυτόχρονα. Σε αυτή την περίπτωση, θα ετοιμάσετε το γεύμα πιο γρήγορα και πιο εύκολα όσο οι καλεσμένοι σας είναι ακόμα στο σπίτι.
Το MapReduce λειτουργεί με παρόμοιο τρόπο με κατανεμημένες εργασίες και παράλληλη επεξεργασία για να επιτρέψει έναν ταχύτερο και ευκολότερο τρόπο ολοκλήρωσης μιας δεδομένης εργασίας.
Το Apache Hadoop επιτρέπει στους προγραμματιστές να χρησιμοποιούν το MapReduce για να εκτελούν μοντέλα σε μεγάλα κατανεμημένα σύνολα δεδομένων και να χρησιμοποιούν προηγμένες τεχνικές μηχανικής μάθησης και στατιστικών για να βρουν μοτίβα, να κάνουν προβλέψεις, να εντοπίσουν συσχετίσεις και πολλά άλλα.
Χαρακτηριστικά του MapReduce
Μερικά από τα κύρια χαρακτηριστικά του MapReduce είναι:
- Διεπαφή χρήστη: Θα έχετε μια διαισθητική διεπαφή χρήστη που παρέχει λογικές λεπτομέρειες για κάθε πτυχή του πλαισίου. Θα σας βοηθήσει να διαμορφώσετε, να εφαρμόσετε και να συντονίσετε τις εργασίες σας απρόσκοπτα.

- Ωφέλιμο φορτίο: Οι εφαρμογές χρησιμοποιούν τις διεπαφές Mapper και Reducer για να ενεργοποιήσουν τον χάρτη και να μειώσουν τις λειτουργίες. Το Mapper αντιστοιχίζει ζεύγη κλειδιού-τιμής εισαγωγής σε ενδιάμεσα ζεύγη κλειδιού-τιμής. Ο μειωτής χρησιμοποιείται για τη μείωση των ενδιάμεσων ζευγών κλειδιού-τιμής που μοιράζονται ένα κλειδί σε άλλες μικρότερες τιμές. Εκτελεί τρεις λειτουργίες – ταξινόμηση, τυχαία αναπαραγωγή και μείωση.
- Partitioner: Ελέγχει τη διαίρεση των ενδιάμεσων πλήκτρων εξόδου χάρτη.
- Reporter: Είναι μια λειτουργία αναφοράς προόδου, ενημέρωσης μετρητών και ορισμού μηνυμάτων κατάστασης.
- Μετρητές: Αντιπροσωπεύει καθολικούς μετρητές που ορίζει μια εφαρμογή MapReduce.
- OutputCollector: Αυτή η συνάρτηση συλλέγει δεδομένα εξόδου από Mapper ή Reducer αντί για ενδιάμεσες εξόδους.
- RecordWriter: Εγγράφει την έξοδο δεδομένων ή τα ζεύγη κλειδιού-τιμής στο αρχείο εξόδου.
- DistributedCache: Διανέμει αποτελεσματικά μεγαλύτερα αρχεία μόνο για ανάγνωση που αφορούν συγκεκριμένες εφαρμογές.
- Συμπίεση δεδομένων: Ο συντάκτης εφαρμογής μπορεί να συμπιέσει τόσο τις εξόδους εργασιών όσο και τις ενδιάμεσες εξόδους χαρτών.
- Παράβλεψη κακής εγγραφής: Μπορείτε να παραλείψετε πολλές κακές εγγραφές κατά την επεξεργασία των εισόδων του χάρτη σας. Αυτή η δυνατότητα μπορεί να ελεγχθεί μέσω της κλάσης – SkipBadRecords.
- Εντοπισμός σφαλμάτων: Θα έχετε την επιλογή να εκτελέσετε σενάρια που ορίζονται από το χρήστη και να ενεργοποιήσετε τον εντοπισμό σφαλμάτων. Εάν μια εργασία στο MapReduce αποτύχει, μπορείτε να εκτελέσετε το σενάριο εντοπισμού σφαλμάτων και να βρείτε τα προβλήματα.
MapReduce Architecture
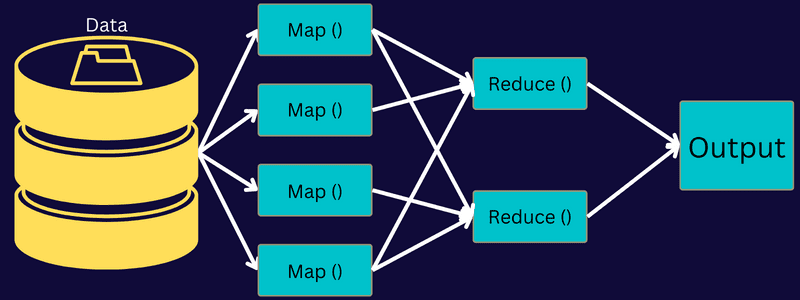
Ας κατανοήσουμε την αρχιτεκτονική του MapReduce πηγαίνοντας βαθύτερα στα στοιχεία του:
- Εργασία: Μια εργασία στο MapReduce είναι η πραγματική εργασία που θέλει να εκτελέσει ο πελάτης MapReduce. Περιλαμβάνει πολλές μικρότερες εργασίες που συνδυάζονται για να σχηματίσουν την τελική εργασία.
- Διακομιστής ιστορικού εργασιών: Είναι μια διαδικασία δαίμονας για την αποθήκευση και αποθήκευση όλων των ιστορικών δεδομένων σχετικά με μια εφαρμογή ή εργασία, όπως αρχεία καταγραφής που δημιουργούνται μετά ή πριν από την εκτέλεση μιας εργασίας.
- Client: Ένας πελάτης (πρόγραμμα ή API) φέρνει μια εργασία στο MapReduce για εκτέλεση ή επεξεργασία. Στο MapReduce, ένας ή πολλοί πελάτες μπορούν να στέλνουν συνεχώς εργασίες στο MapReduce Manager για επεξεργασία.
- MapReduce Master: Το MapReduce Master χωρίζει μια εργασία σε πολλά μικρότερα μέρη, διασφαλίζοντας ότι οι εργασίες προχωρούν ταυτόχρονα.
- Job Parts: Οι δευτερεύουσες εργασίες ή τμήματα εργασίας λαμβάνονται με διαίρεση της κύριας εργασίας. Επεξεργάζονται και συνδυάζονται επιτέλους για να δημιουργηθεί η τελική εργασία.
- Δεδομένα εισόδου: Είναι το σύνολο δεδομένων που τροφοδοτείται στο MapReduce για επεξεργασία εργασιών.
- Δεδομένα εξόδου: Είναι το τελικό αποτέλεσμα που προκύπτει μετά την επεξεργασία της εργασίας.
Έτσι, αυτό που πραγματικά συμβαίνει σε αυτήν την αρχιτεκτονική είναι ο πελάτης να υποβάλλει μια εργασία στον Master MapReduce, ο οποίος τη χωρίζει σε μικρότερα, ίσα μέρη. Αυτό επιτρέπει την ταχύτερη επεξεργασία της εργασίας, καθώς οι μικρότερες εργασίες χρειάζονται λιγότερο χρόνο για να υποβληθούν σε επεξεργασία αντί για μεγαλύτερες εργασίες.
Ωστόσο, βεβαιωθείτε ότι οι εργασίες δεν χωρίζονται σε πολύ μικρές εργασίες, επειδή εάν το κάνετε αυτό, μπορεί να χρειαστεί να αντιμετωπίσετε μεγαλύτερο κόστος διαχείρισης διαχωρισμών και να χάσετε σημαντικό χρόνο σε αυτό.
Στη συνέχεια, τα μέρη της εργασίας διατίθενται για να προχωρήσετε στις εργασίες Χάρτης και Μείωσης. Επιπλέον, οι εργασίες Map and Reduce έχουν ένα κατάλληλο πρόγραμμα με βάση την περίπτωση χρήσης που εργάζεται η ομάδα. Ο προγραμματιστής αναπτύσσει τον κώδικα που βασίζεται στη λογική για να εκπληρώσει τις απαιτήσεις.
Μετά από αυτό, τα δεδομένα εισόδου τροφοδοτούνται στην Εργασία χάρτη, έτσι ώστε ο χάρτης να μπορεί γρήγορα να δημιουργήσει την έξοδο ως ζεύγος κλειδιού-τιμής. Αντί να αποθηκεύονται αυτά τα δεδομένα σε HDFS, χρησιμοποιείται ένας τοπικός δίσκος για την αποθήκευση των δεδομένων για την εξάλειψη της πιθανότητας αναπαραγωγής.
Μόλις ολοκληρωθεί η εργασία, μπορείτε να πετάξετε την έξοδο. Ως εκ τούτου, η αναπαραγωγή θα γίνει υπερβολική όταν αποθηκεύετε την έξοδο σε HDFS. Η έξοδος κάθε εργασίας χάρτη θα τροφοδοτείται στην εργασία μείωσης και η έξοδος χάρτη θα παρέχεται στο μηχάνημα που εκτελεί την εργασία μείωσης.
Στη συνέχεια, η έξοδος θα συγχωνευθεί και θα περάσει στη λειτουργία μείωσης που έχει ορίσει ο χρήστης. Τέλος, η μειωμένη έξοδος θα αποθηκευτεί σε ένα HDFS.
Επιπλέον, η διαδικασία μπορεί να έχει πολλές εργασίες χαρτογράφησης και μείωσης για την επεξεργασία δεδομένων ανάλογα με τον τελικό στόχο. Οι αλγόριθμοι Map και Reduce είναι βελτιστοποιημένοι για να διατηρούν ελάχιστη την πολυπλοκότητα του χρόνου ή του χώρου.
Εφόσον το MapReduce περιλαμβάνει κυρίως εργασίες Χάρτης και Μείωσης, είναι σκόπιμο να κατανοήσουμε περισσότερα για αυτές. Λοιπόν, ας συζητήσουμε τις φάσεις του MapReduce για να έχουμε μια σαφή ιδέα για αυτά τα θέματα.
Φάσεις MapReduce
Χάρτης
Τα δεδομένα εισόδου αντιστοιχίζονται στα ζεύγη εξόδου ή κλειδιού-τιμής σε αυτή τη φάση. Εδώ, το κλειδί μπορεί να αναφέρεται στο αναγνωριστικό μιας διεύθυνσης ενώ η τιμή μπορεί να είναι η πραγματική τιμή αυτής της διεύθυνσης.
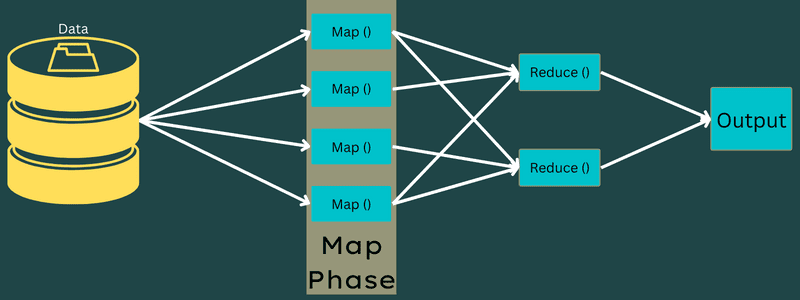
Υπάρχουν μόνο μία αλλά δύο εργασίες σε αυτή τη φάση – διαχωρισμοί και χαρτογράφηση. Ως διαχωρισμοί νοούνται τα υποτμήματα ή τα μέρη εργασίας που χωρίζονται από την κύρια εργασία. Αυτά ονομάζονται επίσης διαχωρισμοί εισόδου. Έτσι, ένας διαχωρισμός εισόδου μπορεί να ονομαστεί ένα κομμάτι εισόδου που καταναλώνεται από έναν χάρτη.
Στη συνέχεια, πραγματοποιείται η εργασία χαρτογράφησης. Θεωρείται η πρώτη φάση κατά την εκτέλεση ενός προγράμματος μείωσης χάρτη. Εδώ, τα δεδομένα που περιέχονται σε κάθε διαχωρισμό θα περάσουν σε μια συνάρτηση χάρτη για την επεξεργασία και τη δημιουργία της εξόδου.
Η συνάρτηση – Map() εκτελείται στο αποθετήριο μνήμης στα ζεύγη κλειδιού-τιμής εισόδου, δημιουργώντας ένα ενδιάμεσο ζεύγος κλειδιού-τιμής. Αυτό το νέο ζεύγος κλειδιού-τιμής θα λειτουργεί ως είσοδος που θα τροφοδοτηθεί στη συνάρτηση Reduce() ή Reducer.
Περιορίζω
Τα ενδιάμεσα ζεύγη κλειδιού-τιμής που λαμβάνονται στη φάση αντιστοίχισης λειτουργούν ως είσοδος για τη συνάρτηση Reduce ή Reducer. Παρόμοια με τη φάση της χαρτογράφησης, εμπλέκονται δύο εργασίες – ανακάτεμα και μείωση.
Έτσι, τα ζεύγη κλειδιού-τιμής που λαμβάνονται ταξινομούνται και ανακατεύονται για να τροφοδοτηθούν στο Reducer. Στη συνέχεια, το Reducer ομαδοποιεί ή συγκεντρώνει τα δεδομένα σύμφωνα με το ζεύγος κλειδιού-τιμής με βάση τον αλγόριθμο μειωτήρα που έχει γράψει ο προγραμματιστής.
Εδώ, οι τιμές από τη φάση ανακατέματος συνδυάζονται για να επιστρέψουν μια τιμή εξόδου. Αυτή η φάση συνοψίζει ολόκληρο το σύνολο δεδομένων.
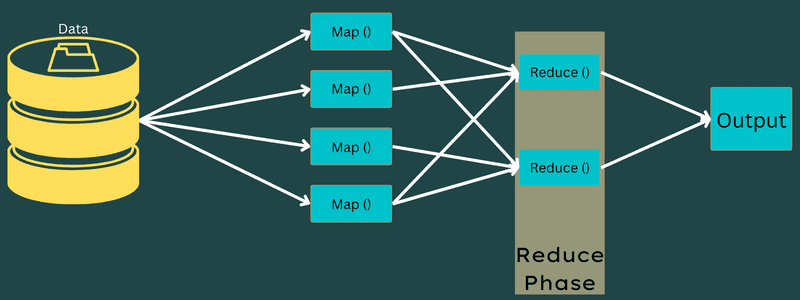
Τώρα, η πλήρης διαδικασία εκτέλεσης εργασιών Χάρτης και Μείωσης ελέγχεται από ορισμένες οντότητες. Αυτά είναι:
- Job Tracker: Με απλά λόγια, ένας ανιχνευτής εργασιών λειτουργεί ως κύριος που είναι υπεύθυνος για την πλήρη εκτέλεση μιας υποβληθείσας εργασίας. Το πρόγραμμα παρακολούθησης εργασιών διαχειρίζεται όλες τις εργασίες και τους πόρους σε ένα σύμπλεγμα. Επιπλέον, το πρόγραμμα παρακολούθησης εργασιών προγραμματίζει κάθε χάρτη που προστίθεται στο Task Tracker που εκτελείται σε έναν συγκεκριμένο κόμβο δεδομένων.
- Πολλαπλοί ιχνηλάτες εργασιών: Με απλά λόγια, πολλαπλοί ιχνηλάτες εργασιών λειτουργούν ως σκλάβοι που εκτελούν την εργασία ακολουθώντας τις οδηγίες του Job Tracker. Ένα πρόγραμμα παρακολούθησης εργασιών αναπτύσσεται σε κάθε κόμβο ξεχωριστά στο σύμπλεγμα που εκτελεί τις εργασίες Χάρτης και Μείωσης.
Λειτουργεί επειδή μια εργασία θα χωριστεί σε πολλές εργασίες που θα εκτελούνται σε διαφορετικούς κόμβους δεδομένων από ένα σύμπλεγμα. Το Job Tracker είναι υπεύθυνο για το συντονισμό της εργασίας, προγραμματίζοντας τις εργασίες και εκτελώντας τις σε πολλούς κόμβους δεδομένων. Στη συνέχεια, το Task Tracker που βρίσκεται σε κάθε κόμβο δεδομένων εκτελεί τμήματα της εργασίας και φροντίζει κάθε εργασία.
Επιπλέον, τα Task Trackers στέλνουν αναφορές προόδου στην παρακολούθηση εργασιών. Επίσης, το Task Tracker στέλνει περιοδικά ένα σήμα «καρδίας» στο Job Tracker και τον ειδοποιεί για την κατάσταση του συστήματος. Σε περίπτωση αποτυχίας, ένας ανιχνευτής εργασιών μπορεί να επαναπρογραμματίσει την εργασία σε άλλο πρόγραμμα παρακολούθησης εργασιών.
Φάση εξόδου: Όταν φτάσετε σε αυτή τη φάση, θα έχετε τα τελικά ζεύγη κλειδιού-τιμής που δημιουργούνται από το Reducer. Μπορείτε να χρησιμοποιήσετε έναν μορφοποιητή εξόδου για να μεταφράσετε τα ζεύγη κλειδιών-τιμών και να τα γράψετε σε ένα αρχείο με τη βοήθεια μιας εγγραφής εγγραφής.
Γιατί να χρησιμοποιήσετε το MapReduce;
Ακολουθούν ορισμένα από τα πλεονεκτήματα του MapReduce, εξηγώντας τους λόγους για τους οποίους πρέπει να το χρησιμοποιείτε στις εφαρμογές σας μεγάλων δεδομένων:
Παράλληλη επεξεργασία
Μπορείτε να διαιρέσετε μια εργασία σε διαφορετικούς κόμβους όπου κάθε κόμβος χειρίζεται ταυτόχρονα ένα μέρος αυτής της εργασίας στο MapReduce. Έτσι, η διαίρεση μεγαλύτερων εργασιών σε μικρότερες μειώνει την πολυπλοκότητα. Επίσης, δεδομένου ότι διαφορετικές εργασίες εκτελούνται παράλληλα σε διαφορετικά μηχανήματα αντί για ένα μόνο μηχάνημα, απαιτείται πολύ λιγότερος χρόνος για την επεξεργασία των δεδομένων.
Τοπικότητα δεδομένων
Στο MapReduce, μπορείτε να μετακινήσετε τη μονάδα επεξεργασίας στα δεδομένα και όχι το αντίστροφο.
Με παραδοσιακούς τρόπους, τα δεδομένα μεταφέρονταν στη μονάδα επεξεργασίας για επεξεργασία. Ωστόσο, με την ταχεία ανάπτυξη των δεδομένων, αυτή η διαδικασία άρχισε να δημιουργεί πολλές προκλήσεις. Μερικά από αυτά ήταν υψηλότερο κόστος, πιο χρονοβόρα, επιβάρυνση του κύριου κόμβου, συχνές αποτυχίες και μειωμένη απόδοση δικτύου.
Αλλά το MapReduce βοηθά να ξεπεραστούν αυτά τα ζητήματα ακολουθώντας μια αντίστροφη προσέγγιση – φέρνοντας μια μονάδα επεξεργασίας στα δεδομένα. Με αυτόν τον τρόπο, τα δεδομένα κατανέμονται μεταξύ διαφορετικών κόμβων όπου κάθε κόμβος μπορεί να επεξεργαστεί ένα μέρος των αποθηκευμένων δεδομένων.
Ως αποτέλεσμα, προσφέρει οικονομική αποδοτικότητα και μειώνει τον χρόνο επεξεργασίας αφού κάθε κόμβος λειτουργεί παράλληλα με το αντίστοιχο τμήμα δεδομένων του. Επιπλέον, δεδομένου ότι κάθε κόμβος επεξεργάζεται ένα μέρος αυτών των δεδομένων, κανένας κόμβος δεν θα επιβαρυνθεί υπερβολικά.
Ασφάλεια

Το μοντέλο MapReduce προσφέρει υψηλότερη ασφάλεια. Βοηθά στην προστασία της εφαρμογής σας από μη εξουσιοδοτημένα δεδομένα, ενώ παράλληλα ενισχύει την ασφάλεια του συμπλέγματος.
Επεκτασιμότητα και Ευελιξία
Το MapReduce είναι ένα πλαίσιο υψηλής κλιμάκωσης. Σας επιτρέπει να εκτελείτε εφαρμογές από πολλά μηχανήματα, χρησιμοποιώντας δεδομένα με χιλιάδες terabyte. Προσφέρει επίσης την ευελιξία της επεξεργασίας δεδομένων που μπορούν να είναι δομημένα, ημιδομημένα ή μη δομημένα και οποιασδήποτε μορφής ή μεγέθους.
Απλότητα
Μπορείτε να γράψετε προγράμματα MapReduce σε οποιαδήποτε γλώσσα προγραμματισμού όπως Java, R, Perl, Python και άλλα. Επομένως, είναι εύκολο για οποιονδήποτε να μάθει και να γράψει προγράμματα, διασφαλίζοντας παράλληλα ότι πληρούνται οι απαιτήσεις επεξεργασίας δεδομένων του.
Χρήση περιπτώσεων MapReduce
- Ευρετηρίαση πλήρους κειμένου: Το MapReduce χρησιμοποιείται για την εκτέλεση ευρετηρίασης πλήρους κειμένου. Το Mapper του μπορεί να αντιστοιχίσει κάθε λέξη ή φράση σε ένα μόνο έγγραφο. Και ο Reducer χρησιμοποιείται για την εγγραφή όλων των αντιστοιχισμένων στοιχείων σε ένα ευρετήριο.
- Υπολογισμός της κατάταξης σελίδας: Η Google χρησιμοποιεί το MapReduce για τον υπολογισμό της κατάταξης σελίδας.
- Ανάλυση αρχείων καταγραφής: Το MapReduce μπορεί να αναλύσει αρχεία καταγραφής. Μπορεί να σπάσει ένα μεγάλο αρχείο καταγραφής σε διάφορα μέρη ή να χωρίσει ενώ ο χαρτογράφος αναζητά ιστοσελίδες στις οποίες έχει πρόσβαση.
Ένα ζεύγος κλειδιού-τιμής θα τροφοδοτηθεί στον μειωτήρα εάν εντοπιστεί μια ιστοσελίδα στο αρχείο καταγραφής. Εδώ, η ιστοσελίδα θα είναι το κλειδί και το ευρετήριο “1” είναι η τιμή. Αφού δώσετε ένα ζεύγος κλειδιού-τιμής στο Reducer, θα συγκεντρωθούν διάφορες ιστοσελίδες. Το τελικό αποτέλεσμα είναι ο συνολικός αριθμός επισκέψεων για κάθε ιστοσελίδα.

- Γράφημα Αντίστροφης Σύνδεσης Ιστού: Το πλαίσιο βρίσκει επίσης χρήση στο Γράφημα Αντίστροφης Σύνδεσης Ιστού. Εδώ, το Map() αποδίδει τον στόχο URL και την πηγή και λαμβάνει δεδομένα από την πηγή ή την ιστοσελίδα.
Στη συνέχεια, η Reduce() συγκεντρώνει τη λίστα κάθε διεύθυνσης URL πηγής που σχετίζεται με τη διεύθυνση URL προορισμού. Τέλος, βγάζει τις πηγές και τον στόχο.
- Καταμέτρηση λέξεων: Το MapReduce χρησιμοποιείται για να μετρήσει πόσες φορές εμφανίζεται μια λέξη σε ένα δεδομένο έγγραφο.
- Υπερθέρμανση του πλανήτη: Οργανισμοί, κυβερνήσεις και εταιρείες μπορούν να χρησιμοποιήσουν το MapReduce για να λύσουν ζητήματα υπερθέρμανσης του πλανήτη.
Για παράδειγμα, μπορεί να θέλετε να μάθετε για το αυξημένο επίπεδο θερμοκρασίας του ωκεανού λόγω της υπερθέρμανσης του πλανήτη. Για αυτό, μπορείτε να συγκεντρώσετε χιλιάδες δεδομένα σε όλο τον κόσμο. Τα δεδομένα μπορεί να είναι υψηλή θερμοκρασία, χαμηλή θερμοκρασία, γεωγραφικό πλάτος, γεωγραφικό μήκος, ημερομηνία, ώρα κ.λπ. Αυτό θα απαιτήσει αρκετούς χάρτες και θα μειώσει τις εργασίες για τον υπολογισμό της εξόδου χρησιμοποιώντας το MapReduce.
- Δοκιμές φαρμάκων: Παραδοσιακά, επιστήμονες δεδομένων και μαθηματικοί συνεργάστηκαν για να διαμορφώσουν ένα νέο φάρμακο που μπορεί να καταπολεμήσει μια ασθένεια. Με τη διάδοση αλγορίθμων και MapReduce, τα τμήματα πληροφορικής σε οργανισμούς μπορούν εύκολα να αντιμετωπίσουν ζητήματα που χειρίζονταν μόνο οι Supercomputers, Ph.D. επιστήμονες, κ.λπ. Τώρα, μπορείτε να επιθεωρήσετε την αποτελεσματικότητα ενός φαρμάκου για μια ομάδα ασθενών.
- Άλλες εφαρμογές: Το MapReduce μπορεί να επεξεργαστεί ακόμη και δεδομένα μεγάλης κλίμακας που διαφορετικά δεν χωρούν σε μια σχεσιακή βάση δεδομένων. Χρησιμοποιεί επίσης εργαλεία επιστήμης δεδομένων και επιτρέπει την εκτέλεση τους σε διαφορετικά, κατανεμημένα σύνολα δεδομένων, κάτι που προηγουμένως ήταν δυνατό μόνο σε έναν μόνο υπολογιστή.
Ως αποτέλεσμα της ευρωστίας και της απλότητας του MapReduce, βρίσκει εφαρμογές στον στρατό, τις επιχειρήσεις, την επιστήμη κ.λπ.
συμπέρασμα
Το MapReduce μπορεί να αποδειχθεί μια σημαντική ανακάλυψη στην τεχνολογία. Δεν είναι μόνο μια ταχύτερη και απλούστερη διαδικασία, αλλά και οικονομικά αποδοτική και λιγότερο χρονοβόρα. Δεδομένων των πλεονεκτημάτων του και της αυξανόμενης χρήσης του, είναι πιθανό να γίνει μάρτυρας μεγαλύτερης υιοθέτησης σε βιομηχανίες και οργανισμούς.
Μπορείτε επίσης να εξερευνήσετε μερικούς καλύτερους πόρους για να μάθετε Big Data και Hadoop.