
Το Apache Parquet παρέχει πολλά πλεονεκτήματα για την αποθήκευση και την ανάκτηση δεδομένων σε σύγκριση με παραδοσιακές μεθόδους όπως το CSV.
Η μορφή παρκέ έχει σχεδιαστεί για ταχύτερη επεξεργασία δεδομένων πολύπλοκων τύπων. Σε αυτό το άρθρο, μιλάμε για το πώς η μορφή Parquet είναι κατάλληλη για τις σημερινές συνεχώς αυξανόμενες ανάγκες δεδομένων.
Πριν εμβαθύνουμε στις λεπτομέρειες της μορφής Parquet, ας καταλάβουμε τι είναι τα δεδομένα CSV και τις προκλήσεις που δημιουργούν για την αποθήκευση δεδομένων.
Πίνακας περιεχομένων
Τι είναι ο χώρος αποθήκευσης CSV;
Όλοι έχουμε ακούσει πολλά για το CSV (τιμές διαχωρισμένες με κόμματα) – έναν από τους πιο συνηθισμένους τρόπους οργάνωσης και μορφοποίησης δεδομένων. Η αποθήκευση δεδομένων CSV βασίζεται σε γραμμές. Τα αρχεία CSV αποθηκεύονται με επέκταση .csv. Μπορούμε να αποθηκεύσουμε και να ανοίξουμε δεδομένα CSV χρησιμοποιώντας Excel, Φύλλα Google ή οποιοδήποτε πρόγραμμα επεξεργασίας κειμένου. Τα δεδομένα είναι εύκολα ορατά μόλις ανοίξει το αρχείο.
Λοιπόν, αυτό δεν είναι καλό – σίγουρα όχι για μια μορφή βάσης δεδομένων.
Επιπλέον, καθώς ο όγκος των δεδομένων αυξάνεται, καθίσταται δύσκολο να αναζητήσετε, να διαχειριστείτε και να ανακτήσετε.
Ακολουθεί ένα παράδειγμα δεδομένων που είναι αποθηκευμένα σε αρχείο .CSV:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
Αν το δούμε στο Excel, μπορούμε να δούμε μια δομή γραμμής-στήλης όπως παρακάτω:
Προκλήσεις με την αποθήκευση CSV
Οι αποθηκευτικοί χώροι που βασίζονται σε γραμμές, όπως το CSV, είναι κατάλληλοι για λειτουργίες δημιουργίας, ενημέρωσης και διαγραφής.
Τι γίνεται λοιπόν με το Read in CRUD;
Φανταστείτε ένα εκατομμύριο σειρές στο παραπάνω αρχείο .csv. Θα χρειαζόταν εύλογο χρονικό διάστημα για να ανοίξετε το αρχείο και να αναζητήσετε τα δεδομένα που αναζητάτε. Όχι τόσο κουλ. Οι περισσότεροι πάροχοι cloud, όπως το AWS, χρεώνουν τις εταιρείες με βάση τον όγκο των δεδομένων που σαρώνονται ή αποθηκεύονται – και πάλι, τα αρχεία CSV καταναλώνουν πολύ χώρο.
Ο χώρος αποθήκευσης CSV δεν έχει αποκλειστική επιλογή αποθήκευσης μεταδεδομένων, καθιστώντας τη σάρωση δεδομένων μια κουραστική εργασία.
Λοιπόν, ποια είναι η οικονομικά αποδοτική και βέλτιστη λύση για την εκτέλεση όλων των λειτουργιών CRUD; Ας εξερευνήσουμε.
Τι είναι η αποθήκευση δεδομένων Parquet;
Παρκέ είναι μια μορφή αποθήκευσης ανοιχτού κώδικα για την αποθήκευση δεδομένων. Χρησιμοποιείται ευρέως στα οικοσυστήματα Hadoop και Spark. Τα αρχεία παρκέ αποθηκεύονται ως επέκταση .parquet.
Το παρκέ είναι μια πολύ δομημένη μορφή. Μπορεί επίσης να χρησιμοποιηθεί για τη βελτιστοποίηση σύνθετων ακατέργαστων δεδομένων που υπάρχουν χύμα σε λίμνες δεδομένων. Αυτό μπορεί να μειώσει σημαντικά τον χρόνο αναζήτησης.
Το παρκέ κάνει την αποθήκευση δεδομένων αποτελεσματική και την ανάκτηση ταχύτερη λόγω ενός συνδυασμού μορφών αποθήκευσης βάσει σειρών και στηλών (υβριδική). Σε αυτή τη μορφή, τα δεδομένα κατανέμονται οριζόντια και κάθετα. Η μορφή παρκέ εξαλείφει επίσης σε μεγάλο βαθμό την επιβάρυνση της ανάλυσης.
Η μορφή περιορίζει τον συνολικό αριθμό των λειτουργιών I/O και, τελικά, το κόστος.
Το Parquet αποθηκεύει επίσης τα μεταδεδομένα, τα οποία αποθηκεύουν πληροφορίες σχετικά με δεδομένα όπως το σχήμα δεδομένων, ο αριθμός των τιμών, η θέση των στηλών, η ελάχιστη τιμή, η μέγιστη τιμή του αριθμού των ομάδων σειρών, ο τύπος κωδικοποίησης κ.λπ. Τα μεταδεδομένα αποθηκεύονται σε διαφορετικά επίπεδα στο αρχείο , καθιστώντας ταχύτερη την πρόσβαση στα δεδομένα.
Στην πρόσβαση που βασίζεται σε γραμμές, όπως το CSV, η ανάκτηση δεδομένων απαιτεί χρόνο, καθώς το ερώτημα πρέπει να περιηγηθεί σε κάθε σειρά και να λάβει τις συγκεκριμένες τιμές στήλης. Με την αποθήκευση παρκέ, μπορείτε να έχετε πρόσβαση σε όλες τις απαιτούμενες στήλες ταυτόχρονα.
Συνοψίζοντας,
- Το παρκέ βασίζεται στη δομή στηλών για αποθήκευση δεδομένων
- Είναι μια βελτιστοποιημένη μορφή δεδομένων για την αποθήκευση σύνθετων δεδομένων μαζικά σε συστήματα αποθήκευσης
- Η μορφή παρκέ περιλαμβάνει διάφορες μεθόδους συμπίεσης και κωδικοποίησης δεδομένων
- Μειώνει σημαντικά τον χρόνο σάρωσης δεδομένων και τον χρόνο ερωτήματος και καταλαμβάνει λιγότερο χώρο στο δίσκο σε σύγκριση με άλλες μορφές αποθήκευσης όπως το CSV
- Ελαχιστοποιεί τον αριθμό των λειτουργιών IO, μειώνοντας το κόστος αποθήκευσης και εκτέλεσης ερωτημάτων
- Περιλαμβάνει μεταδεδομένα που διευκολύνουν την εύρεση δεδομένων
- Παρέχει υποστήριξη ανοιχτού κώδικα
Μορφή δεδομένων παρκέ
Πριν προχωρήσουμε σε ένα παράδειγμα, ας καταλάβουμε πώς αποθηκεύονται τα δεδομένα σε μορφή Parquet με περισσότερες λεπτομέρειες:
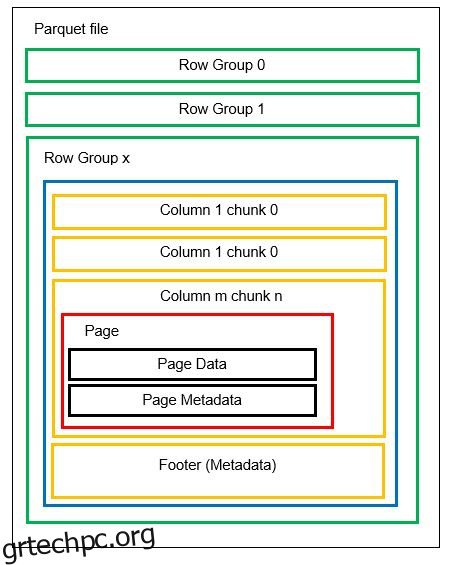
Μπορούμε να έχουμε πολλά οριζόντια διαμερίσματα γνωστά ως ομάδες σειρών σε ένα αρχείο. Σε κάθε ομάδα γραμμών, εφαρμόζεται κάθετη κατάτμηση. Οι στήλες χωρίζονται σε πολλά κομμάτια στηλών. Τα δεδομένα αποθηκεύονται ως σελίδες μέσα στα κομμάτια της στήλης. Κάθε σελίδα περιέχει τις κωδικοποιημένες τιμές δεδομένων και τα μεταδεδομένα. Όπως αναφέραμε προηγουμένως, τα μεταδεδομένα για ολόκληρο το αρχείο αποθηκεύονται επίσης στο υποσέλιδο του αρχείου σε επίπεδο ομάδας Γραμμών.
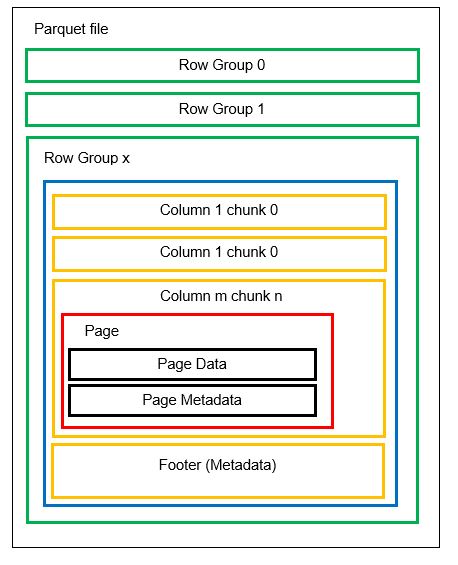
Καθώς τα δεδομένα χωρίζονται σε κομμάτια στηλών, η προσθήκη νέων δεδομένων με την κωδικοποίηση των νέων τιμών σε ένα νέο κομμάτι και αρχείο είναι επίσης εύκολη. Στη συνέχεια, τα μεταδεδομένα ενημερώνονται για τα επηρεαζόμενα αρχεία και τις ομάδες σειρών. Έτσι, μπορούμε να πούμε ότι το παρκέ είναι μια ευέλικτη μορφή.
Το Parquet υποστηρίζει εγγενώς τη συμπίεση δεδομένων χρησιμοποιώντας τεχνικές συμπίεσης σελίδας και κωδικοποίησης λεξικών. Ας δούμε ένα απλό παράδειγμα συμπίεσης λεξικού:
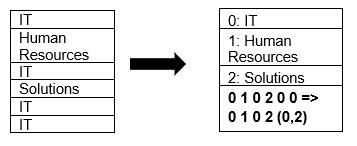
Σημειώστε ότι στο παραπάνω παράδειγμα, βλέπουμε τη διαίρεση IT 4 φορές. Έτσι, κατά την αποθήκευση στο λεξικό, η μορφή κωδικοποιεί τα δεδομένα με μια άλλη τιμή εύκολης αποθήκευσης (0,1,2…) μαζί με τον αριθμό των φορών που επαναλαμβάνεται συνεχώς – IT, IT αλλάζει σε 0,2 για αποθήκευση περισσότερος χώρος. Η αναζήτηση συμπιεσμένων δεδομένων απαιτεί λιγότερο χρόνο.
Σύγκριση κατά πρόσωπο
Τώρα που έχουμε μια δίκαιη ιδέα για το πώς μοιάζουν οι μορφές CSV και Parquet, ήρθε η ώρα για ορισμένα στατιστικά στοιχεία να συγκρίνουμε και τις δύο μορφές:
CSV
Παρκέ
Μορφή αποθήκευσης βάσει σειράς.
Ένα υβρίδιο μορφών αποθήκευσης που βασίζονται σε γραμμές και σε στήλες.
Καταναλώνει πολύ χώρο καθώς δεν είναι διαθέσιμη προεπιλεγμένη επιλογή συμπίεσης. Για παράδειγμα, ένα αρχείο 1 TB θα καταλαμβάνει τον ίδιο χώρο όταν αποθηκεύεται στο Amazon S3 ή σε οποιοδήποτε άλλο cloud.
Συμπιέζει δεδομένα κατά την αποθήκευση, καταναλώνοντας έτσι λιγότερο χώρο. Ένα αρχείο 1 TB που είναι αποθηκευμένο σε μορφή Parquet θα καταλαμβάνει μόνο 130 GB χώρου.
Ο χρόνος εκτέλεσης του ερωτήματος είναι αργός λόγω της αναζήτησης που βασίζεται σε σειρές. Για κάθε στήλη, κάθε σειρά δεδομένων πρέπει να ανακτηθεί.
Ο χρόνος ερωτήματος είναι περίπου 34 φορές ταχύτερος λόγω της αποθήκευσης βάσει στήλης και της παρουσίας μεταδεδομένων.
Πρέπει να σαρωθούν περισσότερα δεδομένα ανά ερώτημα.
Περίπου 99% λιγότερα δεδομένα σαρώνονται για την εκτέλεση του ερωτήματος, βελτιστοποιώντας έτσι την απόδοση.
Οι περισσότερες συσκευές αποθήκευσης χρεώνουν με βάση τον αποθηκευτικό χώρο, επομένως η μορφή CSV σημαίνει υψηλό κόστος αποθήκευσης.
Λιγότερο κόστος αποθήκευσης καθώς τα δεδομένα αποθηκεύονται σε συμπιεσμένη, κωδικοποιημένη μορφή.
Το σχήμα αρχείου πρέπει είτε να συμπεραίνεται (που οδηγεί σε σφάλματα) είτε να παρέχεται (κουραστικό).
Το σχήμα αρχείου αποθηκεύεται στα μεταδεδομένα.
Η μορφή είναι κατάλληλη για απλούς τύπους δεδομένων.
Το παρκέ είναι κατάλληλο ακόμη και για πολύπλοκους τύπους όπως ένθετα σχήματα, συστοιχίες, λεξικά.
Συμπέρασμα 👩💻
Έχουμε δει μέσα από παραδείγματα ότι το παρκέ είναι πιο αποτελεσματικό από το CSV όσον αφορά το κόστος, την ευελιξία και την απόδοση. Είναι ένας αποτελεσματικός μηχανισμός για την αποθήκευση και την ανάκτηση δεδομένων, ειδικά όταν ολόκληρος ο κόσμος κινείται προς την αποθήκευση cloud και τη βελτιστοποίηση του χώρου. Όλες οι μεγάλες πλατφόρμες όπως το Azure, το AWS και το BigQuery υποστηρίζουν τη μορφή Parquet.