
Η εξαγωγή δεδομένων είναι η διαδικασία συλλογής συγκεκριμένων δεδομένων από ιστοσελίδες. Οι χρήστες μπορούν να εξαγάγουν κείμενο, εικόνες, βίντεο, κριτικές, προϊόντα κ.λπ. Μπορείτε να εξαγάγετε δεδομένα για να πραγματοποιήσετε έρευνα αγοράς, ανάλυση συναισθήματος, ανταγωνιστική ανάλυση και συγκεντρωτικά δεδομένα.
Εάν έχετε να κάνετε με μικρό όγκο δεδομένων, μπορείτε να εξαγάγετε δεδομένα με μη αυτόματο τρόπο, επικολλώντας τις συγκεκριμένες πληροφορίες από ιστοσελίδες σε ένα υπολογιστικό φύλλο ή μια μορφή εγγράφου της αρεσκείας σας. Για παράδειγμα, εάν, ως πελάτης, αναζητάτε κριτικές στο διαδίκτυο για να σας βοηθήσουν να πάρετε μια απόφαση αγοράς, μπορείτε να διαγράψετε δεδομένα με μη αυτόματο τρόπο.
Από την άλλη πλευρά, εάν έχετε να κάνετε με μεγάλα σύνολα δεδομένων, χρειάζεστε μια αυτοματοποιημένη τεχνική εξαγωγής δεδομένων. Μπορείτε να δημιουργήσετε μια εσωτερική λύση εξαγωγής δεδομένων ή να χρησιμοποιήσετε το Proxy API ή το Scraping API για τέτοιες εργασίες.
Ωστόσο, αυτές οι τεχνικές μπορεί να είναι λιγότερο αποτελεσματικές καθώς ορισμένοι από τους ιστότοπους που στοχεύετε ενδέχεται να προστατεύονται από captchas. Μπορεί επίσης να χρειαστεί να διαχειριστείτε bots και proxies. Τέτοιες εργασίες μπορεί να χρειαστούν μεγάλο μέρος του χρόνου σας και να περιορίσουν τη φύση του περιεχομένου που μπορείτε να εξαγάγετε.
Πίνακας περιεχομένων
Scraping Browser: The Solution
Μπορείτε να ξεπεράσετε όλες αυτές τις προκλήσεις μέσω του Scraping Browser by Bright Data. Αυτό το πρόγραμμα περιήγησης all-in-one βοηθά στη συλλογή δεδομένων από ιστότοπους που είναι δύσκολο να κοπούν. Είναι ένα πρόγραμμα περιήγησης που χρησιμοποιεί μια γραφική διεπαφή χρήστη (GUI) και ελέγχεται από το Puppeteer ή το Playwright API, καθιστώντας το μη ανιχνεύσιμο από bots.
Το Scraping Browser έχει ενσωματωμένες λειτουργίες ξεκλειδώματος που χειρίζονται αυτόματα όλα τα μπλοκ για λογαριασμό σας. Το πρόγραμμα περιήγησης ανοίγει στους διακομιστές της Bright Data, πράγμα που σημαίνει ότι δεν χρειάζεστε ακριβή εσωτερική υποδομή για να διαγράψετε δεδομένα για τα έργα μεγάλης κλίμακας.
Χαρακτηριστικά του προγράμματος περιήγησης Bright Data Scraping
- Αυτόματο ξεκλείδωμα ιστότοπου: Δεν χρειάζεται να συνεχίσετε να ανανεώνετε το πρόγραμμα περιήγησής σας, καθώς αυτό το πρόγραμμα περιήγησης προσαρμόζεται αυτόματα για να χειρίζεται την επίλυση CAPTCHA, τα νέα μπλοκ, τα δακτυλικά αποτυπώματα και τις επαναλήψεις. Το Scraping Browser μιμείται έναν πραγματικό χρήστη.
- Ένα μεγάλο δίκτυο μεσολάβησης: Μπορείτε να στοχεύσετε οποιαδήποτε χώρα θέλετε, καθώς το Scraping Browser έχει πάνω από 72 εκατομμύρια IP. Μπορείτε να στοχεύσετε πόλεις ή ακόμα και εταιρείες και να επωφεληθείτε από την καλύτερη τεχνολογία στην κατηγορία.
- Scalable: Μπορείτε να ανοίξετε χιλιάδες περιόδους σύνδεσης ταυτόχρονα καθώς αυτό το πρόγραμμα περιήγησης χρησιμοποιεί την υποδομή Bright Data για να χειριστεί όλα τα αιτήματα.
- Συμβατό με Puppeteer και Playwright: Αυτό το πρόγραμμα περιήγησης σάς επιτρέπει να πραγματοποιείτε κλήσεις API και να λαμβάνετε οποιονδήποτε αριθμό περιόδων λειτουργίας προγράμματος περιήγησης είτε χρησιμοποιώντας το Puppeteer (Python) είτε το Playwright (Node.js).
- Εξοικονομεί χρόνο και πόρους: Αντί να ρυθμίζει διακομιστές μεσολάβησης, το πρόγραμμα περιήγησης Scraping φροντίζει τα πάντα στο παρασκήνιο. Επίσης, δεν χρειάζεται να δημιουργήσετε εσωτερική υποδομή, καθώς αυτό το εργαλείο φροντίζει τα πάντα στο παρασκήνιο.
Πώς να ρυθμίσετε το πρόγραμμα περιήγησης Scraping
- Μεταβείτε στον ιστότοπο Bright Data και κάντε κλικ στο Scraping Browser στην καρτέλα “Scraping Solutions”.
- Δημιουργία λογαριασμού. Θα δείτε δύο επιλογές. “Έναρξη δωρεάν δοκιμής” και “Ξεκινήστε δωρεάν με την Google”. Ας επιλέξουμε “Έναρξη δωρεάν δοκιμής” προς το παρόν και ας προχωρήσουμε στο επόμενο βήμα. Μπορείτε είτε να δημιουργήσετε τον λογαριασμό μη αυτόματα είτε να χρησιμοποιήσετε τον λογαριασμό σας Google.
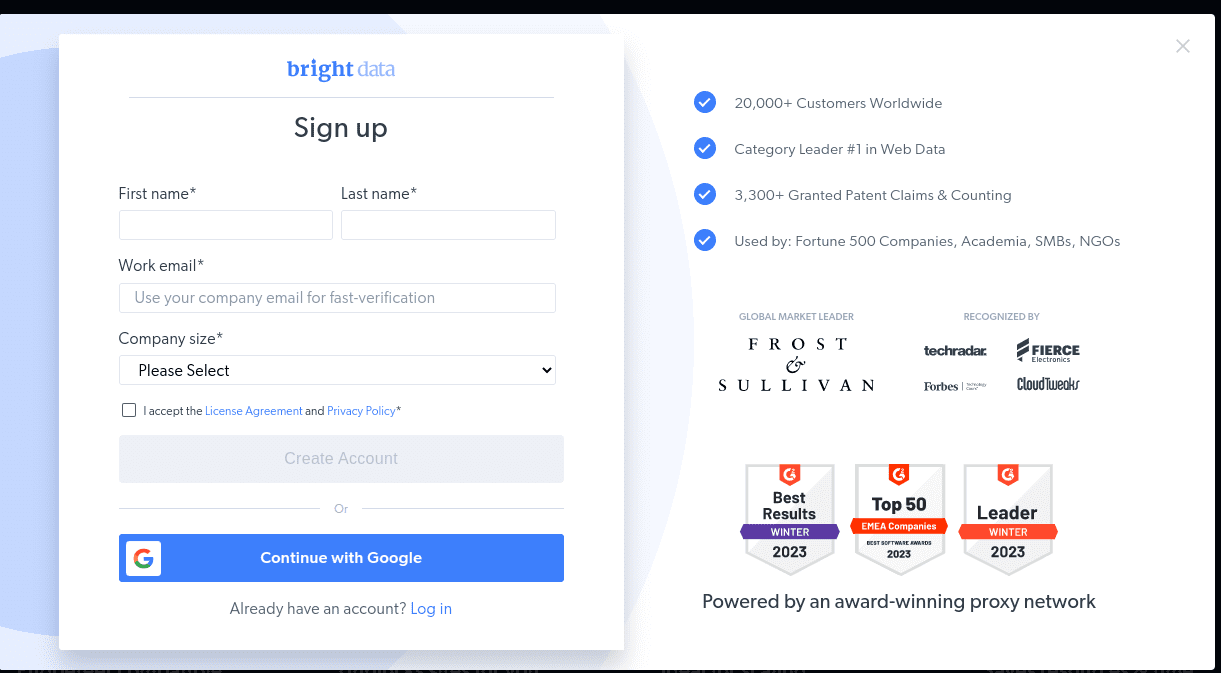
- Όταν δημιουργηθεί ο λογαριασμός σας, ο πίνακας ελέγχου θα εμφανίσει πολλές επιλογές. Επιλέξτε “Proxies & Scraping Infrastructure”.
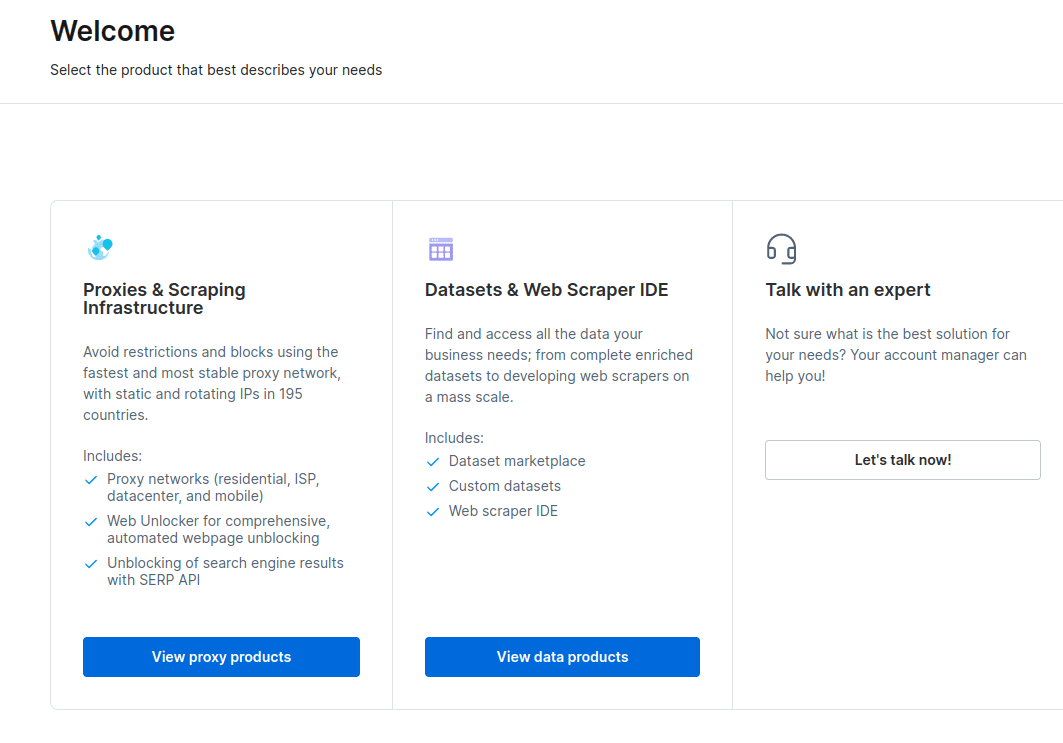
- Στο νέο παράθυρο που ανοίγει, επιλέξτε Scraping Browser και κάντε κλικ στο «Έναρξη».
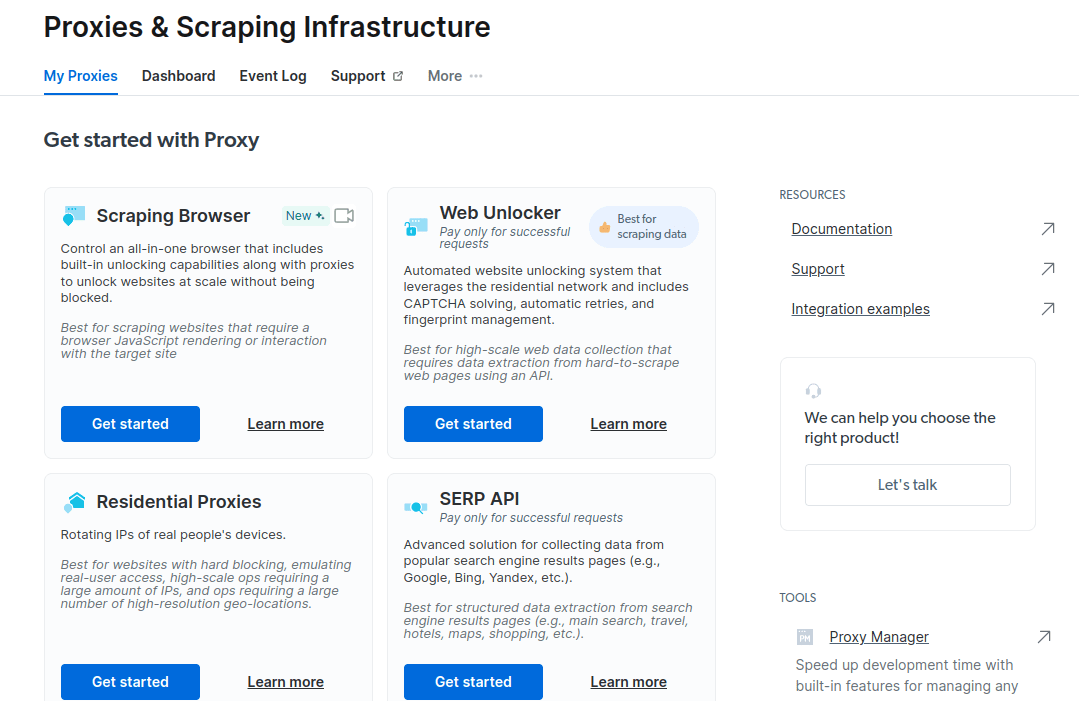
- Αποθηκεύστε και ενεργοποιήστε τις διαμορφώσεις σας.
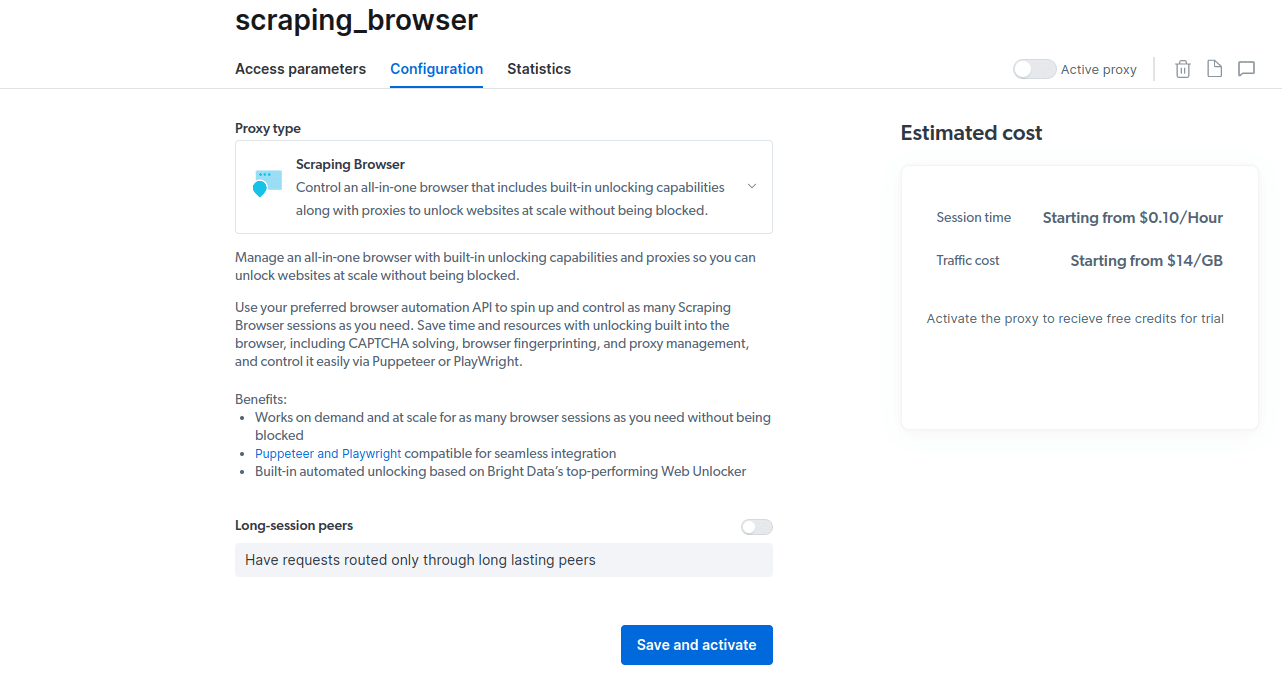
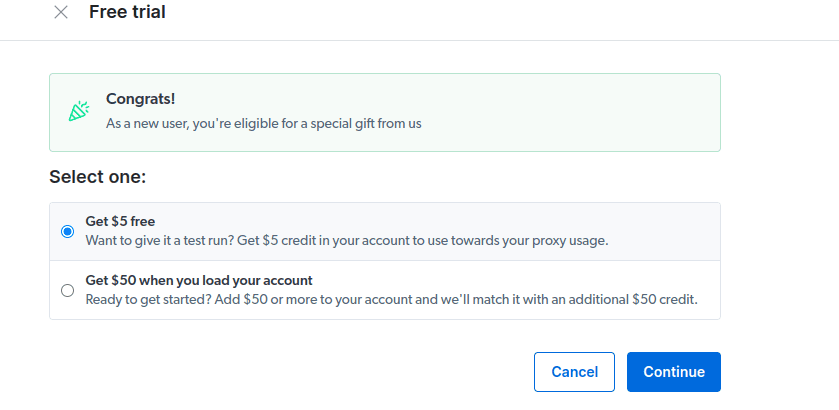
- Ενεργοποιήστε τη δωρεάν δοκιμή σας. Η πρώτη επιλογή σάς δίνει μια πίστωση 5 $ που μπορείτε να χρησιμοποιήσετε για τη χρήση του διακομιστή μεσολάβησης. Κάντε κλικ στην πρώτη επιλογή για να δοκιμάσετε αυτό το προϊόν. Ωστόσο, εάν είστε βαρύς χρήστης, μπορείτε να κάνετε κλικ στη δεύτερη επιλογή που σας δίνει 50 $ δωρεάν εάν φορτώσετε τον λογαριασμό σας με 50 $ ή περισσότερα.
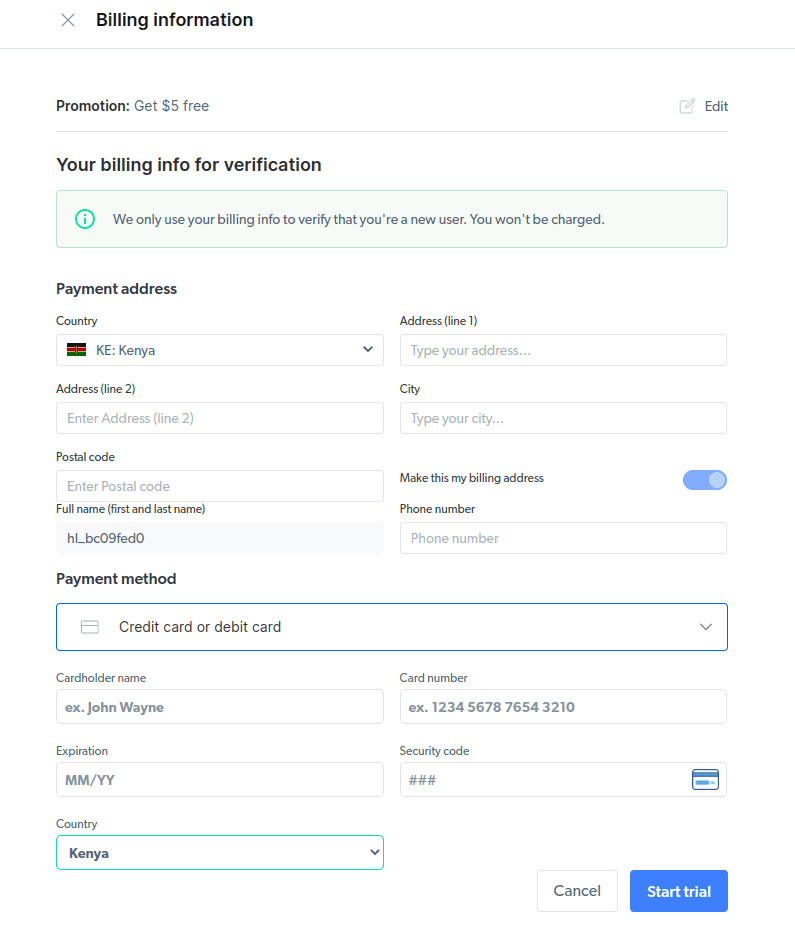
- Εισαγάγετε τα στοιχεία χρέωσής σας. Μην ανησυχείτε, καθώς η πλατφόρμα δεν θα σας χρεώσει τίποτα. Τα στοιχεία χρέωσης απλώς επαληθεύουν ότι είστε νέος χρήστης και δεν αναζητάτε δωρεάν άδειες δημιουργώντας πολλούς λογαριασμούς.
- Δημιουργήστε ένα νέο διακομιστή μεσολάβησης. Αφού αποθηκεύσετε τα στοιχεία χρέωσής σας, μπορείτε να δημιουργήσετε έναν νέο διακομιστή μεσολάβησης. Κάντε κλικ στο εικονίδιο “προσθήκη” και επιλέξτε Scraping Browser ως “Τύπος διακομιστή μεσολάβησης”. Κάντε κλικ στο «Προσθήκη διακομιστή μεσολάβησης» και προχωρήστε στο επόμενο βήμα.
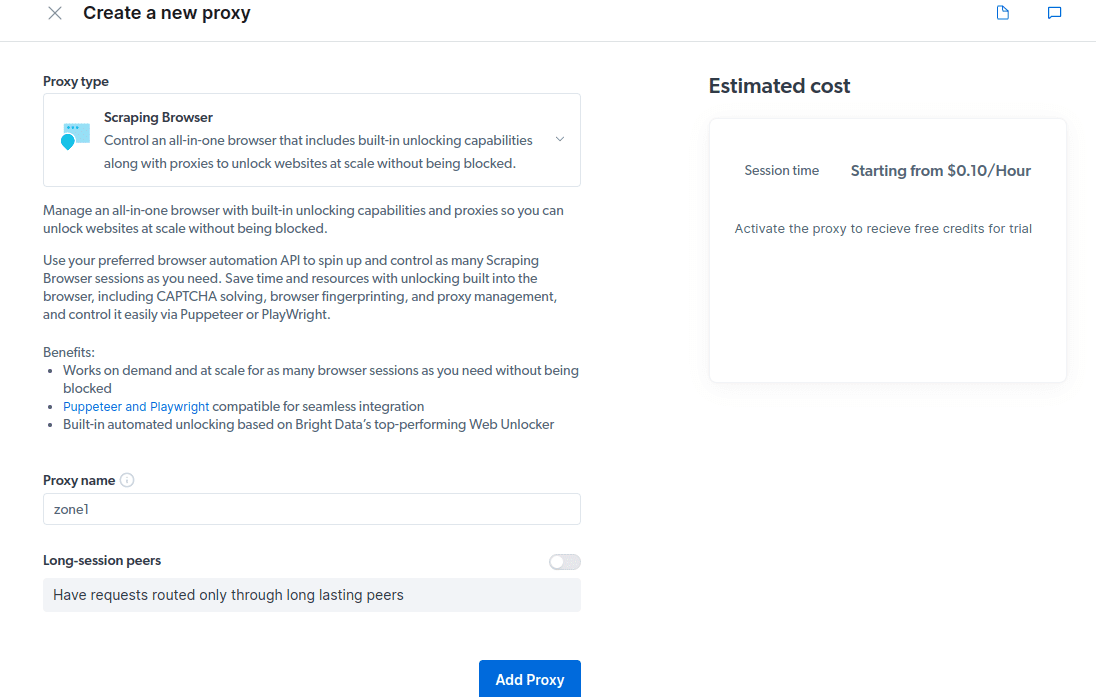
- Δημιουργήστε μια νέα «ζώνη». Θα εμφανιστεί ένα αναδυόμενο μήνυμα που θα σας ρωτά εάν θέλετε να δημιουργήσετε μια νέα Ζώνη. κάντε κλικ στο «Ναι» και συνεχίστε.
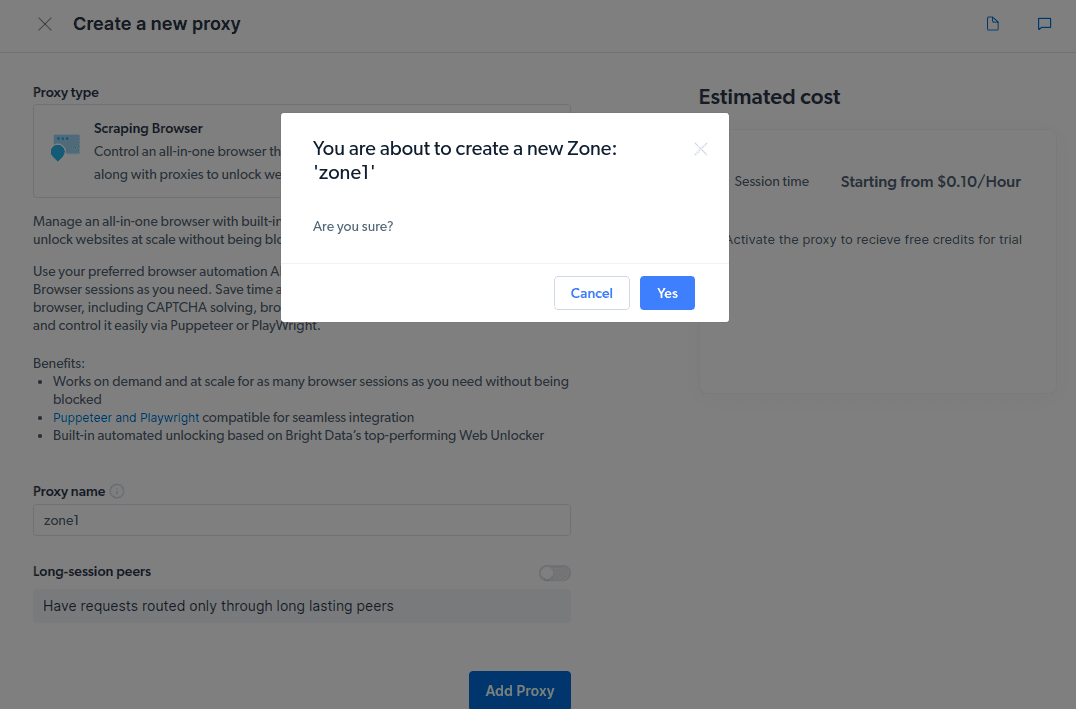
- Κάντε κλικ στο «Έλεγχος παραδειγμάτων κώδικα και ενοποίησης». Τώρα θα λάβετε παραδείγματα ενοποίησης διακομιστή μεσολάβησης που μπορείτε να χρησιμοποιήσετε για να αφαιρέσετε δεδομένα από τον ιστότοπο-στόχο σας. Μπορείτε να χρησιμοποιήσετε το Node.js ή την Python για να εξαγάγετε δεδομένα από τον ιστότοπο-στόχο σας.
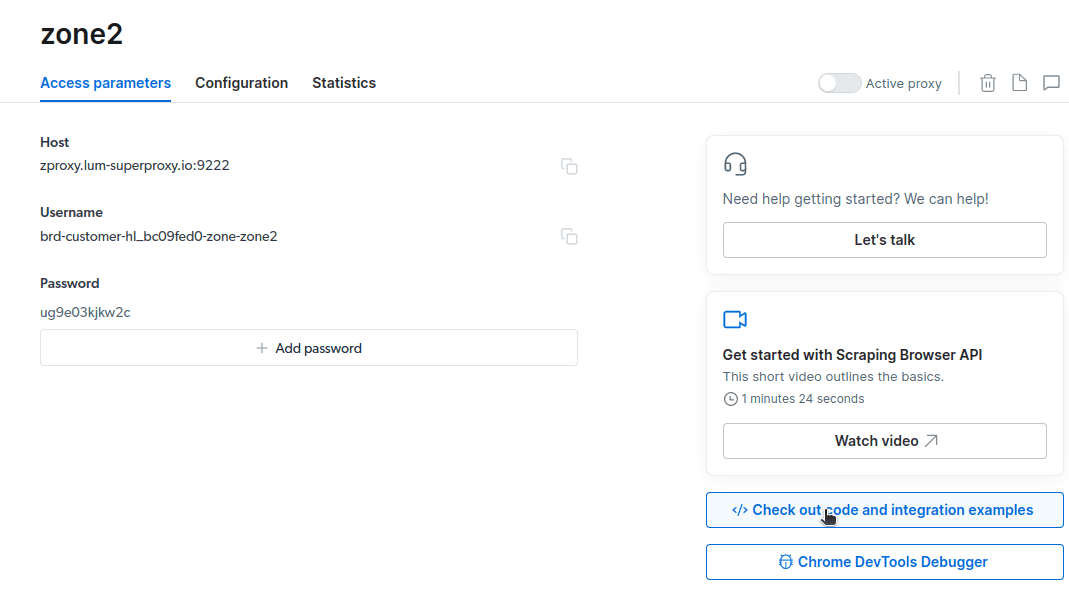
Τώρα έχετε όλα όσα χρειάζεστε για να εξαγάγετε δεδομένα από έναν ιστότοπο. Θα χρησιμοποιήσουμε τον ιστότοπό μας, grtechpc.org.com, για να δείξουμε πώς λειτουργεί το Scraping Browser. Για αυτήν την επίδειξη, θα χρησιμοποιήσουμε το node.js. Μπορείτε να ακολουθήσετε εάν έχετε εγκαταστήσει το node.js.
Ακολουθήστε αυτά τα βήματα;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
Θα αλλάξω τον κωδικό μου στη γραμμή 10 ως εξής.
await page.goto(‘https://grtechpc.org.com/authors/‘);
Ο τελικός μου κωδικός τώρα θα είναι?
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://grtechpc.org.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
node script.js
Θα έχετε κάτι τέτοιο στο τερματικό σας
Πώς να εξάγετε τα δεδομένα
Μπορείτε να χρησιμοποιήσετε διάφορες προσεγγίσεις για την εξαγωγή των δεδομένων, ανάλογα με τον τρόπο που σκοπεύετε να τα χρησιμοποιήσετε. Σήμερα, μπορούμε να εξάγουμε τα δεδομένα σε ένα αρχείο html αλλάζοντας το σενάριο για να δημιουργήσουμε ένα νέο αρχείο με το όνομα data.html αντί να το εκτυπώσουμε στην κονσόλα.
Μπορείτε να αλλάξετε τα περιεχόμενα του κώδικά σας ως εξής.
const puppeteer = require('puppeteer-core');
const fs = require('fs');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://grtechpc.org.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
// Write HTML content to a file
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
Τώρα μπορείτε να εκτελέσετε τον κώδικα χρησιμοποιώντας αυτήν την εντολή.
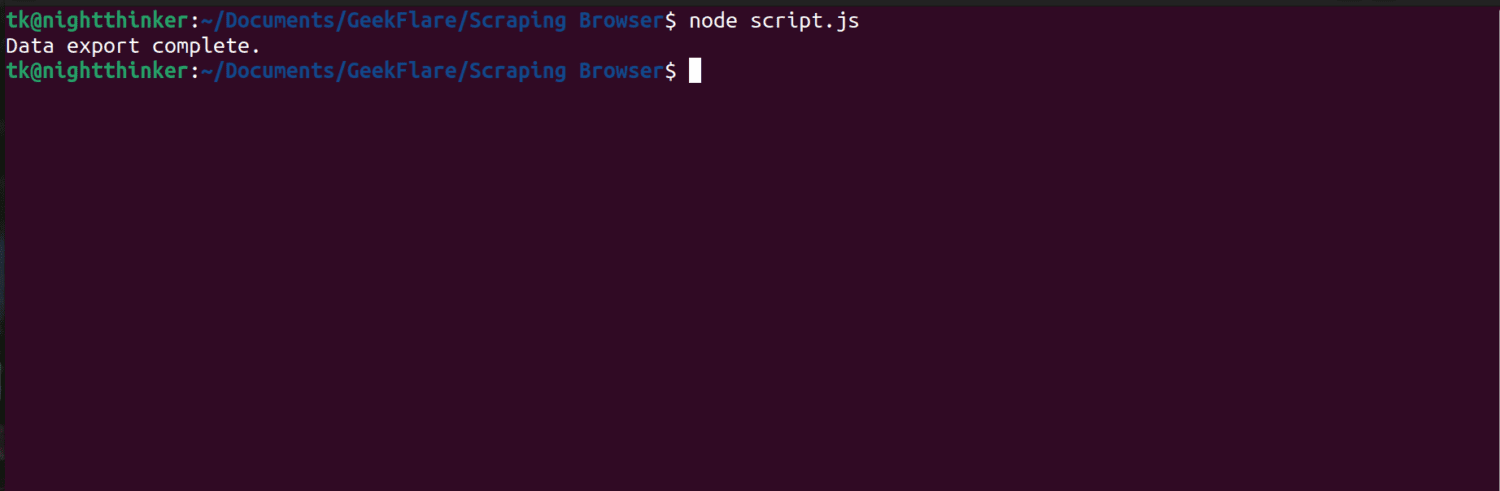
node script.js
Όπως μπορείτε να δείτε στο παρακάτω στιγμιότυπο οθόνης, το τερματικό εμφανίζει ένα μήνυμα που λέει “η εξαγωγή δεδομένων ολοκληρώθηκε”.
Εάν ελέγξουμε το φάκελο του έργου μας, μπορούμε τώρα να δούμε ένα αρχείο με το όνομα data.html με χιλιάδες γραμμές κώδικα.
Μόλις γρατσούνισα την επιφάνεια του τρόπου εξαγωγής δεδομένων χρησιμοποιώντας το πρόγραμμα περιήγησης Scraping. Μπορώ ακόμη και να περιορίσω και να διαγράψω μόνο τα ονόματα των συγγραφέων και τις περιγραφές τους χρησιμοποιώντας αυτό το εργαλείο.
Εάν θέλετε να χρησιμοποιήσετε το πρόγραμμα περιήγησης Scraping, προσδιορίστε τα σύνολα δεδομένων που θέλετε να εξαγάγετε και τροποποιήστε τον κώδικα ανάλογα. Μπορείτε να εξαγάγετε κείμενο, εικόνες, βίντεο, μεταδεδομένα και συνδέσμους, ανάλογα με τον ιστότοπο που στοχεύετε και τη δομή του αρχείου HTML.
Συχνές ερωτήσεις
Είναι νόμιμη η εξαγωγή δεδομένων και η απόξεση ιστού;
Η απόξεση ιστού είναι ένα αμφιλεγόμενο θέμα, με μια ομάδα να λέει ότι είναι ανήθικο ενώ άλλες πιστεύουν ότι είναι εντάξει. Η νομιμότητα της απόξεσης ιστού θα εξαρτηθεί από τη φύση του περιεχομένου που αποσύρεται και την πολιτική της ιστοσελίδας-στόχου.
Γενικά, η απόξεση δεδομένων με προσωπικές πληροφορίες, όπως διευθύνσεις και οικονομικά στοιχεία, θεωρείται παράνομη. Προτού διαγράψετε δεδομένα, ελέγξτε εάν ο ιστότοπος που στοχεύετε έχει οδηγίες. Βεβαιωθείτε πάντα ότι δεν διαγράφετε δεδομένα που δεν είναι δημόσια διαθέσιμα.
Είναι το Scraping Browser ένα δωρεάν εργαλείο;
Όχι. Το Scraping Browser είναι μια υπηρεσία επί πληρωμή. Εάν εγγραφείτε για μια δωρεάν δοκιμή, το εργαλείο σας δίνει πίστωση 5 $. Τα επί πληρωμή πακέτα ξεκινούν από 15 $/GB + 0,1 $/ώρα. Μπορείτε επίσης να επιλέξετε την επιλογή Pay As You Go που ξεκινά από 20 $/GB + 0,1 $/ώρα.
Ποια είναι η διαφορά μεταξύ των προγραμμάτων περιήγησης Scraping και των προγραμμάτων περιήγησης χωρίς κεφάλι;
Το Scraping Browser είναι ένα πρόγραμμα περιήγησης με κεφαλές, που σημαίνει ότι διαθέτει γραφική διεπαφή χρήστη (GUI). Από την άλλη πλευρά, τα προγράμματα περιήγησης χωρίς κεφαλή δεν έχουν γραφική διεπαφή. Τα προγράμματα περιήγησης χωρίς κεφαλή, όπως το Selenium, χρησιμοποιούνται για την αυτοματοποίηση της απόξεσης ιστού, αλλά μερικές φορές είναι περιορισμένα, καθώς πρέπει να αντιμετωπίσουν CAPTCHA και εντοπισμό ρομπότ.
Τυλίγοντας
Όπως μπορείτε να δείτε, το Scraping Browser απλοποιεί την εξαγωγή δεδομένων από ιστοσελίδες. Το Scraping Browser είναι απλό στη χρήση σε σύγκριση με εργαλεία όπως το Selenium. Ακόμη και μη προγραμματιστές μπορούν να χρησιμοποιήσουν αυτό το πρόγραμμα περιήγησης με εκπληκτικό περιβάλλον χρήστη και καλή τεκμηρίωση. Το εργαλείο έχει δυνατότητες ξεμπλοκαρίσματος που δεν είναι διαθέσιμες σε άλλα εργαλεία διάλυσης, καθιστώντας το αποτελεσματικό για όλους όσους θέλουν να αυτοματοποιήσουν τέτοιες διαδικασίες.
Μπορείτε επίσης να εξερευνήσετε πώς να σταματήσετε τις προσθήκες ChatGPT να αποκόπτουν το περιεχόμενο του ιστότοπού σας.