

Τα δεδομένα αποτελούν αναπόσπαστο μέρος των επιχειρήσεων και των οργανισμών και είναι πολύτιμα μόνο όταν δομούνται σωστά και διαχειρίζονται αποτελεσματικά.
Σύμφωνα με μια στατιστική, το 95% των επιχειρήσεων σήμερα βρίσκουν πρόβλημα τη διαχείριση και τη διάρθρωση μη δομημένων δεδομένων.
Εδώ μπαίνει η εξόρυξη δεδομένων. Είναι η διαδικασία ανακάλυψης, ανάλυσης και εξαγωγής σημαντικών προτύπων και πολύτιμων πληροφοριών από μεγάλα σύνολα μη δομημένων δεδομένων.
Οι εταιρείες χρησιμοποιούν λογισμικό για να προσδιορίσουν μοτίβα σε μεγάλες παρτίδες δεδομένων για να μάθουν περισσότερα για τους πελάτες και το κοινό-στόχο τους και να αναπτύξουν επιχειρηματικές στρατηγικές και στρατηγικές μάρκετινγκ για τη βελτίωση των πωλήσεων και τη μείωση του κόστους.
Εκτός από αυτό το όφελος, η απάτη και ο εντοπισμός ανωμαλιών είναι οι πιο σημαντικές εφαρμογές της εξόρυξης δεδομένων.
Αυτό το άρθρο εξηγεί τον εντοπισμό ανωμαλιών και διερευνά περαιτέρω πώς μπορεί να βοηθήσει στην αποφυγή παραβιάσεων δεδομένων και εισβολών στο δίκτυο για να διασφαλιστεί η ασφάλεια των δεδομένων.
Πίνακας περιεχομένων
Τι είναι η ανίχνευση ανωμαλιών και τα είδη της;
Ενώ η εξόρυξη δεδομένων περιλαμβάνει την εύρεση μοτίβων, συσχετισμών και τάσεων που συνδέονται μεταξύ τους, είναι ένας πολύ καλός τρόπος για να βρείτε ανωμαλίες ή ακραία σημεία δεδομένων μέσα στο δίκτυο.
Οι ανωμαλίες στην εξόρυξη δεδομένων είναι σημεία δεδομένων που διαφέρουν από άλλα σημεία δεδομένων στο σύνολο δεδομένων και αποκλίνουν από το κανονικό πρότυπο συμπεριφοράς του συνόλου δεδομένων.
Οι ανωμαλίες μπορούν να ταξινομηθούν σε διακριτούς τύπους και κατηγορίες, όπως:
- Αλλαγές σε συμβάντα: Ανατρέξτε σε ξαφνικές ή συστηματικές αλλαγές από την προηγούμενη κανονική συμπεριφορά.
- Outliers: Μικρά ανώμαλα μοτίβα που εμφανίζονται με μη συστηματικό τρόπο στη συλλογή δεδομένων. Αυτά μπορούν να ταξινομηθούν περαιτέρω σε παγκόσμιες, συμφραζόμενες και συλλογικές ακραίες τιμές.
- Μετατοπίσεις: Σταδιακή, μη κατευθυντική και μακροπρόθεσμη αλλαγή στο σύνολο δεδομένων.
Έτσι, η ανίχνευση ανωμαλιών είναι μια τεχνική επεξεργασίας δεδομένων εξαιρετικά χρήσιμη για τον εντοπισμό δόλιων συναλλαγών, τον χειρισμό περιπτώσεων με ανισορροπία υψηλής κατηγορίας και τον εντοπισμό ασθενειών για τη δημιουργία ισχυρών μοντέλων επιστήμης δεδομένων.
Για παράδειγμα, μια εταιρεία μπορεί να θέλει να αναλύσει τις ταμειακές της ροές για να βρει μη φυσιολογικές ή επαναλαμβανόμενες συναλλαγές σε άγνωστο τραπεζικό λογαριασμό για να εντοπίσει απάτη και να διεξαγάγει περαιτέρω έρευνα.
Οφέλη από τον εντοπισμό ανωμαλιών
Ο εντοπισμός ανωμαλιών συμπεριφοράς χρήστη συμβάλλει στην ενίσχυση των συστημάτων ασφαλείας και τα καθιστά πιο ακριβή και ακριβή.
Αναλύει και κατανοεί τις ποικίλες πληροφορίες που παρέχουν τα συστήματα ασφαλείας για τον εντοπισμό απειλών και πιθανών κινδύνων εντός του δικτύου.
Ακολουθούν τα πλεονεκτήματα της ανίχνευσης ανωμαλιών για τις εταιρείες:
- Ανίχνευση απειλών στον κυβερνοχώρο και παραβιάσεις δεδομένων σε πραγματικό χρόνο, καθώς οι αλγόριθμοι τεχνητής νοημοσύνης (AI) σαρώνουν συνεχώς τα δεδομένα σας για να εντοπίσουν ασυνήθιστη συμπεριφορά.
- Κάνει την παρακολούθηση ανώμαλων δραστηριοτήτων και προτύπων ταχύτερη και ευκολότερη από τον χειροκίνητο εντοπισμό ανωμαλιών, μειώνοντας την εργασία και τον χρόνο που απαιτείται για την επίλυση των απειλών.
- Ελαχιστοποιεί τους λειτουργικούς κινδύνους εντοπίζοντας λειτουργικά σφάλματα, όπως ξαφνικές πτώσεις απόδοσης, πριν καν εμφανιστούν.
- Βοηθά στην εξάλειψη μεγάλων επιχειρηματικών ζημιών εντοπίζοντας γρήγορα ανωμαλίες, καθώς χωρίς σύστημα ανίχνευσης ανωμαλιών, οι εταιρείες μπορεί να χρειαστούν εβδομάδες και μήνες για να εντοπίσουν πιθανές απειλές.
Έτσι, ο εντοπισμός ανωμαλιών είναι ένα τεράστιο πλεονέκτημα για τις επιχειρήσεις που αποθηκεύουν εκτεταμένα σύνολα δεδομένων πελατών και επιχειρήσεων για την εύρεση ευκαιριών ανάπτυξης και την εξάλειψη των απειλών ασφαλείας και των λειτουργικών σημείων συμφόρησης.
Τεχνικές Ανίχνευσης Ανωμαλιών
Ο εντοπισμός ανωμαλιών χρησιμοποιεί διάφορες διαδικασίες και αλγόριθμους μηχανικής μάθησης (ML) για την παρακολούθηση δεδομένων και τον εντοπισμό απειλών.
Ακολουθούν οι κύριες τεχνικές ανίχνευσης ανωμαλιών:
#1. Τεχνικές Μηχανικής Μάθησης

Οι τεχνικές Machines Learning χρησιμοποιούν αλγόριθμους ML για την ανάλυση δεδομένων και τον εντοπισμό ανωμαλιών. Οι διαφορετικοί τύποι αλγορίθμων Μηχανικής Μάθησης για τον εντοπισμό ανωμαλιών περιλαμβάνουν:
- Αλγόριθμοι ομαδοποίησης
- Αλγόριθμοι ταξινόμησης
- Αλγόριθμοι βαθιάς μάθησης
Και οι κοινώς χρησιμοποιούμενες τεχνικές ML για ανίχνευση ανωμαλιών και απειλών περιλαμβάνουν μηχανές διανυσμάτων υποστήριξης (SVM), ομαδοποίηση k-means και αυτοκωδικοποιητές.
#2. Στατιστικές Τεχνικές
Οι στατιστικές τεχνικές χρησιμοποιούν στατιστικά μοντέλα για τον εντοπισμό ασυνήθιστων μοτίβων (όπως ασυνήθιστες διακυμάνσεις στην απόδοση ενός συγκεκριμένου μηχανήματος) στα δεδομένα για τον εντοπισμό τιμών που υπερβαίνουν το εύρος των αναμενόμενων τιμών.
Οι κοινές τεχνικές ανίχνευσης στατιστικών ανωμαλιών περιλαμβάνουν δοκιμή υποθέσεων, IQR, Z-score, τροποποιημένο Z-score, εκτίμηση πυκνότητας, boxplot, ανάλυση ακραίων τιμών και ιστόγραμμα.
#3. Τεχνικές Εξόρυξης Δεδομένων

Οι τεχνικές εξόρυξης δεδομένων χρησιμοποιούν τεχνικές ταξινόμησης δεδομένων και ομαδοποίησης για την εύρεση ανωμαλιών εντός του συνόλου δεδομένων. Ορισμένες κοινές τεχνικές ανωμαλίας εξόρυξης δεδομένων περιλαμβάνουν τη φασματική ομαδοποίηση, τη ομαδοποίηση με βάση την πυκνότητα και την ανάλυση κύριου συστατικού.
Οι αλγόριθμοι εξόρυξης δεδομένων ομαδοποίησης χρησιμοποιούνται για την ομαδοποίηση διαφορετικών σημείων δεδομένων σε συστάδες με βάση την ομοιότητά τους για την εύρεση σημείων δεδομένων και ανωμαλιών που βρίσκονται εκτός αυτών των συστάδων.
Από την άλλη πλευρά, οι αλγόριθμοι ταξινόμησης εκχωρούν σημεία δεδομένων σε συγκεκριμένες προκαθορισμένες κλάσεις και εντοπίζουν σημεία δεδομένων που δεν ανήκουν σε αυτές τις κλάσεις.
#4. Τεχνικές βασισμένες σε κανόνες
Όπως υποδηλώνει το όνομα, οι τεχνικές ανίχνευσης ανωμαλιών βάσει κανόνων χρησιμοποιούν ένα σύνολο προκαθορισμένων κανόνων για την εύρεση ανωμαλιών στα δεδομένα.
Αυτές οι τεχνικές είναι συγκριτικά ευκολότερες και απλούστερες στη ρύθμιση, αλλά μπορεί να είναι άκαμπτες και μπορεί να μην είναι αποτελεσματικές στην προσαρμογή στη μεταβαλλόμενη συμπεριφορά και μοτίβα δεδομένων.
Για παράδειγμα, μπορείτε εύκολα να προγραμματίσετε ένα σύστημα που βασίζεται σε κανόνες για να επισημάνετε τις συναλλαγές που υπερβαίνουν ένα συγκεκριμένο ποσό σε δολάρια ως δόλιες.
#5. Τεχνικές Ειδικές για Τομέα
Μπορείτε να χρησιμοποιήσετε τεχνικές για συγκεκριμένους τομείς για τον εντοπισμό ανωμαλιών σε συγκεκριμένα συστήματα δεδομένων. Ωστόσο, ενώ μπορεί να είναι πολύ αποτελεσματικά στην ανίχνευση ανωμαλιών σε συγκεκριμένους τομείς, μπορεί να είναι λιγότερο αποτελεσματικά σε άλλους τομείς εκτός του καθορισμένου.
Για παράδειγμα, χρησιμοποιώντας τεχνικές για συγκεκριμένους τομείς, μπορείτε να σχεδιάσετε τεχνικές ειδικά για να βρείτε ανωμαλίες στις χρηματοοικονομικές συναλλαγές. Ωστόσο, ενδέχεται να μην λειτουργούν για την εύρεση ανωμαλιών ή πτώσεων απόδοσης σε ένα μηχάνημα.
Need For Machine Learning για Ανίχνευση Ανωμαλιών
Η μηχανική μάθηση είναι πολύ σημαντική και εξαιρετικά χρήσιμη στην ανίχνευση ανωμαλιών.
Σήμερα, οι περισσότερες εταιρείες και οργανισμοί που απαιτούν ανίχνευση ακραίων τιμών ασχολούνται με τεράστιες ποσότητες δεδομένων, από κείμενο, πληροφορίες πελατών και συναλλαγές έως αρχεία πολυμέσων, όπως εικόνες και περιεχόμενο βίντεο.
Η εξέταση όλων των τραπεζικών συναλλαγών και των δεδομένων που δημιουργούνται κάθε δευτερόλεπτο με μη αυτόματο τρόπο για να αποκτήσετε ουσιαστική εικόνα είναι σχεδόν αδύνατη. Επιπλέον, οι περισσότερες εταιρείες αντιμετωπίζουν προκλήσεις και μεγάλες δυσκολίες στη δομή των μη δομημένων δεδομένων και στην τακτοποίηση των δεδομένων με ουσιαστικό τρόπο για ανάλυση δεδομένων.
Εδώ είναι όπου εργαλεία και τεχνικές όπως η μηχανική μάθηση (ML) παίζουν τεράστιο ρόλο στη συλλογή, τον καθαρισμό, τη δόμηση, την τακτοποίηση, την ανάλυση και την αποθήκευση τεράστιων όγκων μη δομημένων δεδομένων.
Οι τεχνικές και οι αλγόριθμοι Μηχανικής Μάθησης επεξεργάζονται μεγάλα σύνολα δεδομένων και παρέχουν την ευελιξία στη χρήση και τον συνδυασμό διαφορετικών τεχνικών και αλγορίθμων για την παροχή των καλύτερων αποτελεσμάτων.
Επιπλέον, η μηχανική εκμάθηση βοηθά επίσης στον εξορθολογισμό των διαδικασιών ανίχνευσης ανωμαλιών για εφαρμογές πραγματικού κόσμου και εξοικονομεί πολύτιμους πόρους.
Ακολουθούν μερικά ακόμη οφέλη και η σημασία της μηχανικής μάθησης στον εντοπισμό ανωμαλιών:
- Κάνει την ανίχνευση ανωμαλιών πιο εύκολη στην κλίμακα αυτοματοποιώντας την αναγνώριση προτύπων και ανωμαλιών χωρίς να απαιτείται ρητός προγραμματισμός.
- Οι αλγόριθμοι μηχανικής μάθησης είναι εξαιρετικά προσαρμόσιμοι στην αλλαγή των μοτίβων συνόλων δεδομένων, καθιστώντας τους εξαιρετικά αποτελεσματικούς και ανθεκτικούς με το χρόνο.
- Χειρίζεται εύκολα μεγάλα και πολύπλοκα σύνολα δεδομένων, καθιστώντας αποτελεσματική την ανίχνευση ανωμαλιών παρά την πολυπλοκότητα του συνόλου δεδομένων.
- Εξασφαλίζει έγκαιρη αναγνώριση και ανίχνευση ανωμαλιών εντοπίζοντας ανωμαλίες καθώς συμβαίνουν, εξοικονομώντας χρόνο και πόρους.
- Τα συστήματα ανίχνευσης ανωμαλιών που βασίζονται στη Μηχανική Μάθηση βοηθούν στην επίτευξη υψηλότερων επιπέδων ακρίβειας στον εντοπισμό ανωμαλιών σε σύγκριση με τις παραδοσιακές μεθόδους.
Έτσι, η ανίχνευση ανωμαλιών σε συνδυασμό με τη μηχανική εκμάθηση βοηθά στην ταχύτερη και πιο έγκαιρη ανίχνευση ανωμαλιών για την πρόληψη απειλών ασφαλείας και κακόβουλων παραβιάσεων.
Αλγόριθμοι μηχανικής μάθησης για ανίχνευση ανωμαλιών
Μπορείτε να εντοπίσετε ανωμαλίες και ακραίες τιμές στα δεδομένα με τη βοήθεια διαφορετικών αλγορίθμων εξόρυξης δεδομένων για εκμάθηση κανόνων ταξινόμησης, ομαδοποίησης ή συσχέτισης.
Συνήθως, αυτοί οι αλγόριθμοι εξόρυξης δεδομένων ταξινομούνται σε δύο διαφορετικές κατηγορίες — αλγόριθμους μάθησης υπό επίβλεψη και χωρίς επίβλεψη.
Εποπτευόμενη μάθηση
Η εποπτευόμενη μάθηση είναι ένας κοινός τύπος αλγορίθμου μάθησης που αποτελείται από αλγόριθμους όπως μηχανές διανυσμάτων υποστήριξης, λογιστική και γραμμική παλινδρόμηση και ταξινόμηση πολλαπλών τάξεων. Αυτός ο τύπος αλγορίθμου εκπαιδεύεται σε δεδομένα με ετικέτα, που σημαίνει ότι το σύνολο δεδομένων εκπαίδευσης περιλαμβάνει τόσο κανονικά δεδομένα εισόδου όσο και αντίστοιχα σωστά αποτελέσματα ή ανώμαλα παραδείγματα για την κατασκευή ενός προγνωστικού μοντέλου.
Έτσι, ο στόχος του είναι να κάνει προβλέψεις εξόδου για αόρατα και νέα δεδομένα με βάση τα πρότυπα συνόλων δεδομένων εκπαίδευσης. Οι εφαρμογές των εποπτευόμενων αλγορίθμων μάθησης περιλαμβάνουν την αναγνώριση εικόνας και ομιλίας, την προγνωστική μοντελοποίηση και την επεξεργασία φυσικής γλώσσας (NLP).
Μάθηση χωρίς επίβλεψη
Η μάθηση χωρίς επίβλεψη δεν εκπαιδεύεται σε δεδομένα με ετικέτα. Αντίθετα, ανακαλύπτει περίπλοκες διαδικασίες και υποκείμενες δομές δεδομένων χωρίς να παρέχει καθοδήγηση για τον αλγόριθμο εκπαίδευσης και αντί να κάνει συγκεκριμένες προβλέψεις.
Οι εφαρμογές των αλγορίθμων μάθησης χωρίς επίβλεψη περιλαμβάνουν την ανίχνευση ανωμαλιών, την εκτίμηση της πυκνότητας και τη συμπίεση δεδομένων.
Τώρα, ας εξερευνήσουμε μερικούς δημοφιλείς αλγόριθμους ανίχνευσης ανωμαλιών που βασίζονται σε μηχανική μάθηση.
Τοπικός ακραίος παράγοντας (LOF)
Ο τοπικός παράγων ή LOF είναι ένας αλγόριθμος ανίχνευσης ανωμαλιών που λαμβάνει υπόψη την τοπική πυκνότητα δεδομένων για να καθορίσει εάν ένα σημείο δεδομένων είναι ανωμαλία.
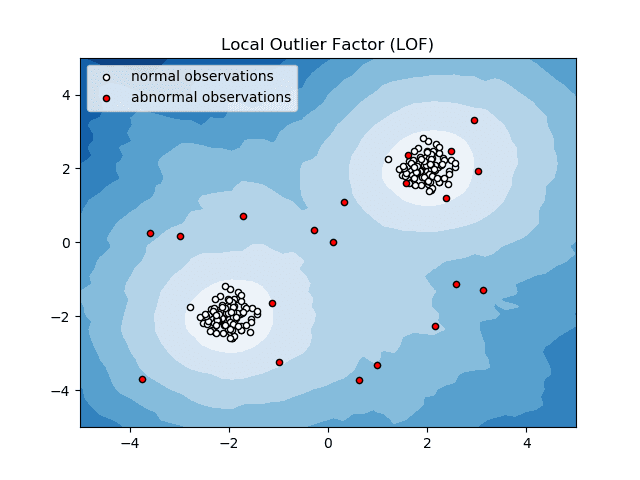 Πηγή: scikit-learn.org
Πηγή: scikit-learn.org
Συγκρίνει την τοπική πυκνότητα ενός αντικειμένου με τις τοπικές πυκνότητες των γειτόνων του για να αναλύσει περιοχές με παρόμοιες πυκνότητες και στοιχεία με συγκριτικά χαμηλότερες πυκνότητες από τις γειτονικές τους – οι οποίες δεν είναι παρά ανωμαλίες ή ακραίες τιμές.
Έτσι, με απλά λόγια, η πυκνότητα που περιβάλλει ένα ακραίο ή ανώμαλο στοιχείο διαφέρει από την πυκνότητα γύρω από τους γείτονές του. Ως εκ τούτου, αυτός ο αλγόριθμος ονομάζεται επίσης αλγόριθμος ανίχνευσης ακραίων τιμών με βάση την πυκνότητα.
K-πλησιέστερος γείτονας (K-NN)
Το K-NN είναι ο απλούστερος αλγόριθμος ταξινόμησης και εποπτευόμενης ανίχνευσης ανωμαλιών που είναι εύκολο να εφαρμοστεί, αποθηκεύει όλα τα διαθέσιμα παραδείγματα και δεδομένα και ταξινομεί τα νέα παραδείγματα με βάση τις ομοιότητες στις μετρήσεις απόστασης.
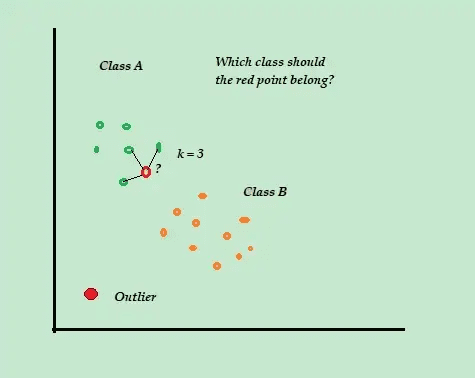 Πηγή: intodatascience.com
Πηγή: intodatascience.com
Αυτός ο αλγόριθμος ταξινόμησης ονομάζεται επίσης τεμπέλης μαθητής επειδή αποθηκεύει μόνο τα επισημασμένα δεδομένα εκπαίδευσης — χωρίς να κάνει τίποτα άλλο κατά τη διάρκεια της εκπαιδευτικής διαδικασίας.
Όταν φτάσει το νέο μη επισημασμένο σημείο δεδομένων εκπαίδευσης, ο αλγόριθμος εξετάζει το Κ-πλησιέστερο ή τα πλησιέστερα σημεία δεδομένων εκπαίδευσης για να τα χρησιμοποιήσει για να ταξινομήσει και να καθορίσει την κλάση του νέου σημείου δεδομένων χωρίς ετικέτα.
Ο αλγόριθμος K-NN χρησιμοποιεί τις ακόλουθες μεθόδους ανίχνευσης για τον προσδιορισμό των πλησιέστερων σημείων δεδομένων:
- Ευκλείδεια απόσταση για τη μέτρηση της απόστασης για συνεχή δεδομένα.
- Απόσταση Hamming για τη μέτρηση της εγγύτητας ή της «εγγύτητας» των δύο συμβολοσειρών κειμένου για διακριτά δεδομένα.
Για παράδειγμα, θεωρήστε ότι τα σύνολα δεδομένων εκπαίδευσης αποτελούνται από δύο ετικέτες κλάσης, Α και Β. Εάν φτάσει ένα νέο σημείο δεδομένων, ο αλγόριθμος θα υπολογίσει την απόσταση μεταξύ του νέου σημείου δεδομένων και καθενός από τα σημεία δεδομένων στο σύνολο δεδομένων και θα επιλέξει τα σημεία που είναι ο μέγιστος σε αριθμό πλησιέστερα στο νέο σημείο δεδομένων.
Λοιπόν, ας υποθέσουμε ότι K=3, και 2 από τα 3 σημεία δεδομένων επισημαίνονται ως Α, τότε το νέο σημείο δεδομένων χαρακτηρίζεται ως κλάση Α.
Ως εκ τούτου, ο αλγόριθμος K-NN λειτουργεί καλύτερα σε δυναμικά περιβάλλοντα με συχνές απαιτήσεις ενημέρωσης δεδομένων.
Είναι ένας δημοφιλής αλγόριθμος ανίχνευσης ανωμαλιών και εξόρυξης κειμένου με εφαρμογές στα οικονομικά και τις επιχειρήσεις για τον εντοπισμό δόλιων συναλλαγών και την αύξηση του ποσοστού εντοπισμού απάτης.
Υποστήριξη Vector Machine (SVM)
Το Support Vector Machine είναι ένας εποπτευόμενος αλγόριθμος ανίχνευσης ανωμαλιών που βασίζεται στη μηχανική μάθηση που χρησιμοποιείται κυρίως σε προβλήματα παλινδρόμησης και ταξινόμησης.
Χρησιμοποιεί ένα πολυδιάστατο υπερεπίπεδο για να διαχωρίσει δεδομένα σε δύο ομάδες (νέα και κανονική). Έτσι, το υπερεπίπεδο λειτουργεί ως όριο απόφασης που διαχωρίζει τις κανονικές παρατηρήσεις δεδομένων και τα νέα δεδομένα.
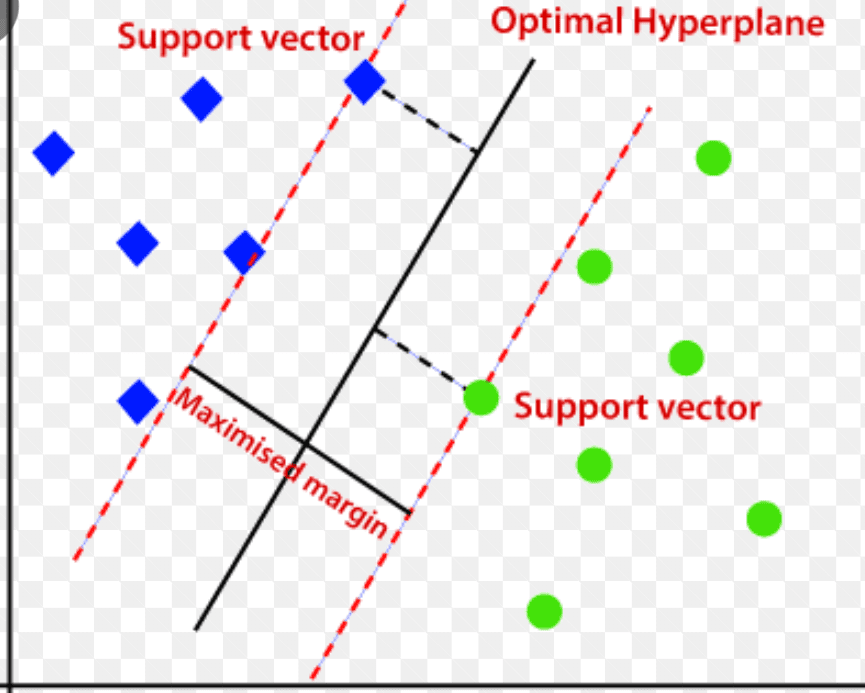 Πηγή: www.analyticsvidhya.com
Πηγή: www.analyticsvidhya.com
Η απόσταση μεταξύ αυτών των δύο σημείων δεδομένων αναφέρεται ως περιθώρια.
Δεδομένου ότι ο στόχος είναι να αυξηθεί η απόσταση μεταξύ των δύο σημείων, το SVM καθορίζει το καλύτερο ή το βέλτιστο υπερεπίπεδο με το μέγιστο περιθώριο για να διασφαλίσει ότι η απόσταση μεταξύ των δύο κατηγοριών είναι όσο το δυνατόν μεγαλύτερη.
Όσον αφορά τον εντοπισμό ανωμαλιών, το SVM υπολογίζει το περιθώριο παρατήρησης του νέου σημείου δεδομένων από το υπερεπίπεδο για να το ταξινομήσει.
Εάν το περιθώριο υπερβαίνει το καθορισμένο όριο, ταξινομεί τη νέα παρατήρηση ως ανωμαλία. Ταυτόχρονα, εάν το περιθώριο είναι μικρότερο από το όριο, η παρατήρηση ταξινομείται ως κανονική.
Έτσι, οι αλγόριθμοι SVM είναι εξαιρετικά αποδοτικοί στο χειρισμό υψηλών διαστάσεων και πολύπλοκων συνόλων δεδομένων.
Δάσος απομόνωσης
Το Isolation Forest είναι ένας αλγόριθμος ανίχνευσης ανωμαλιών χωρίς επίβλεψη μηχανικής μάθησης που βασίζεται στην έννοια του Τυχαίου Ταξινομητή Δασών.
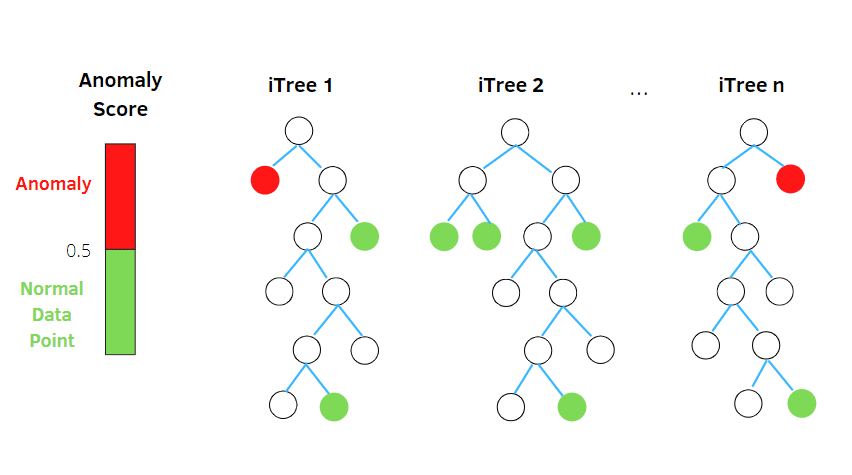 Πηγή: betterprogramming.pub
Πηγή: betterprogramming.pub
Αυτός ο αλγόριθμος επεξεργάζεται τυχαία δεδομένα υποδειγματοληψίας στο σύνολο δεδομένων σε μια δενδρική δομή που βασίζεται σε τυχαία χαρακτηριστικά. Κατασκευάζει πολλά δέντρα απόφασης για να απομονώσει τις παρατηρήσεις. Και θεωρεί μια συγκεκριμένη παρατήρηση ανωμαλία εάν απομονωθεί σε λιγότερα δέντρα με βάση το ποσοστό μόλυνσης.
Έτσι, με απλά λόγια, ο αλγόριθμος του δάσους απομόνωσης χωρίζει τα σημεία δεδομένων σε διαφορετικά δέντρα απόφασης – διασφαλίζοντας ότι κάθε παρατήρηση απομονώνεται από μια άλλη.
Οι ανωμαλίες συνήθως βρίσκονται μακριά από το σύμπλεγμα σημείων δεδομένων—καθιστώντας ευκολότερο τον εντοπισμό των ανωμαλιών σε σύγκριση με τα κανονικά σημεία δεδομένων.
Οι δασικοί αλγόριθμοι απομόνωσης μπορούν εύκολα να χειριστούν κατηγορικά και αριθμητικά δεδομένα. Ως αποτέλεσμα, εκπαιδεύονται ταχύτερα και είναι εξαιρετικά αποτελεσματικά στον εντοπισμό ανωμαλιών υψηλών διαστάσεων και μεγάλων συνόλων δεδομένων.
Διατεταρτημοριακό εύρος
Το interquartile range ή το IQR χρησιμοποιείται για τη μέτρηση της στατιστικής μεταβλητότητας ή της στατιστικής διασποράς για την εύρεση ανώμαλων σημείων στα σύνολα δεδομένων διαιρώντας τα σε τεταρτημόρια.
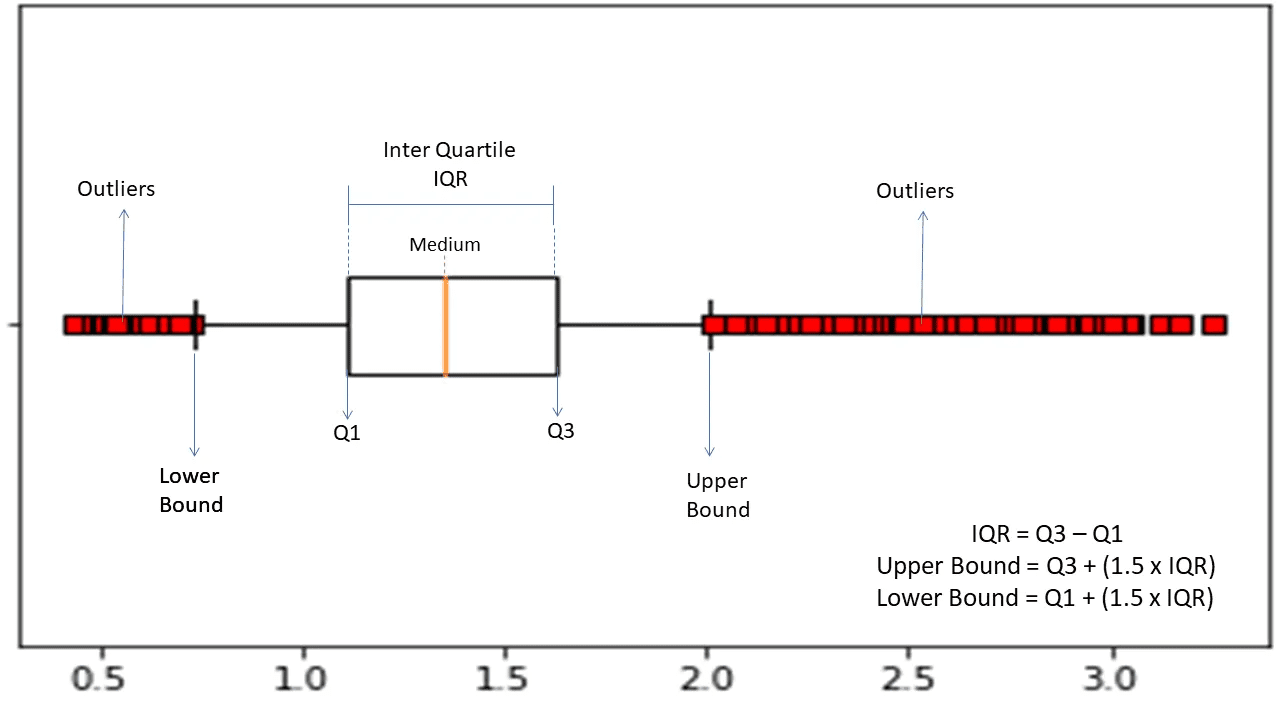 Πηγή: morioh.com
Πηγή: morioh.com
Ο αλγόριθμος ταξινομεί τα δεδομένα σε αύξουσα σειρά και χωρίζει το σύνολο σε τέσσερα ίσα μέρη. Οι τιμές που χωρίζουν αυτά τα μέρη είναι τα Q1, Q2 και Q3—πρώτο, δεύτερο και τρίτο τεταρτημόριο.
Ακολουθεί η εκατοστιαία κατανομή αυτών των τεταρτημορίων:
- Q1 σημαίνει το 25ο εκατοστημόριο των δεδομένων.
- Το Q2 σημαίνει το 50ο εκατοστημόριο των δεδομένων.
- Το Q3 σημαίνει το 75ο εκατοστημόριο των δεδομένων.
Το IQR είναι η διαφορά μεταξύ του τρίτου (75ου) και του πρώτου (25ου) εκατοστημίου συνόλων δεδομένων, που αντιπροσωπεύει το 50% των δεδομένων.
Η χρήση του IQR για την ανίχνευση ανωμαλιών απαιτεί να υπολογίσετε το IQR του συνόλου δεδομένων σας και να ορίσετε τα κάτω και τα ανώτερα όρια των δεδομένων για να βρείτε ανωμαλίες.
- Κάτω όριο: Q1 – 1,5 * IQR
- Ανώτερο όριο: Q3 + 1,5 * IQR
Συνήθως, οι παρατηρήσεις που βρίσκονται εκτός αυτών των ορίων θεωρούνται ανωμαλίες.
Ο αλγόριθμος IQR είναι αποτελεσματικός για σύνολα δεδομένων με άνισα κατανεμημένα δεδομένα και όπου η κατανομή δεν είναι καλά κατανοητή.
Τελικές Λέξεις
Οι κίνδυνοι για την ασφάλεια στον κυβερνοχώρο και οι παραβιάσεις δεδομένων δεν φαίνεται να περιορίζονται τα επόμενα χρόνια—και αυτή η επικίνδυνη βιομηχανία αναμένεται να αναπτυχθεί περαιτέρω το 2023 και οι επιθέσεις στον κυβερνοχώρο του IoT από μόνες τους αναμένεται να διπλασιαστούν μέχρι το 2025.
Επιπλέον, τα εγκλήματα στον κυβερνοχώρο θα κοστίζουν σε παγκόσμιες εταιρείες και οργανισμούς περίπου 10,3 τρισεκατομμύρια δολάρια ετησίως μέχρι το 2025.
Αυτός είναι ο λόγος για τον οποίο η ανάγκη για τεχνικές ανίχνευσης ανωμαλιών γίνεται πιο διαδεδομένη και απαραίτητη σήμερα για τον εντοπισμό απάτης και την πρόληψη εισβολών στο δίκτυο.
Αυτό το άρθρο θα σας βοηθήσει να κατανοήσετε ποιες είναι οι ανωμαλίες στην εξόρυξη δεδομένων, διαφορετικοί τύποι ανωμαλιών και τρόποι αποτροπής εισβολών στο δίκτυο χρησιμοποιώντας τεχνικές ανίχνευσης ανωμαλιών που βασίζονται σε ML.
Στη συνέχεια, μπορείτε να εξερευνήσετε τα πάντα σχετικά με τη μήτρα σύγχυσης στη μηχανική εκμάθηση.