
Στον τομέα της σύγχρονης τεχνητής νοημοσύνης (AI), η ενισχυτική μάθηση (RL) είναι ένα από τα πιο ενδιαφέροντα ερευνητικά θέματα. Οι προγραμματιστές τεχνητής νοημοσύνης και μηχανικής μάθησης (ML) εστιάζουν επίσης σε πρακτικές RL για να αυτοσχεδιάσουν έξυπνες εφαρμογές ή εργαλεία που αναπτύσσουν.
Η μηχανική εκμάθηση είναι η αρχή πίσω από όλα τα προϊόντα AI. Οι ανθρώπινοι προγραμματιστές χρησιμοποιούν διάφορες μεθοδολογίες ML για να εκπαιδεύσουν τις έξυπνες εφαρμογές, τα παιχνίδια τους κ.λπ. Το ML είναι ένα εξαιρετικά διαφοροποιημένο πεδίο και διαφορετικές ομάδες ανάπτυξης διαθέτουν νέες μεθόδους εκπαίδευσης ενός μηχανήματος.
Μια τέτοια προσοδοφόρα μέθοδος ML είναι η βαθιά ενισχυτική μάθηση. Εδώ, τιμωρείτε τις ανεπιθύμητες συμπεριφορές του μηχανήματος και επιβραβεύετε τις επιθυμητές ενέργειες από το έξυπνο μηχάνημα. Οι ειδικοί θεωρούν ότι αυτή η μέθοδος ML είναι βέβαιο ότι θα ωθήσει το AI να μάθει από τις δικές του εμπειρίες.
Συνεχίστε να διαβάζετε αυτόν τον απόλυτο οδηγό για μεθόδους ενίσχυσης εκμάθησης για έξυπνες εφαρμογές και μηχανές, εάν σκέφτεστε να κάνετε καριέρα στην τεχνητή νοημοσύνη και τη μηχανική μάθηση.
Πίνακας περιεχομένων
Τι είναι η Ενισχυτική Μάθηση στη Μηχανική Μάθηση;
Το RL είναι η διδασκαλία μοντέλων μηχανικής μάθησης σε προγράμματα υπολογιστών. Στη συνέχεια, η εφαρμογή μπορεί να λάβει μια σειρά αποφάσεων με βάση τα μοντέλα μάθησης. Το λογισμικό μαθαίνει να επιτυγχάνει έναν στόχο σε ένα δυνητικά περίπλοκο και αβέβαιο περιβάλλον. Σε αυτό το είδος μοντέλου μηχανικής μάθησης, ένα AI αντιμετωπίζει ένα σενάριο που μοιάζει με παιχνίδι.
Η εφαρμογή AI χρησιμοποιεί δοκιμή και σφάλμα για να εφεύρει μια δημιουργική λύση στο πρόβλημα. Μόλις η εφαρμογή AI μάθει σωστά μοντέλα ML, δίνει οδηγίες στο μηχάνημα που ελέγχει να κάνει κάποιες εργασίες που θέλει ο προγραμματιστής.
Με βάση τη σωστή απόφαση και την ολοκλήρωση της εργασίας, το AI λαμβάνει μια ανταμοιβή. Ωστόσο, εάν το AI κάνει λάθος επιλογές, αντιμετωπίζει ποινές, όπως να χάσει πόντους ανταμοιβής. Ο απώτερος στόχος για την εφαρμογή AI είναι να συγκεντρώσει τον μέγιστο αριθμό πόντων ανταμοιβής για να κερδίσει το παιχνίδι.
Ο προγραμματιστής της εφαρμογής AI ορίζει τους κανόνες του παιχνιδιού ή την πολιτική ανταμοιβών. Ο προγραμματιστής παρέχει επίσης το πρόβλημα που πρέπει να λύσει το AI. Σε αντίθεση με άλλα μοντέλα ML, το πρόγραμμα AI δεν λαμβάνει καμία υπόδειξη από τον προγραμματιστή λογισμικού.
Το AI πρέπει να καταλάβει πώς να επιλύσει τις προκλήσεις του παιχνιδιού για να κερδίσει τις μέγιστες ανταμοιβές. Η εφαρμογή μπορεί να χρησιμοποιήσει δοκιμή και σφάλμα, τυχαίες δοκιμές, δεξιότητες υπερυπολογιστή και εξελιγμένες τακτικές διαδικασίας σκέψης για να καταλήξει σε μια λύση.
Πρέπει να εξοπλίσετε το πρόγραμμα AI με ισχυρή υπολογιστική υποδομή και να συνδέσετε το σύστημα σκέψης του με διάφορα παράλληλα και ιστορικά παιχνίδια. Στη συνέχεια, η τεχνητή νοημοσύνη μπορεί να επιδείξει κρίσιμη και υψηλού επιπέδου δημιουργικότητα που οι άνθρωποι δεν μπορούν να φανταστούν.
Δημοφιλή Παραδείγματα Ενισχυτικής Μάθησης
#1. Νικώντας τον καλύτερο παίκτη Human Go
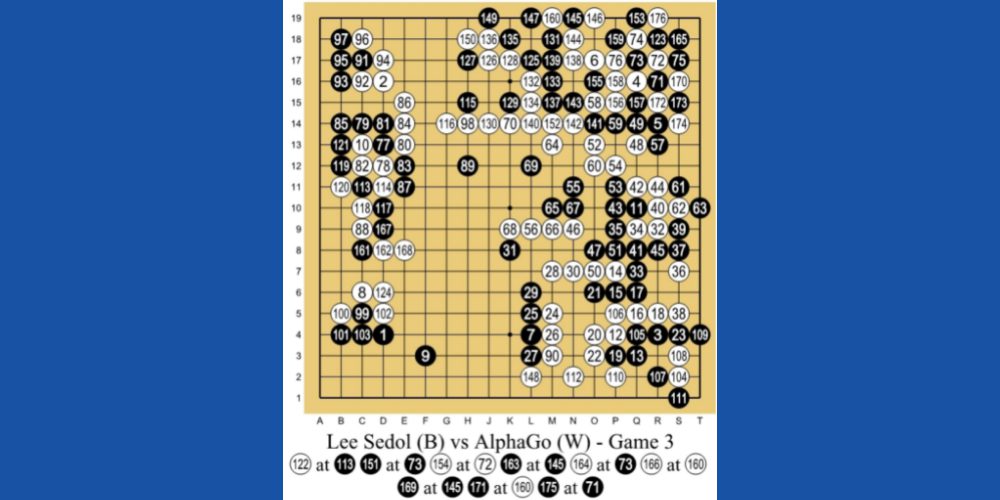
Το AlphaGo AI από την DeepMind Technologies, θυγατρική της Google, είναι ένα από τα κορυφαία παραδείγματα μηχανικής μάθησης που βασίζεται σε RL. Το AI παίζει ένα κινέζικο επιτραπέζιο παιχνίδι που ονομάζεται Go. Είναι ένα παιχνίδι 3.000 ετών που επικεντρώνεται σε τακτικές και στρατηγικές.
Οι προγραμματιστές χρησιμοποίησαν τη μέθοδο διδασκαλίας RL για το AlphaGo. Έπαιξε χιλιάδες συνεδρίες παιχνιδιών Go με ανθρώπους και τον εαυτό του. Στη συνέχεια, το 2016 νίκησε τον καλύτερο παίκτη Go στον κόσμο, Lee Se-dol σε έναν αγώνα ένας εναντίον ενός.
#2. Ρομποτική πραγματικού κόσμου
Οι άνθρωποι χρησιμοποιούν τη ρομποτική για πολύ καιρό σε γραμμές παραγωγής όπου οι εργασίες είναι προσχεδιασμένες και επαναλαμβανόμενες. Αλλά, αν χρειάζεται να φτιάξετε ένα ρομπότ γενικής χρήσης για τον πραγματικό κόσμο όπου οι ενέργειες δεν είναι προσχεδιασμένες, τότε είναι μεγάλη πρόκληση.
Ωστόσο, η τεχνητή νοημοσύνη με δυνατότητα ενίσχυσης της μάθησης θα μπορούσε να ανακαλύψει μια ομαλή, πλωτή και σύντομη διαδρομή μεταξύ δύο τοποθεσιών.
#3. Αυτοοδηγούμενα Οχήματα
Οι ερευνητές αυτόνομων οχημάτων χρησιμοποιούν ευρέως τη μέθοδο RL για να διδάξουν τα AI τους για:
- Δυναμική διαδρομή
- Βελτιστοποίηση τροχιάς
- Σχεδιασμός κίνησης όπως στάθμευση και αλλαγή λωρίδας
- Ελεγκτές βελτιστοποίησης, (ηλεκτρονική μονάδα ελέγχου) ECU, (μικροελεγκτές) MCU κ.λπ.
- Εκμάθηση βάσει σεναρίων σε αυτοκινητόδρομους
#4. Αυτοματοποιημένα Συστήματα Ψύξης

Τα AI που βασίζονται σε RL μπορούν να βοηθήσουν στην ελαχιστοποίηση της κατανάλωσης ενέργειας των συστημάτων ψύξης σε γιγάντια κτίρια γραφείων, επιχειρηματικά κέντρα, εμπορικά κέντρα και, το πιο σημαντικό, κέντρα δεδομένων. Το AI συλλέγει δεδομένα από χιλιάδες αισθητήρες θερμότητας.
Συγκεντρώνει επίσης δεδομένα για τις δραστηριότητες του ανθρώπου και των μηχανημάτων. Από αυτά τα δεδομένα, το AI μπορεί να προβλέψει το μελλοντικό δυναμικό παραγωγής θερμότητας και να ενεργοποιεί και να απενεργοποιεί κατάλληλα τα συστήματα ψύξης για εξοικονόμηση ενέργειας.
Πώς να ρυθμίσετε ένα μοντέλο ενίσχυσης μάθησης
Μπορείτε να ρυθμίσετε ένα μοντέλο RL με βάση τις ακόλουθες μεθόδους:
#1. Με βάση την πολιτική
Αυτή η προσέγγιση δίνει τη δυνατότητα στον προγραμματιστή AI να βρει την ιδανική πολιτική για μέγιστες ανταμοιβές. Εδώ, ο προγραμματιστής δεν χρησιμοποιεί τη συνάρτηση τιμής. Μόλις ορίσετε τη μέθοδο που βασίζεται σε πολιτική, ο πράκτορας ενίσχυσης εκμάθησης προσπαθεί να εφαρμόσει την πολιτική έτσι ώστε οι ενέργειες που εκτελεί σε κάθε βήμα να επιτρέπουν στο AI να μεγιστοποιήσει τους πόντους ανταμοιβής.
Υπάρχουν κυρίως δύο τύποι πολιτικών:
#1. Ντετερμινιστικό: Η πολιτική μπορεί να παράγει τις ίδιες ενέργειες σε κάθε δεδομένη κατάσταση.
#2. Στοχαστική: Οι παραγόμενες ενέργειες καθορίζονται από την πιθανότητα εμφάνισης.
#2. Με βάση την αξία
Η προσέγγιση που βασίζεται σε τιμές, αντίθετα, βοηθά τον προγραμματιστή να βρει τη βέλτιστη συνάρτηση τιμής, η οποία είναι η μέγιστη τιμή σε μια πολιτική σε κάθε δεδομένη κατάσταση. Μόλις εφαρμοστεί, ο πράκτορας RL αναμένει τη μακροπρόθεσμη απόδοση σε οποιαδήποτε ή περισσότερες πολιτείες σύμφωνα με την εν λόγω πολιτική.
#3. Με βάση το μοντέλο
Στην προσέγγιση RL που βασίζεται σε μοντέλα, ο προγραμματιστής AI δημιουργεί ένα εικονικό μοντέλο για το περιβάλλον. Στη συνέχεια, ο πράκτορας RL μετακινείται στο περιβάλλον και μαθαίνει από αυτό.
Τύποι Ενισχυτικής Μάθησης
#1. Θετική Ενισχυτική Μάθηση (PRL)
Θετική μάθηση σημαίνει προσθήκη κάποιων στοιχείων για να αυξηθεί η πιθανότητα να συμβεί ξανά η αναμενόμενη συμπεριφορά. Αυτή η μέθοδος εκμάθησης επηρεάζει θετικά τη συμπεριφορά του πράκτορα RL. Το PRL βελτιώνει επίσης την ισχύ ορισμένων συμπεριφορών του AI σας.
Ο τύπος μαθησιακής ενίσχυσης PRL θα πρέπει να προετοιμάσει την τεχνητή νοημοσύνη να προσαρμοστεί στις αλλαγές για μεγάλο χρονικό διάστημα. Αλλά η ένεση υπερβολικής θετικής μάθησης μπορεί να οδηγήσει σε υπερβολική επιβάρυνση των καταστάσεων που μπορεί να μειώσει την αποτελεσματικότητα του AI.

#2. Αρνητική Ενισχυτική Μάθηση (NRL)
Όταν ο αλγόριθμος RL βοηθά το AI να αποφύγει ή να σταματήσει μια αρνητική συμπεριφορά, μαθαίνει από αυτήν και βελτιώνει τις μελλοντικές του ενέργειες. Είναι γνωστό ως αρνητική μάθηση. Παρέχει στην τεχνητή νοημοσύνη περιορισμένη νοημοσύνη μόνο για να καλύψει ορισμένες απαιτήσεις συμπεριφοράς.
Πραγματικές Περιπτώσεις Χρήσης Ενισχυτικής Μάθησης
#1. Οι προγραμματιστές λύσεων ηλεκτρονικού εμπορίου έχουν δημιουργήσει εξατομικευμένα εργαλεία που προτείνουν προϊόντα ή υπηρεσίες. Μπορείτε να συνδέσετε το API του εργαλείου στον ιστότοπο ηλεκτρονικών αγορών σας. Στη συνέχεια, το AI θα μάθει από μεμονωμένους χρήστες και θα προτείνει προσαρμοσμένα αγαθά και υπηρεσίες.
#2. Τα βιντεοπαιχνίδια ανοιχτού κόσμου έχουν απεριόριστες δυνατότητες. Ωστόσο, υπάρχει ένα πρόγραμμα τεχνητής νοημοσύνης πίσω από το πρόγραμμα παιχνιδιού που μαθαίνει από τη συμβολή των παικτών και τροποποιεί τον κώδικα του βιντεοπαιχνιδιού για να προσαρμοστεί σε μια άγνωστη κατάσταση.
#3. Οι πλατφόρμες συναλλαγών και επενδύσεων μετοχών που βασίζονται στην τεχνητή νοημοσύνη χρησιμοποιούν το μοντέλο RL για να μάθουν από την κίνηση των μετοχών και των παγκόσμιων δεικτών. Αντίστοιχα, διαμορφώνουν ένα μοντέλο πιθανότητας για να προτείνουν μετοχές για επένδυση ή διαπραγμάτευση.
#4. Οι διαδικτυακές βιβλιοθήκες βίντεο όπως το YouTube, το Metacafe, το Dailymotion κ.λπ., χρησιμοποιούν bots AI που έχουν εκπαιδευτεί στο μοντέλο RL για να προτείνουν εξατομικευμένα βίντεο στους χρήστες τους.
Ενισχυτική Μάθηση Vs. Εποπτευόμενη μάθηση
Η ενισχυτική μάθηση στοχεύει στην εκπαίδευση του πράκτορα AI ώστε να λαμβάνει αποφάσεις διαδοχικά. Με λίγα λόγια, μπορείτε να θεωρήσετε ότι η έξοδος του AI εξαρτάται από την κατάσταση της παρούσας εισόδου. Ομοίως, η επόμενη είσοδος στον αλγόριθμο RL θα εξαρτηθεί από την έξοδο των προηγούμενων εισόδων.

Ένα ρομποτικό μηχάνημα βασισμένο σε AI που παίζει ένα παιχνίδι σκάκι εναντίον ενός ανθρώπου σκακιστή είναι ένα παράδειγμα του μοντέλου μηχανικής εκμάθησης RL.
Αντίθετα, στην εποπτευόμενη μάθηση, ο προγραμματιστής εκπαιδεύει τον πράκτορα AI να λαμβάνει αποφάσεις με βάση τις εισόδους που δίνονται στην αρχή ή οποιαδήποτε άλλη αρχική είσοδο. Η αυτόνομη τεχνητή νοημοσύνη οδήγησης αυτοκινήτου που αναγνωρίζει περιβαλλοντικά αντικείμενα είναι ένα εξαιρετικό παράδειγμα εποπτευόμενης μάθησης.
Ενισχυτική Μάθηση Vs. Μάθηση χωρίς επίβλεψη
Μέχρι στιγμής, έχετε καταλάβει ότι η μέθοδος RL ωθεί τον πράκτορα AI να μάθει από τις πολιτικές μοντέλων μηχανικής εκμάθησης. Κυρίως, το AI θα κάνει μόνο εκείνα τα βήματα για τα οποία λαμβάνει τους μέγιστους πόντους ανταμοιβής. Το RL βοηθά ένα AI να αυτοσχεδιαστεί μέσω δοκιμής και λάθους.
Από την άλλη πλευρά, στην μάθηση χωρίς επίβλεψη, ο προγραμματιστής τεχνητής νοημοσύνης εισάγει το λογισμικό τεχνητής νοημοσύνης με δεδομένα χωρίς ετικέτα. Επίσης, ο εκπαιδευτής ML δεν λέει στην τεχνητή νοημοσύνη τίποτα σχετικά με τη δομή δεδομένων ή τι να αναζητήσει στα δεδομένα. Ο αλγόριθμος μαθαίνει διάφορες αποφάσεις καταλογοποιώντας τις δικές του παρατηρήσεις στα δεδομένα άγνωστα σύνολα δεδομένων.
Μαθήματα Ενισχυτικής Μάθησης
Τώρα που μάθατε τα βασικά, ακολουθούν ορισμένα διαδικτυακά μαθήματα για να μάθετε την προηγμένη ενισχυτική μάθηση. Λαμβάνετε επίσης ένα πιστοποιητικό που μπορείτε να επιδείξετε στο LinkedIn ή σε άλλες πλατφόρμες κοινωνικής δικτύωσης:
Ενισχυτική Μάθηση Ειδίκευση: Coursera
Ψάχνετε να κατακτήσετε τις βασικές έννοιες της ενισχυτικής μάθησης με πλαίσιο ML; Μπορείτε να το δοκιμάσετε αυτό Μάθημα Coursera RL το οποίο είναι διαθέσιμο στο διαδίκτυο και συνοδεύεται από δυνατότητα εκμάθησης και πιστοποίησης με αυτόματο ρυθμό. Το μάθημα θα είναι κατάλληλο για εσάς εάν έχετε τα ακόλουθα ως βασικές δεξιότητες:
- Γνώσεις προγραμματισμού σε Python
- Βασικές στατιστικές έννοιες
- Μπορείτε να μετατρέψετε ψευδοκώδικες και αλγόριθμους σε κωδικούς Python
- Εμπειρία ανάπτυξης λογισμικού δύο έως τριών ετών
- Οι προπτυχιακοί φοιτητές του δεύτερου έτους στην επιστήμη των υπολογιστών είναι επίσης επιλέξιμοι
Το μάθημα έχει βαθμολογία 4,8 αστέρων και περισσότεροι από 36.000 μαθητές έχουν ήδη εγγραφεί στο μάθημα σε διαφορετικά χρονικά διαστήματα. Επιπλέον, το μάθημα συνοδεύεται από οικονομική βοήθεια υπό την προϋπόθεση ότι ο υποψήφιος πληροί ορισμένα κριτήρια επιλεξιμότητας του Coursera.
Τέλος, το Ινστιτούτο Μηχανικής Νοημοσύνης της Αλμπέρτα του Πανεπιστημίου της Αλμπέρτα προσφέρει αυτό το μάθημα (δεν χορηγείται πίστωση). Αξιότιμοι καθηγητές στον τομέα της επιστήμης των υπολογιστών θα λειτουργήσουν ως εκπαιδευτές των μαθημάτων σας. Θα κερδίσετε ένα πιστοποιητικό Coursera με την ολοκλήρωση του μαθήματος.
Ενίσχυση τεχνητής νοημοσύνης στην Python: Udemy
Εάν ασχολείστε με την χρηματοοικονομική αγορά ή το ψηφιακό μάρκετινγκ και θέλετε να αναπτύξετε έξυπνα πακέτα λογισμικού για τα εν λόγω πεδία, πρέπει να ελέγξετε αυτό Μάθημα Udemy στο RL. Εκτός από τις βασικές αρχές του RL, το εκπαιδευτικό περιεχόμενο θα σας καθοδηγήσει επίσης στο πώς να αναπτύξετε λύσεις RL για διαδικτυακή διαφήμιση και συναλλαγές μετοχών.

Μερικά αξιοσημείωτα θέματα που καλύπτει το μάθημα είναι:
- Μια επισκόπηση υψηλού επιπέδου του RL
- Δυναμικός Προγραμματισμός
- Μονέ Κάρλο
- Μέθοδοι Προσέγγισης
- Έργο διαπραγμάτευσης μετοχών με την RL
Πάνω από 42.000 μαθητές έχουν παρακολουθήσει το μάθημα μέχρι στιγμής. Ο διαδικτυακός πόρος εκμάθησης κατέχει επί του παρόντος βαθμολογία 4,6 αστέρων, η οποία είναι αρκετά εντυπωσιακή. Επιπλέον, το μάθημα στοχεύει στην εξυπηρέτηση μιας παγκόσμιας φοιτητικής κοινότητας, καθώς το εκπαιδευτικό περιεχόμενο είναι διαθέσιμο στα Γαλλικά, Αγγλικά, Ισπανικά, Γερμανικά, Ιταλικά και Πορτογαλικά.
Deep Reinforcement Learning στην Python: Udemy
Εάν έχετε περιέργεια και βασικές γνώσεις βαθιάς μάθησης και τεχνητής νοημοσύνης, μπορείτε να το δοκιμάσετε για προχωρημένους Μάθημα RL στην Python από το Udemy. Με βαθμολογία 4,6 αστέρων από μαθητές, είναι ένα ακόμη δημοφιλές μάθημα για την εκμάθηση RL στο πλαίσιο του AI/ML.

Το μάθημα αποτελείται από 12 ενότητες και καλύπτει τα ακόλουθα ζωτικά θέματα:
- OpenAI Gym και βασικές τεχνικές RL
- TD Λάμδα
- A3C
- Θεανώ Βασικά
- Βασικά Tensorflow
- Κωδικοποίηση Python για αρχάριους
Ολόκληρο το μάθημα θα απαιτήσει μια δεσμευμένη επένδυση 10 ωρών και 40 λεπτών. Εκτός από κείμενα, συνοδεύεται και από 79 συνεδρίες διαλέξεων ειδικών.
Deep Reinforcement Learning Expert: Udacity
Θέλετε να μάθετε προηγμένη μηχανική μάθηση από τους παγκόσμιους ηγέτες στο AI/ML όπως το Nvidia Deep Learning Institute και το Unity; Το Udacity σάς επιτρέπει να εκπληρώσετε το όνειρό σας. Ελέγξτε αυτό Βαθιά Ενισχυτική Μάθηση μάθημα για να γίνετε ειδικός σε ML.

Ωστόσο, πρέπει να προέρχεστε από ένα υπόβαθρο προηγμένης Python, ενδιάμεσων στατιστικών, θεωρίας πιθανοτήτων, TensorFlow, PyTorch και Keras.
Θα χρειαστεί επιμελής εκμάθηση έως και 4 μηνών για την ολοκλήρωση του μαθήματος. Κατά τη διάρκεια του μαθήματος, θα μάθετε ζωτικούς αλγόριθμους RL όπως Deep Deterministic Policy Gradients (DDPG), Deep Q-Networks (DQN) κ.λπ.
Τελικές Λέξεις
Η ενισχυτική μάθηση είναι το επόμενο βήμα στην ανάπτυξη της τεχνητής νοημοσύνης. Οργανισμοί ανάπτυξης τεχνητής νοημοσύνης και εταιρείες πληροφορικής πραγματοποιούν επενδύσεις σε αυτόν τον τομέα για να δημιουργήσουν αξιόπιστες και αξιόπιστες μεθοδολογίες εκπαίδευσης τεχνητής νοημοσύνης.
Αν και το RL έχει προχωρήσει πολύ, υπάρχουν περισσότερα πεδία ανάπτυξης. Για παράδειγμα, ξεχωριστοί πράκτορες RL δεν μοιράζονται τη γνώση μεταξύ τους. Επομένως, εάν εκπαιδεύετε μια εφαρμογή να οδηγεί αυτοκίνητο, η διαδικασία εκμάθησης θα γίνει αργή. Επειδή οι πράκτορες RL όπως η ανίχνευση αντικειμένων, οι αναφορές δρόμων κ.λπ., δεν θα μοιράζονται δεδομένα.
Υπάρχουν ευκαιρίες να επενδύσετε τη δημιουργικότητά σας και την τεχνογνωσία σας σε ML σε τέτοιες προκλήσεις. Η εγγραφή σε διαδικτυακά μαθήματα θα σας βοηθήσει να βελτιώσετε τις γνώσεις σας για προηγμένες μεθόδους RL και τις εφαρμογές τους σε έργα πραγματικού κόσμου.
Μια άλλη σχετική μάθηση για εσάς είναι οι διαφορές μεταξύ AI, Machine Learning και Deep Learning.