
Με τα χρόνια, η χρήση του python για την επιστήμη δεδομένων έχει αυξηθεί απίστευτα και συνεχίζει να αυξάνεται καθημερινά.
Η επιστήμη των δεδομένων είναι ένα τεράστιο πεδίο μελέτης με πολλά υποπεδία, εκ των οποίων η ανάλυση δεδομένων είναι αναμφισβήτητα ένα από τα πιο σημαντικά από όλα αυτά τα πεδία, και ανεξάρτητα από το επίπεδο δεξιοτήτων του ατόμου στην επιστήμη των δεδομένων, έχει γίνει όλο και πιο σημαντικό να κατανοήσει ή έχουν τουλάχιστον βασικές γνώσεις για αυτό.
Πίνακας περιεχομένων
Τι είναι η Ανάλυση Δεδομένων;
Η ανάλυση δεδομένων είναι ο καθαρισμός και ο μετασχηματισμός μεγάλου όγκου αδόμητων ή μη οργανωμένων δεδομένων, με στόχο τη δημιουργία βασικών γνώσεων και πληροφοριών σχετικά με αυτά τα δεδομένα που θα βοηθούσαν στη λήψη τεκμηριωμένων αποφάσεων.
Υπάρχουν διάφορα εργαλεία που χρησιμοποιούνται για την ανάλυση δεδομένων, Python, Microsoft Excel, Tableau, SaS, κ.λπ., αλλά σε αυτό το άρθρο, θα εστιάσουμε στον τρόπο με τον οποίο γίνεται η ανάλυση δεδομένων στην python. Πιο συγκεκριμένα, πώς γίνεται με μια βιβλιοθήκη python που ονομάζεται Πάντα.
Τι είναι το Pandas;
Το Pandas είναι μια βιβλιοθήκη Python ανοιχτού κώδικα που χρησιμοποιείται για χειρισμό δεδομένων και διαμάχη. Είναι γρήγορο και εξαιρετικά αποδοτικό και διαθέτει εργαλεία για τη φόρτωση πολλών ειδών δεδομένων στη μνήμη. Μπορεί να χρησιμοποιηθεί για την αναμόρφωση, την επισήμανση φέτας, την ευρετηρίαση ή ακόμα και την ομαδοποίηση πολλών μορφών δεδομένων.
Δομές δεδομένων στα Pandas
Υπάρχουν 3 δομές δεδομένων στα Pandas, και συγκεκριμένα.
Ο καλύτερος τρόπος για να διαφοροποιήσετε τα τρία από αυτά είναι να δείτε το ένα να περιέχει πολλές στοίβες του άλλου. Έτσι, ένα DataFrame είναι μια στοίβα από σειρές και ένα Panel είναι μια στοίβα DataFrames.
Μια σειρά είναι ένας μονοδιάστατος πίνακας
Μια στοίβα πολλών σειρών δημιουργεί ένα δισδιάστατο DataFrame
Μια στοίβα πολλών DataFrames δημιουργεί ένα τρισδιάστατο πάνελ
Η δομή δεδομένων με την οποία θα εργαζόμασταν περισσότερο είναι το δισδιάστατο DataFrame, το οποίο μπορεί επίσης να είναι το προεπιλεγμένο μέσο αναπαράστασης για ορισμένα σύνολα δεδομένων που μπορεί να συναντήσουμε.
Ανάλυση δεδομένων σε Pandas
Για αυτό το άρθρο, δεν απαιτείται εγκατάσταση. Θα χρησιμοποιούσαμε ένα εργαλείο που ονομάζεται συνεργατικό δημιουργήθηκε από την Google. Είναι ένα διαδικτυακό περιβάλλον python για Ανάλυση Δεδομένων, Μηχανική Μάθηση και AI. Είναι απλώς ένα φορητό υπολογιστή Jupyter που βασίζεται σε σύννεφο και έρχεται προεγκατεστημένο με σχεδόν κάθε πακέτο python που θα χρειαστείτε ως επιστήμονας δεδομένων.
Τώρα, προχωρήστε https://colab.research.google.com/notebooks/intro.ipynb. Θα πρέπει να δείτε το παρακάτω.
Στην επάνω αριστερή πλευρά πλοήγησης, κάντε κλικ στην επιλογή αρχείου και κάντε κλικ στην επιλογή “νέο σημειωματάριο”. Θα δείτε μια νέα σελίδα σημειωματάριου Jupyter φορτωμένη στο πρόγραμμα περιήγησής σας. Το πρώτο πράγμα που πρέπει να κάνουμε είναι να εισάγουμε πάντα τα πάντα στο εργασιακό μας περιβάλλον. Μπορούμε να το κάνουμε αυτό εκτελώντας τον ακόλουθο κώδικα.
import pandas as pd
Για αυτό το άρθρο, θα χρησιμοποιούσαμε ένα σύνολο δεδομένων τιμών κατοικίας για την ανάλυση των δεδομένων μας. Το σύνολο δεδομένων που θα χρησιμοποιούσαμε μπορεί να βρεθεί εδώ. Το πρώτο πράγμα που θα θέλαμε να κάνουμε είναι να φορτώσουμε αυτό το σύνολο δεδομένων στο περιβάλλον μας.
Μπορούμε να το κάνουμε αυτό με τον ακόλουθο κώδικα σε ένα νέο κελί.
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0 ', sep=',')
Το .read_csv χρησιμοποιείται όταν θέλουμε να διαβάσουμε ένα αρχείο CSV και περάσαμε μια ιδιότητα sep για να δείξουμε ότι το αρχείο CSV είναι οριοθετημένο με κόμμα.
Θα πρέπει επίσης να σημειώσουμε ότι το φορτωμένο αρχείο CSV μας αποθηκεύεται σε μια μεταβλητή df .
Δεν χρειάζεται να χρησιμοποιήσουμε τη συνάρτηση print() στο Jupyter Notebook. Μπορούμε απλώς να πληκτρολογήσουμε ένα όνομα μεταβλητής στο κελί μας και το Jupyter Notebook θα μας το εκτυπώσει.
Μπορούμε να το δοκιμάσουμε πληκτρολογώντας df σε ένα νέο κελί και εκτελώντας το, θα εκτυπώσει όλα τα δεδομένα στο σύνολο δεδομένων μας ως DataFrame για εμάς.
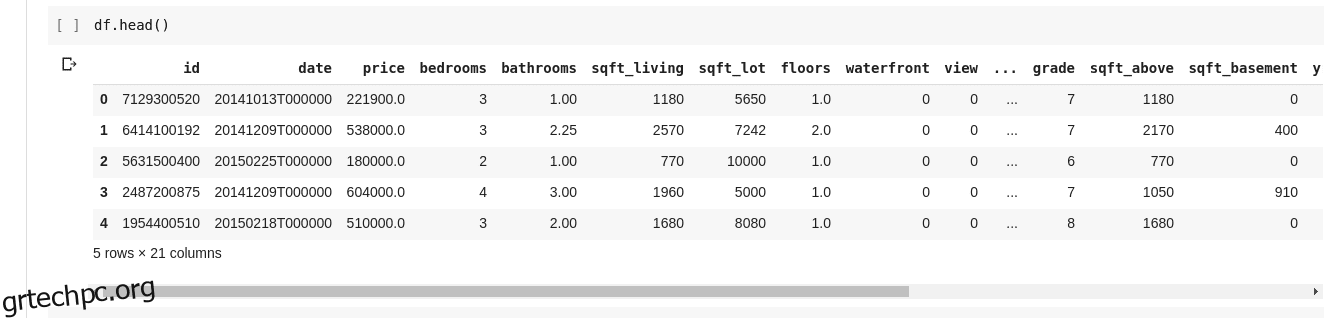
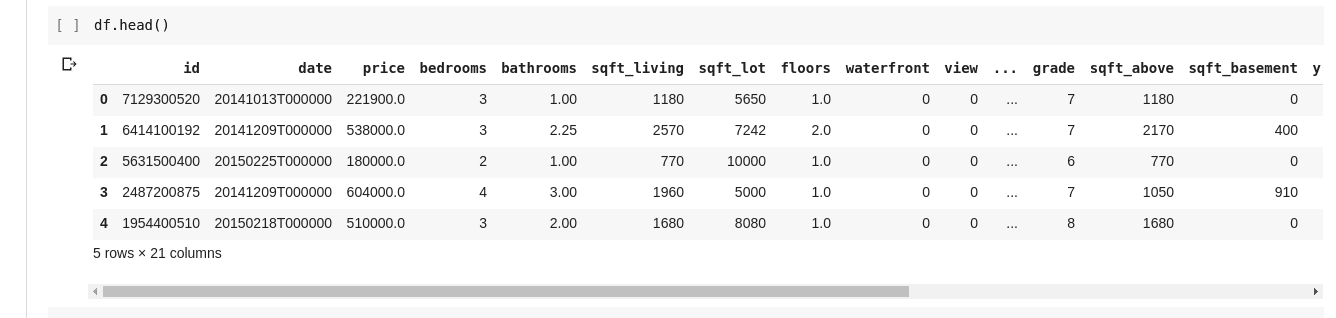
Αλλά δεν θέλουμε πάντα να βλέπουμε όλα τα δεδομένα, μερικές φορές θέλουμε απλώς να δούμε τα πρώτα λίγα δεδομένα και τα ονόματα των στηλών τους. Μπορούμε να χρησιμοποιήσουμε τη συνάρτηση df.head() για να εκτυπώσουμε τις πρώτες πέντε στήλες και df.tail() για να εκτυπώσουμε τις τελευταίες πέντε. Η έξοδος ενός από τα δύο θα φαινόταν ως τέτοια.
Θα θέλαμε να ελέγξουμε για σχέσεις μεταξύ αυτών των πολλών σειρών και στηλών δεδομένων. Η συνάρτηση .describe() κάνει ακριβώς αυτό για εμάς.
Η εκτέλεση της df.describe() δίνει την ακόλουθη έξοδο.
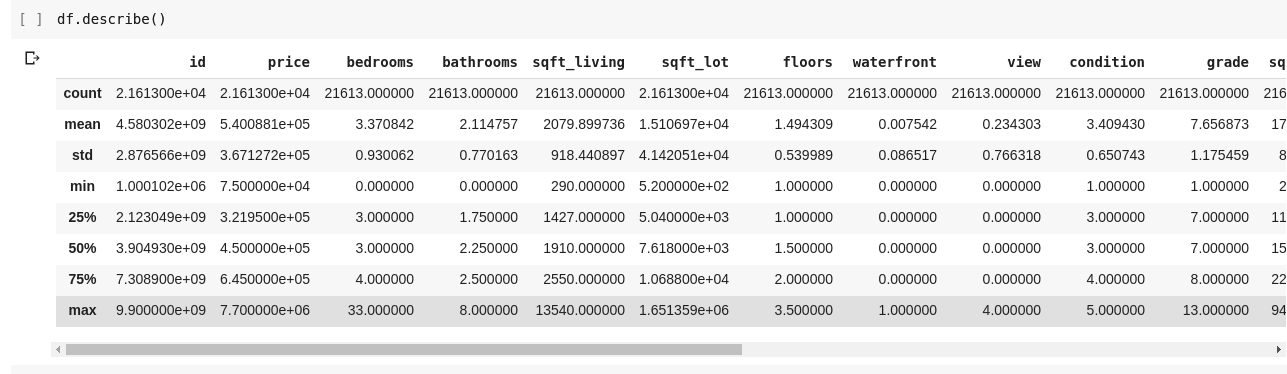
Μπορούμε να δούμε αμέσως ότι η .describe() δίνει τη μέση τιμή, την τυπική απόκλιση, τις ελάχιστες και μέγιστες τιμές και τα εκατοστημόρια για κάθε στήλη στο DataFrame. Αυτό είναι ιδιαίτερα χρήσιμο.
Μπορούμε επίσης να ελέγξουμε το σχήμα του 2D DataFrame μας για να μάθουμε πόσες σειρές και στήλες έχει. Μπορούμε να το κάνουμε αυτό χρησιμοποιώντας το df.shape που επιστρέφει μια πλειάδα στη μορφή (γραμμές, στήλες).
Μπορούμε επίσης να ελέγξουμε τα ονόματα όλων των στηλών στο DataFrame μας χρησιμοποιώντας το df.columns.
Τι γίνεται αν θέλουμε να επιλέξουμε μόνο μία στήλη και να επιστρέψουμε όλα τα δεδομένα σε αυτήν; Αυτό γίνεται με τρόπο παρόμοιο με τον τεμαχισμό ενός λεξικού. Πληκτρολογήστε τον παρακάτω κώδικα σε ένα νέο κελί και εκτελέστε τον
df['price ']
Ο παραπάνω κωδικός επιστρέφει τη στήλη τιμής, μπορούμε να προχωρήσουμε περαιτέρω αποθηκεύοντάς τον σε μια νέα μεταβλητή ως τέτοια
price = df['price']
Τώρα μπορούμε να εκτελέσουμε κάθε άλλη ενέργεια που μπορεί να εκτελεστεί σε ένα DataFrame στη μεταβλητή τιμής μας, καθώς είναι απλώς ένα υποσύνολο ενός πραγματικού DataFrame. Μπορούμε να κάνουμε πράγματα όπως df.head(), df.shape κ.λπ..
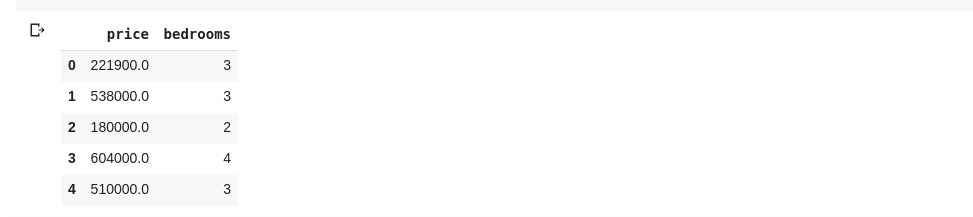
Θα μπορούσαμε επίσης να επιλέξουμε πολλές στήλες περνώντας μια λίστα ονομάτων στηλών στο df ως τέτοια
data = df[['price ', 'bedrooms']]
Το παραπάνω επιλέγει στήλες με ονόματα “τιμή” και “υπνοδωμάτια”, εάν πληκτρολογήσουμε data.head() σε ένα νέο κελί, θα έχουμε τα εξής
Ο παραπάνω τρόπος τεμαχισμού στηλών επιστρέφει όλα τα στοιχεία γραμμής σε αυτήν τη στήλη, τι γίνεται αν θέλουμε να επιστρέψουμε ένα υποσύνολο γραμμών και ένα υποσύνολο στηλών από το σύνολο δεδομένων μας; Αυτό μπορεί να γίνει χρησιμοποιώντας .iloc και ευρετηριάζεται με τρόπο παρόμοιο με τις λίστες python. Έτσι μπορούμε να κάνουμε κάτι σαν
df.iloc[50: , 3]
Το οποίο επιστρέφει την 3η στήλη από την 50η σειρά μέχρι το τέλος. Είναι αρκετά προσεγμένο και ακριβώς το ίδιο με το να κόβεις λίστες σε python.
Τώρα ας κάνουμε μερικά πραγματικά ενδιαφέροντα πράγματα, το σύνολο δεδομένων τιμών κατοικίας έχει μια στήλη που μας λέει την τιμή ενός σπιτιού και μια άλλη στήλη μας λέει τον αριθμό των υπνοδωματίων που έχει το συγκεκριμένο σπίτι. Η τιμή της κατοικίας είναι μια συνεχής τιμή, επομένως είναι πιθανό να μην έχουμε δύο σπίτια που έχουν την ίδια τιμή. Αλλά ο αριθμός των υπνοδωματίων είναι κάπως διακριτός, επομένως μπορούμε να έχουμε πολλά σπίτια με δύο, τρία, τέσσερα υπνοδωμάτια κ.λπ.
Τι γίνεται αν θέλουμε να πάρουμε όλα τα σπίτια με τον ίδιο αριθμό υπνοδωματίων και να βρούμε τη μέση τιμή κάθε ξεχωριστής κρεβατοκάμαρας; Είναι σχετικά εύκολο να γίνει αυτό στα πάντα, μπορεί να γίνει και ως τέτοιο.
df.groupby('bedrooms ')['price '].mean()
Τα παραπάνω αρχικά ομαδοποιούν το DataFrame με βάση τα σύνολα δεδομένων με τον ίδιο αριθμό κρεβατοκάμαρας χρησιμοποιώντας τη συνάρτηση df.groupby(), μετά του λέμε να μας δώσει μόνο τη στήλη κρεβατοκάμαρας και χρησιμοποιήστε τη συνάρτηση .mean() για να βρείτε τη μέση τιμή κάθε σπιτιού στο σύνολο δεδομένων .
Τι γίνεται αν θέλουμε να οπτικοποιήσουμε τα παραπάνω; Θα θέλαμε να μπορούμε να ελέγχουμε πώς ποικίλλει η μέση τιμή κάθε ξεχωριστού αριθμού κρεβατοκάμαρας; Απλώς πρέπει να συνδέσουμε τον προηγούμενο κώδικα σε μια συνάρτηση .plot() ως τέτοια.
df.groupby('bedrooms ')['price '].mean().plot()
Θα έχουμε ένα αποτέλεσμα που μοιάζει με αυτό.
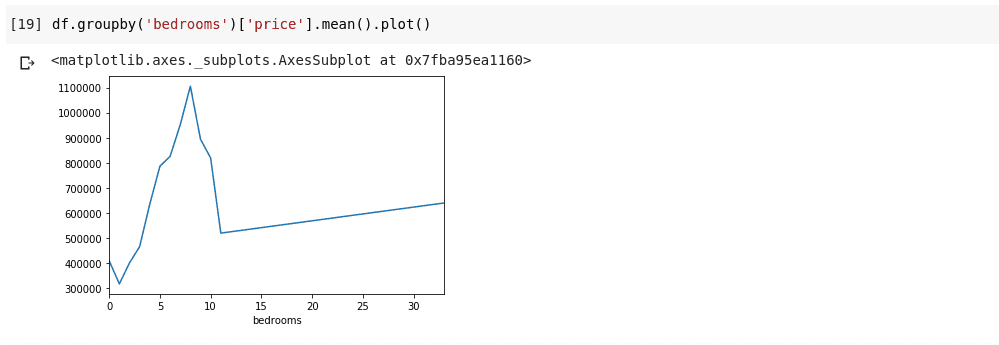
Τα παραπάνω μας δείχνουν κάποιες τάσεις στα δεδομένα. Στον οριζόντιο άξονα, έχουμε έναν ευδιάκριτο αριθμό υπνοδωματίων (Σημείωση, ότι περισσότερα από ένα σπίτια μπορούν να έχουν Χ αριθμό υπνοδωματίων), στον κάθετο άξονα, έχουμε τον μέσο όρο των τιμών σε σχέση με τον αντίστοιχο αριθμό υπνοδωματίων στην οριζόντια άξονας. Μπορούμε τώρα να παρατηρήσουμε αμέσως ότι τα σπίτια που έχουν από 5 έως 10 υπνοδωμάτια κοστίζουν πολύ περισσότερο από τα σπίτια με 3 υπνοδωμάτια. Θα γίνει επίσης προφανές ότι τα σπίτια που έχουν περίπου 7 ή 8 υπνοδωμάτια κοστίζουν πολύ περισσότερο από αυτά με 15, 20 ή και 30 δωμάτια.
Πληροφορίες όπως οι παραπάνω είναι ο λόγος που η ανάλυση δεδομένων είναι πολύ σημαντική, μπορούμε να εξάγουμε χρήσιμες πληροφορίες από τα δεδομένα που δεν είναι άμεσα ή εντελώς αδύνατο να παρατηρηθούν χωρίς ανάλυση.
Δεδομένα που λείπουν
Ας υποθέσουμε ότι συμμετέχω σε μια έρευνα που αποτελείται από μια σειρά ερωτήσεων. Μοιράζομαι έναν σύνδεσμο προς την έρευνα με χιλιάδες άτομα, ώστε να μπορούν να πουν τα σχόλιά τους. Ο απώτερος στόχος μου είναι να εκτελέσω ανάλυση δεδομένων σε αυτά τα δεδομένα, ώστε να μπορέσω να αποκτήσω κάποιες βασικές πληροφορίες από τα δεδομένα.
Τώρα πολλά θα μπορούσαν να πάνε στραβά, ορισμένοι τοπογράφοι μπορεί να αισθάνονται άβολα να απαντήσουν σε ορισμένες από τις ερωτήσεις μου και να το αφήσουν κενό. Πολλοί άνθρωποι θα μπορούσαν να κάνουν το ίδιο για πολλά μέρη των ερωτήσεων της έρευνάς μου. Αυτό μπορεί να μην θεωρηθεί πρόβλημα, αλλά φανταστείτε εάν επρόκειτο να συλλέξω αριθμητικά δεδομένα στην έρευνά μου και ένα μέρος της ανάλυσης απαιτούσε να πάρω είτε το άθροισμα, είτε το μέσο όρο είτε κάποια άλλη αριθμητική πράξη. Αρκετές τιμές που λείπουν θα οδηγούσαν σε πολλές ανακρίβειες στην ανάλυσή μου, πρέπει να βρω έναν τρόπο να βρω και να αντικαταστήσω αυτές τις τιμές που λείπουν με ορισμένες τιμές που θα μπορούσαν να είναι ένα κοντινό υποκατάστατό τους.
Τα Panda μας παρέχουν μια συνάρτηση για την εύρεση τιμών που λείπουν σε ένα DataFrame που ονομάζεται isnull().
Η συνάρτηση isnull() μπορεί να χρησιμοποιηθεί ως τέτοια.
df.isnull()
Αυτό επιστρέφει ένα DataFrame από booleans που μας λέει εάν τα δεδομένα που υπήρχαν αρχικά εκεί έλειπαν πραγματικά ή έλειπαν ψευδώς. Η έξοδος θα φαίνεται ως τέτοια.
Χρειαζόμαστε έναν τρόπο για να μπορέσουμε να αντικαταστήσουμε όλες αυτές τις τιμές που λείπουν, τις περισσότερες φορές η επιλογή των τιμών που λείπουν μπορεί να ληφθεί ως μηδέν. Μερικές φορές θα μπορούσε να ληφθεί ως ο μέσος όρος όλων των άλλων δεδομένων ή ίσως ο μέσος όρος των δεδομένων γύρω από αυτό, ανάλογα με τον επιστήμονα δεδομένων και την περίπτωση χρήσης των δεδομένων που αναλύονται.
Για να συμπληρώσουμε όλες τις τιμές που λείπουν σε ένα DataFrame, χρησιμοποιούμε τη συνάρτηση .fillna() που χρησιμοποιείται ως τέτοια.
df.fillna(0)
Στα παραπάνω, συμπληρώνουμε όλα τα κενά δεδομένα με τιμή μηδέν. Θα μπορούσε επίσης να είναι οποιοσδήποτε άλλος αριθμός που τον καθορίζουμε.
Η σημασία των δεδομένων δεν μπορεί να υπερτονιστεί, μας βοηθά να λαμβάνουμε απαντήσεις απευθείας από τα ίδια τα δεδομένα μας!. Η Ανάλυση Δεδομένων λένε ότι είναι το νέο Oil for Digital Economies.
Μπορείτε να βρείτε όλα τα παραδείγματα σε αυτό το άρθρο εδώ.
Για να μάθετε περισσότερα σε βάθος, ρίξτε μια ματιά Διαδικτυακό μάθημα Ανάλυση Δεδομένων με Python και Pandas.