

Το web scraping σάς επιτρέπει να συλλέγετε αποτελεσματικά μεγάλες ποσότητες δεδομένων από το Διαδίκτυο με πολύ γρήγορο τρόπο και είναι ιδιαίτερα χρήσιμο σε περιπτώσεις όπου οι ιστότοποι δεν εκθέτουν τα δεδομένα τους με δομημένο τρόπο μέσω της χρήσης Application Programming Interfaces (API).
Για παράδειγμα, φανταστείτε ότι δημιουργείτε μια εφαρμογή που συγκρίνει τις τιμές των αντικειμένων σε ιστότοπους ηλεκτρονικού εμπορίου. Πώς θα πήγαινες για αυτό; Ένας τρόπος είναι να ελέγξετε μόνοι σας την τιμή των αντικειμένων σε όλους τους ιστότοπους και να καταγράψετε τα ευρήματά σας. Ωστόσο, αυτός δεν είναι ένας έξυπνος τρόπος, καθώς υπάρχουν χιλιάδες προϊόντα σε πλατφόρμες ηλεκτρονικού εμπορίου και θα σας έπαιρνε πάντα για να εξαγάγετε σχετικά δεδομένα.
Ένας καλύτερος τρόπος για να γίνει αυτό είναι μέσω της απόσυρσης ιστού. Το web scraping είναι η διαδικασία αυτόματης εξαγωγής δεδομένων από ιστοσελίδες και ιστότοπους μέσω της χρήσης λογισμικού.
Τα σενάρια λογισμικού, που αναφέρονται ως web scrapers, χρησιμοποιούνται για την πρόσβαση σε ιστότοπους και την ανάκτηση δεδομένων από τους ιστότοπους. Τα δεδομένα που ανακτώνται, συνήθως σε μη δομημένη μορφή, μπορούν στη συνέχεια να αναλυθούν και να αποθηκευτούν με δομημένο τρόπο που έχει νόημα για τους χρήστες.
Η απόξεση ιστού είναι πολύ πολύτιμη στην εξαγωγή δεδομένων, καθώς παρέχει πρόσβαση σε πληθώρα δεδομένων και επιτρέπει την αυτοματοποίηση, έτσι ώστε να μπορείτε να προγραμματίσετε το σενάριο απόξεσης ιστού να εκτελείται σε συγκεκριμένες στιγμές ή ως απόκριση σε συγκεκριμένους κανόνες ενεργοποίησης. Η απόξεση ιστού σάς επιτρέπει επίσης να λαμβάνετε ενημερώσεις σε πραγματικό χρόνο και διευκολύνει τη διεξαγωγή έρευνας αγοράς.

Πολλές επιχειρήσεις και εταιρείες βασίζονται στο web scraping για την εξαγωγή δεδομένων για ανάλυση. Εταιρείες που ειδικεύονται στους ανθρώπινους πόρους, το ηλεκτρονικό εμπόριο, τα οικονομικά, τα ακίνητα, τα ταξίδια, τα μέσα κοινωνικής δικτύωσης και την έρευνα χρησιμοποιούν το web scraping για να εξάγουν σχετικά δεδομένα από ιστότοπους.
Η ίδια η Google χρησιμοποιεί την απόξεση ιστού για την ευρετηρίαση ιστότοπων στο Διαδίκτυο, ώστε να μπορεί να παρέχει σχετικά αποτελέσματα αναζήτησης στους χρήστες.
Ωστόσο, είναι σημαντικό να είστε προσεκτικοί κατά την απόσυρση ιστού. Παρόλο που η απόσυρση δεδομένων με πρόσβαση στο κοινό δεν είναι παράνομη, ορισμένοι ιστότοποι δεν επιτρέπουν την απόσυρση. Αυτό μπορεί να οφείλεται στο ότι έχουν ευαίσθητες πληροφορίες χρήστη, οι όροι παροχής υπηρεσιών τους απαγορεύουν ρητά την κατάργηση ιστού ή προστατεύουν την πνευματική ιδιοκτησία.
Επιπλέον, ορισμένοι ιστότοποι δεν επιτρέπουν την απόξεση ιστού, καθώς μπορεί να υπερφορτώσει τον διακομιστή του ιστότοπου και να οδηγήσει σε αυξημένο κόστος εύρους ζώνης, ειδικά όταν η απόξεση ιστού γίνεται σε μεγάλη κλίμακα.
Για να ελέγξετε εάν ένας ιστότοπος μπορεί να διαγραφεί, προσθέστε το robots.txt στη διεύθυνση URL του ιστότοπου. Το robots.txt χρησιμοποιείται για να υποδείξει στα bots ποια μέρη του ιστότοπου μπορούν να κοπούν. Για παράδειγμα, για να ελέγξετε αν μπορείτε να ξύσετε το Google, μεταβείτε στη διεύθυνση google.com/robots.txt
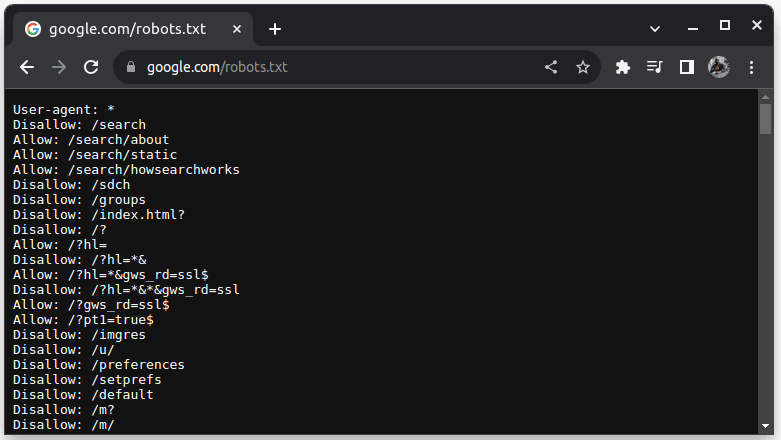
User-agent: * αναφέρεται σε όλα τα bots ή τα σενάρια λογισμικού και τα προγράμματα ανίχνευσης. Το Disallow χρησιμοποιείται για να πει στα ρομπότ ότι δεν μπορούν να έχουν πρόσβαση σε κανένα URL σε έναν κατάλογο, για παράδειγμα /search. Το Allow υποδεικνύει καταλόγους από τους οποίους μπορούν να έχουν πρόσβαση στις διευθύνσεις URL.
Ένα παράδειγμα ιστότοπου που δεν επιτρέπει την απόξεση είναι το LinkedIn. Για να ελέγξετε αν μπορείτε να ξύσετε το LinkedIn, μεταβείτε στη διεύθυνση linkedin.com/robots.txt
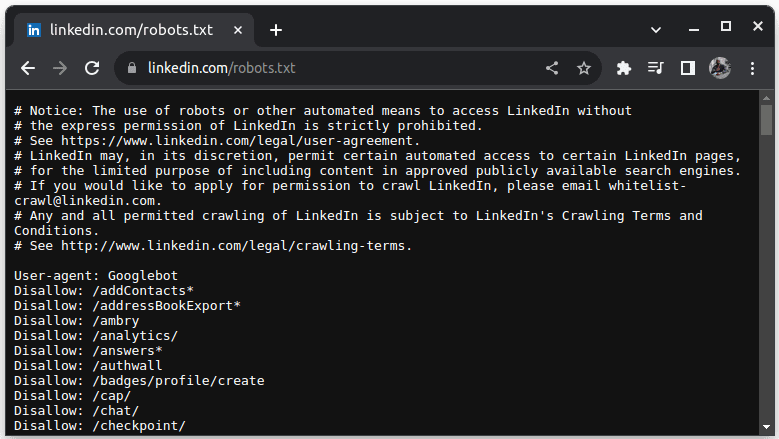
Όπως μπορείτε να δείτε, δεν επιτρέπεται να κάνετε scrape LinkedIn χωρίς την άδειά τους. Ελέγχετε πάντα εάν ένας ιστότοπος επιτρέπει την απόξεση για να αποφύγετε τυχόν νομικά ζητήματα.
Πίνακας περιεχομένων
Γιατί η Java είναι μια κατάλληλη γλώσσα για την απόξεση ιστού
Ενώ μπορείτε να δημιουργήσετε ένα web scraper με μια ποικιλία γλωσσών προγραμματισμού, η Java είναι ιδιαίτερα ιδανική για τη δουλειά για διάφορους λόγους. Πρώτον, η Java έχει πλούσιο οικοσύστημα και μεγάλη κοινότητα και παρέχει μια ποικιλία από βιβλιοθήκες απόξεσης ιστού, όπως JSoup, WebMagic και HTMLUnit, που διευκολύνουν τη σύνταξη web scrapers.

Παρέχει επίσης βιβλιοθήκες ανάλυσης HTML για την απλοποίηση της διαδικασίας εξαγωγής δεδομένων από έγγραφα HTML και βιβλιοθήκες δικτύωσης, όπως το HttpURLConnection για την υποβολή αιτημάτων σε διαφορετικές διευθύνσεις URL ιστότοπου.
Η ισχυρή υποστήριξη της Java για ταυτόχρονη χρήση και πολλαπλών νημάτων είναι επίσης ευεργετική για την απόσυρση ιστού, καθώς επιτρέπει την παράλληλη επεξεργασία και χειρισμό εργασιών απόξεσης ιστού με πολλαπλά αιτήματα, επιτρέποντάς σας να ξύνετε πολλές σελίδες ταυτόχρονα. Καθώς η επεκτασιμότητα είναι το βασικό πλεονέκτημα της Java, μπορείτε άνετα να ξύνετε ιστότοπους σε τεράστια κλίμακα χρησιμοποιώντας ένα web scraper γραμμένο σε Java.
Η υποστήριξη πολλαπλών πλατφορμών της Java είναι επίσης χρήσιμη, καθώς σας επιτρέπει να γράψετε ένα web scraper και να το εκτελέσετε σε οποιοδήποτε σύστημα διαθέτει συμβατή εικονική μηχανή Java. Επομένως, μπορείτε να γράψετε ένα web scraper σε ένα λειτουργικό σύστημα ή μια συσκευή και να το εκτελέσετε σε διαφορετικό λειτουργικό σύστημα χωρίς να χρειάζεται να τροποποιήσετε το web scraper.
Η Java μπορεί επίσης να χρησιμοποιηθεί με προγράμματα περιήγησης χωρίς κεφάλι, όπως το Headless Chrome, το HTML Unit, το Headless Firefox και το PhantomJs, μεταξύ άλλων. Ένα πρόγραμμα περιήγησης χωρίς κεφάλι είναι ένα πρόγραμμα περιήγησης χωρίς γραφικό περιβάλλον χρήστη. Τα προγράμματα περιήγησης χωρίς κεφαλή μπορούν να προσομοιώσουν τις αλληλεπιδράσεις των χρηστών και είναι πολύ χρήσιμα κατά την απόξεση ιστότοπων που απαιτούν αλληλεπιδράσεις με τους χρήστες.
Για να τα περιορίσουμε όλα, η Java είναι μια πολύ δημοφιλής και ευρέως χρησιμοποιούμενη γλώσσα που υποστηρίζεται και μπορεί εύκολα να ενσωματωθεί με μια ποικιλία εργαλείων, όπως βάσεις δεδομένων και πλαίσια επεξεργασίας δεδομένων. Αυτό είναι επωφελές επειδή διασφαλίζει ότι καθώς αποκόπτετε δεδομένα, όλα τα εργαλεία που θα χρειαστείτε για την απόξεση, την επεξεργασία και την αποθήκευση των δεδομένων πιθανότατα υποστηρίζουν τη Java.
Ας δούμε πώς μπορούμε να χρησιμοποιήσουμε την Java για απόσυρση ιστού.
Java for Web Scraping: Προαπαιτούμενα
Για να χρησιμοποιήσετε την Java στο web scraping, θα πρέπει να πληρούνται οι ακόλουθες προϋποθέσεις:
1. Java – θα πρέπει να έχετε εγκαταστήσει την Java, κατά προτίμηση την πιο πρόσφατη έκδοση μακροπρόθεσμης υποστήριξης. Σε περίπτωση που δεν έχετε εγκαταστήσει Java, μεταβείτε στην εγκατάσταση Java για να μάθετε πώς να εγκαταστήσετε την Java στον υπολογιστή σας
2. Ολοκληρωμένο περιβάλλον ανάπτυξης (IDE) – Θα πρέπει να έχετε εγκατεστημένο ένα IDE στον υπολογιστή σας. Σε αυτό το σεμινάριο, θα χρησιμοποιήσουμε το IntelliJ IDEA, αλλά μπορείτε να χρησιμοποιήσετε οποιοδήποτε IDE που γνωρίζετε.
3. Maven – θα χρησιμοποιηθεί για τη διαχείριση εξαρτήσεων και για την εγκατάσταση μιας βιβλιοθήκης απόξεσης ιστού.
Σε περίπτωση που δεν έχετε εγκατεστημένο το Maven, μπορείτε να το εγκαταστήσετε ανοίγοντας το τερματικό και εκτελώντας:
sudo apt install maven
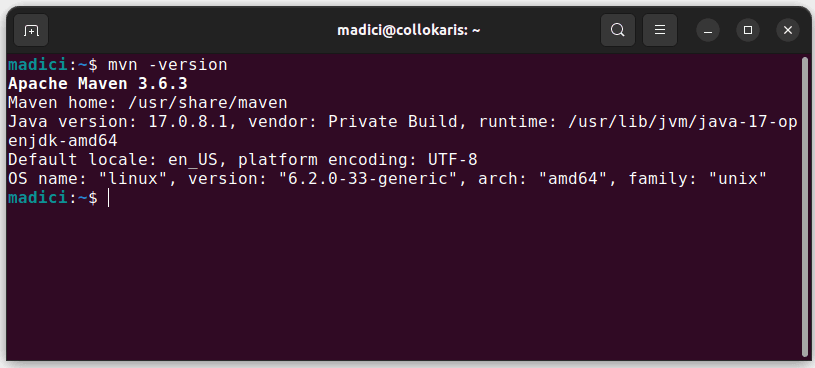
Αυτό εγκαθιστά το Maven από το επίσημο αποθετήριο. Μπορείτε να επιβεβαιώσετε ότι το Maven εγκαταστάθηκε με επιτυχία εκτελώντας:
mvn -version
Σε περίπτωση που η εγκατάσταση ήταν επιτυχής, θα πρέπει να λάβετε μια τέτοια έξοδο:
Ρύθμιση του περιβάλλοντος
Για να ρυθμίσετε το περιβάλλον σας:
1. Ανοίξτε το IntelliJ IDEA. Στην αριστερή γραμμή μενού, κάντε κλικ στο Έργα και, στη συνέχεια, επιλέξτε Νέο Έργο.
2. Στο παράθυρο Νέο Έργο που ανοίγει, συμπληρώστε το όπως φαίνεται παρακάτω. Βεβαιωθείτε ότι η Γλώσσα έχει οριστεί σε Java και το Build System σε Maven. Μπορείτε να δώσετε στο έργο όποιο όνομα προτιμάτε και, στη συνέχεια, χρησιμοποιήστε την τοποθεσία για να καθορίσετε το φάκελο στον οποίο θέλετε να δημιουργηθεί το Έργο. Μόλις τελειώσετε, κάντε κλικ στο Δημιουργία.
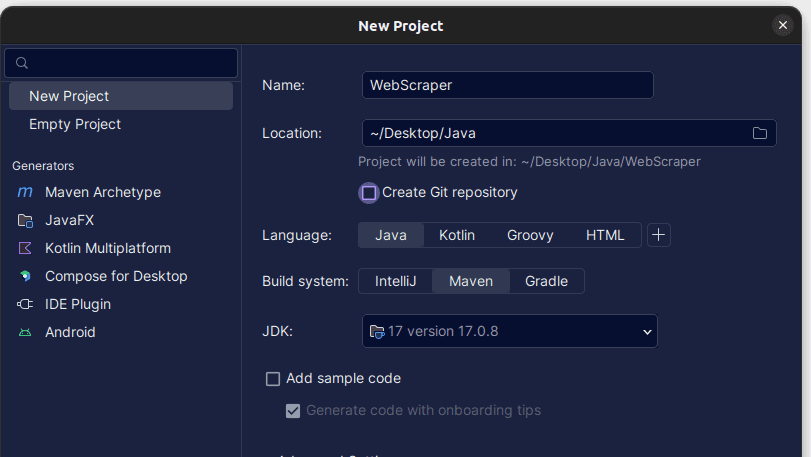
3. Μόλις δημιουργηθεί το έργο σας, θα πρέπει να έχετε ένα pom.xml στο έργο σας όπως φαίνεται παρακάτω.
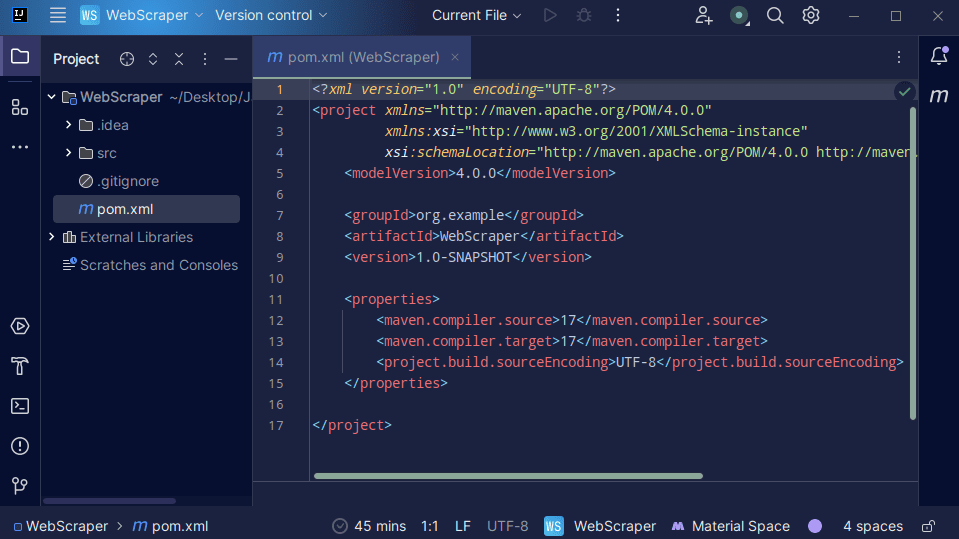
Το αρχείο pom.xml δημιουργείται από τον Maven και περιέχει πληροφορίες σχετικά με το έργο και τις λεπτομέρειες διαμόρφωσης που χρησιμοποιήθηκαν από τον Maven για την κατασκευή του έργου. Είναι αυτό το αρχείο που χρησιμοποιούμε επίσης για να υποδείξουμε ότι θα χρησιμοποιήσουμε εξωτερικές βιβλιοθήκες.
Κατά την κατασκευή ενός web scraper, θα χρησιμοποιήσουμε τη βιβλιοθήκη jsoup. Επομένως, πρέπει να το προσθέσουμε ως εξάρτηση στο αρχείο pom.xml, ώστε ο Maven να το κάνει διαθέσιμο στο έργο μας.
4. Προσθέστε εξάρτηση jsoup στο αρχείο pom.xml αντιγράφοντας τον παρακάτω κώδικα και προσθέτοντάς τον στο αρχείο pom.xml
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
Το αποτέλεσμα θα πρέπει να είναι όπως φαίνεται παρακάτω:
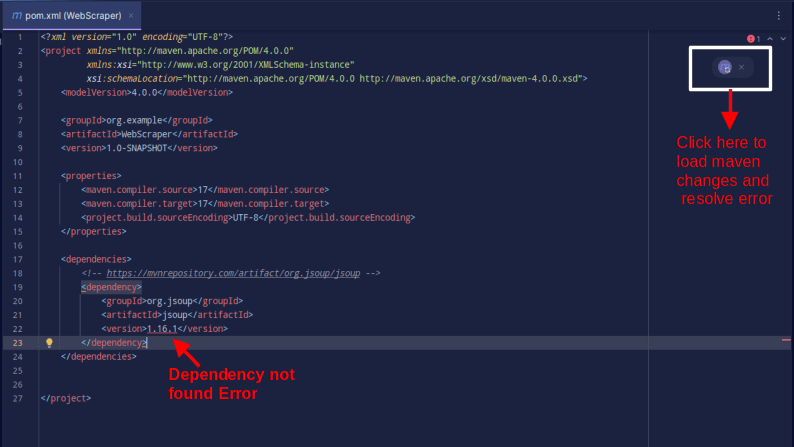
Σε περίπτωση που αντιμετωπίσετε ένα σφάλμα που λέει ότι η εξάρτηση δεν μπορεί να βρεθεί, κάντε κλικ στο εικονίδιο που υποδεικνύεται για να φορτώσει το Maven τις αλλαγές που έγιναν, να φορτώσει την εξάρτηση και να αφαιρέσει το σφάλμα.
Με αυτό, το περιβάλλον σας είναι πλήρως ρυθμισμένο.
Web Scraping με Java
Για την απόξεση ιστού, πρόκειται να αφαιρέσουμε δεδομένα από ScrapeThisSiteτο οποίο παρέχει ένα sandbox όπου οι προγραμματιστές μπορούν να εξασκήσουν το scraping ιστού χωρίς να αντιμετωπίζουν νομικά ζητήματα.
Για να ξύσετε έναν ιστότοπο χρησιμοποιώντας Java
1. Στην αριστερή γραμμή μενού στο IntelliJ, ανοίξτε τον κατάλογο src και μετά τον κύριο κατάλογο, ο οποίος βρίσκεται μέσα στον κατάλογο src. Ο κύριος κατάλογος περιέχει έναν κατάλογο που ονομάζεται java. κάντε δεξί κλικ πάνω του και επιλέξτε New, μετά Java Class
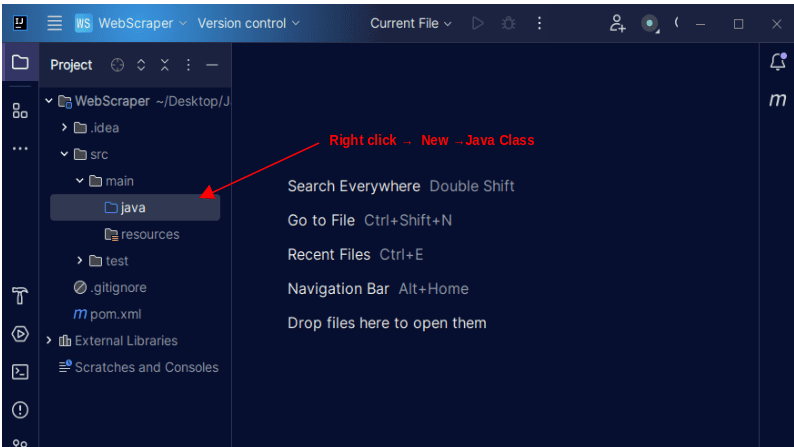
Δώστε στην τάξη όποιο όνομα θέλετε, όπως WebScraper και, στη συνέχεια, πατήστε Enter για να δημιουργήσετε μια νέα κλάση Java.
Ανοίξτε το πρόσφατα δημιουργημένο αρχείο που περιέχει τις κλάσεις Java που μόλις δημιουργήσατε.
2. Η απόξεση Ιστού περιλαμβάνει τη λήψη δεδομένων από ιστότοπους. Επομένως, πρέπει να καθορίσουμε τη διεύθυνση URL από την οποία θέλουμε να αφαιρέσουμε δεδομένα. Μόλις καθορίσουμε τη διεύθυνση URL, πρέπει να συνδεθούμε με τη διεύθυνση URL και να υποβάλουμε ένα αίτημα GET για να ανακτήσουμε το περιεχόμενο HTML της σελίδας.
Ο κώδικας που το κάνει αυτό φαίνεται παρακάτω:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Παραγωγή:
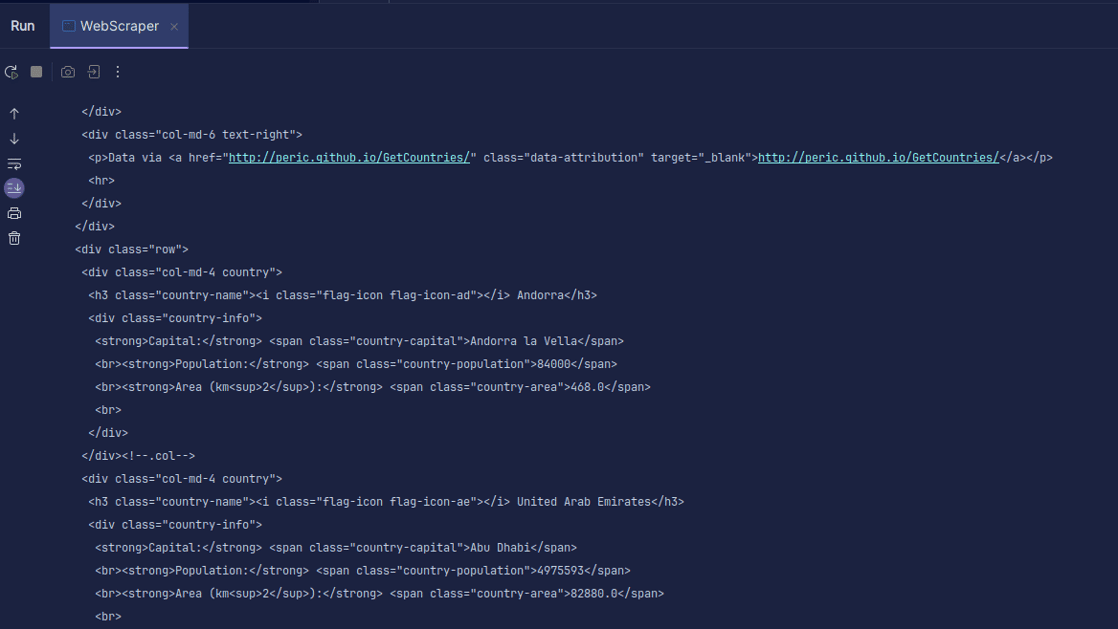
Όπως μπορείτε να δείτε, το HTML της σελίδας επιστρέφεται και είναι αυτό που εκτυπώνουμε. Κατά την απόξεση, η διεύθυνση URL που καθορίζετε μπορεί να έχει σφάλμα και ο πόρος που προσπαθείτε να ξύσετε μπορεί να μην υπάρχει καθόλου. Γι’ αυτό είναι σημαντικό να τυλίξουμε τον κώδικά μας σε μια δήλωση try-catch.
Η γραμμή:
Document doc = Jsoup.connect(url).get();
Χρησιμοποιείται για σύνδεση για σύνδεση με τη διεύθυνση URL που θέλετε να ξύσετε. Η μέθοδος get() χρησιμοποιείται για την υποβολή αιτήματος GET και την ανάκτηση του HTML στη σελίδα. Το αποτέλεσμα που επιστρέφεται αποθηκεύεται στη συνέχεια σε ένα αντικείμενο εγγράφου JSOUP, που ονομάζεται doc. Η αποθήκευση του αποτελέσματος σε ένα έγγραφο JSOUP σάς επιτρέπει να χρησιμοποιήσετε το JSOUP API για να χειριστείτε το επιστρεφόμενο HTML.
3. Πηγαίνετε στο ScrapeThisSite και επιθεωρήστε τη σελίδα. Στο HTML, θα πρέπει να δείτε τη δομή που φαίνεται παρακάτω:
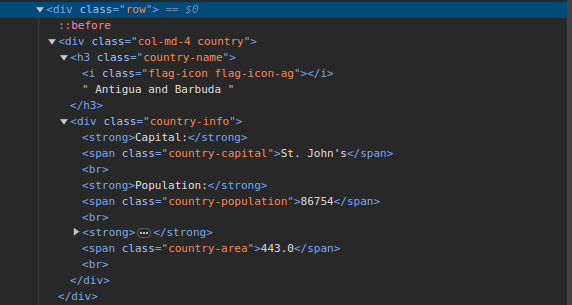
Σημειώστε ότι όλες οι χώρες στη σελίδα αποθηκεύονται σε παρόμοια δομή. Υπάρχει ένα div με μια κλάση που ονομάζεται χώρα με ένα στοιχείο h3 με μια κλάση ονόματος χώρας που περιέχει το όνομα κάθε χώρας στη σελίδα.
Μέσα στο κύριο div, υπάρχει ένα άλλο div με μια κατηγορία πληροφοριών χώρας και περιέχει πληροφορίες όπως πρωτεύουσα, πληθυσμό και περιοχή της χώρας. Μπορούμε να χρησιμοποιήσουμε αυτά τα ονόματα κλάσεων για να επιλέξουμε τα στοιχεία HTML και να εξαγάγουμε πληροφορίες από αυτά.
4. Εξάγετε συγκεκριμένο περιεχόμενο από το HTML της σελίδας χρησιμοποιώντας τις ακόλουθες γραμμές:
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " Population - " + population);
}
Χρησιμοποιούμε τη μέθοδο select() για να επιλέξουμε στοιχεία από το HTML της σελίδας που ταιριάζουν με τον συγκεκριμένο επιλογέα CSS που περνάμε. Στην περίπτωσή μας, περνάμε στα ονόματα των κλάσεων. Από την επιθεώρηση της σελίδας, είδαμε ότι όλες οι πληροφορίες χώρας στη σελίδα αποθηκεύονται σε ένα div με μια κατηγορία χώρας.
Κάθε χώρα έχει το δικό της div με μια κατηγορία χωρών και το div περιέχει πληροφορίες όπως το όνομα της χώρας, την πρωτεύουσα και τον πληθυσμό.
Επομένως, επιλέγουμε πρώτα όλες τις χώρες στη σελίδα χρησιμοποιώντας την κλάση .country. Στη συνέχεια, το αποθηκεύουμε σε μια μεταβλητή που ονομάζεται χώρες τύπου Elements, η οποία λειτουργεί ακριβώς όπως μια λίστα. Στη συνέχεια χρησιμοποιούμε έναν βρόχο για να περάσουμε από χώρες και να εξαγάγουμε το όνομα της χώρας, την πρωτεύουσα και τον πληθυσμό και να εκτυπώσουμε ό,τι βρέθηκε.
Ολόκληρη η βάση κώδικα μας φαίνεται παρακάτω:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Population - " + population);
}
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Παραγωγή:
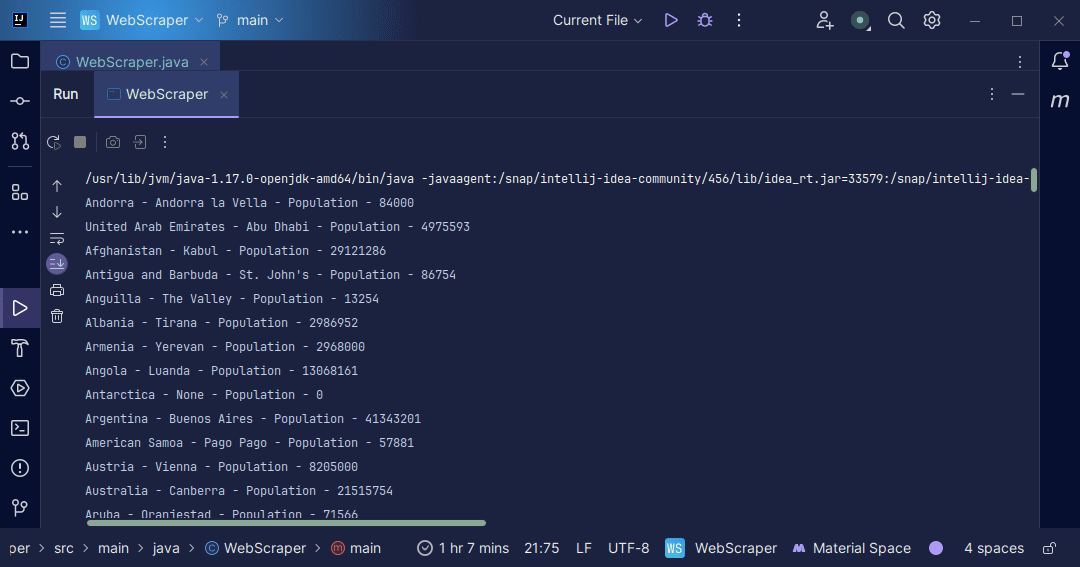
Με τις πληροφορίες που λαμβάνουμε πίσω από τη σελίδα, μπορούμε να κάνουμε διάφορα πράγματα, όπως να τα εκτυπώσουμε όπως μόλις κάναμε ή να τα αποθηκεύσουμε σε ένα αρχείο σε περίπτωση που θέλουμε να κάνουμε περαιτέρω επεξεργασία δεδομένων.
συμπέρασμα
Η απόξεση ιστού είναι ένας εξαιρετικός τρόπος εξαγωγής μη δομημένων δεδομένων από ιστότοπους, αποθήκευσης των δεδομένων με δομημένο τρόπο και επεξεργασίας των δεδομένων για εξαγωγή ουσιαστικών πληροφοριών. Ωστόσο, είναι σημαντικό να είστε προσεκτικοί κατά την απόξεση ιστού, καθώς ορισμένοι ιστότοποι δεν επιτρέπουν την απόξεση ιστού.
Για να είστε ασφαλείς, χρησιμοποιήστε ιστότοπους που παρέχουν sandboxes για να εξασκηθείτε στην απόσυρση. Διαφορετικά, ελέγχετε πάντα το robots.txt κάθε ιστότοπου που θέλετε να διαγράψετε για να μάθετε εάν ο ιστότοπος επιτρέπει τη διάλυση.
όταν γράφετε web scrapper, η Java είναι μια εξαιρετική γλώσσα καθώς παρέχει βιβλιοθήκες που κάνουν την απόξεση ιστού ευκολότερη και πιο αποτελεσματική. Ως προγραμματιστής Java, η δημιουργία ενός web scraper θα σας βοηθήσει να αναπτύξετε ακόμη περισσότερο τις προγραμματιστικές σας δεξιότητες. Συνεχίστε λοιπόν και γράψτε το δικό σας web scrapper ή τροποποιήστε αυτό που χρησιμοποιείται στο άρθρο για να εξαγάγετε διαφορετικά είδη πληροφοριών. Καλή κωδικοποίηση!
Μπορείτε επίσης να εξερευνήσετε μερικές δημοφιλείς λύσεις απόξεσης ιστού που βασίζονται στο Cloud.