
Το Support Vector Machine είναι από τους πιο δημοφιλείς αλγόριθμους Machine Learning. Είναι αποτελεσματικό και μπορεί να εκπαιδευτεί σε περιορισμένα σύνολα δεδομένων. Τι είναι όμως;
Πίνακας περιεχομένων
Τι είναι το Support Vector Machine (SVM);
Υποστήριξη διανυσματική μηχανή είναι ένας αλγόριθμος μηχανικής μάθησης που χρησιμοποιεί εποπτευόμενη μάθηση για να δημιουργήσει ένα μοντέλο για δυαδική ταξινόμηση. Αυτό είναι μια μπουκιά. Αυτό το άρθρο θα εξηγήσει το SVM και πώς σχετίζεται με την επεξεργασία φυσικής γλώσσας. Αλλά πρώτα, ας αναλύσουμε πώς λειτουργεί μια μηχανή διανύσματος υποστήριξης.
Πώς λειτουργεί το SVM;
Εξετάστε ένα απλό πρόβλημα ταξινόμησης όπου έχουμε δεδομένα που έχουν δύο χαρακτηριστικά, x και y, και μία έξοδο – μια ταξινόμηση που είναι είτε κόκκινη είτε μπλε. Μπορούμε να σχεδιάσουμε ένα φανταστικό σύνολο δεδομένων που μοιάζει με αυτό:
Με δεδομένα όπως αυτό, το καθήκον θα ήταν να δημιουργηθεί ένα όριο απόφασης. Ένα όριο απόφασης είναι μια γραμμή που χωρίζει τις δύο κατηγορίες των σημείων δεδομένων μας. Αυτό είναι το ίδιο σύνολο δεδομένων αλλά με ένα όριο απόφασης:
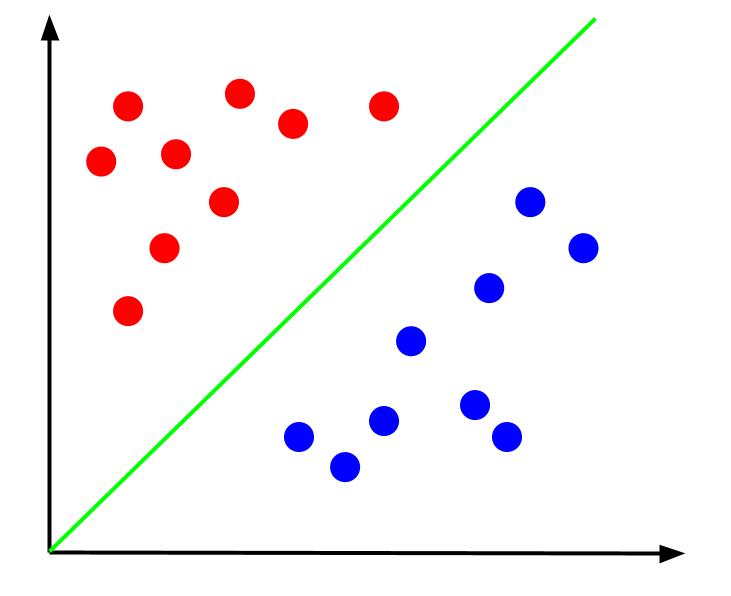
Με αυτό το όριο απόφασης, μπορούμε στη συνέχεια να κάνουμε προβλέψεις για την κατηγορία στην οποία ανήκει ένα σημείο δεδομένων, δεδομένου του σημείου που βρίσκεται σε σχέση με το όριο απόφασης. Ο αλγόριθμος Support Vector Machine δημιουργεί το καλύτερο όριο απόφασης που θα χρησιμοποιηθεί για την ταξινόμηση σημείων.
Τι εννοούμε όμως με τον όρο βέλτιστο όριο απόφασης;
Το καλύτερο όριο απόφασης μπορεί να υποστηριχθεί ότι είναι αυτό που μεγιστοποιεί την απόστασή του από οποιοδήποτε από τα διανύσματα υποστήριξης. Τα διανύσματα υποστήριξης είναι σημεία δεδομένων οποιασδήποτε κατηγορίας πλησιέστερα στην αντίθετη κλάση. Αυτά τα σημεία δεδομένων ενέχουν τον μεγαλύτερο κίνδυνο εσφαλμένης ταξινόμησης λόγω της εγγύτητάς τους με την άλλη κατηγορία.
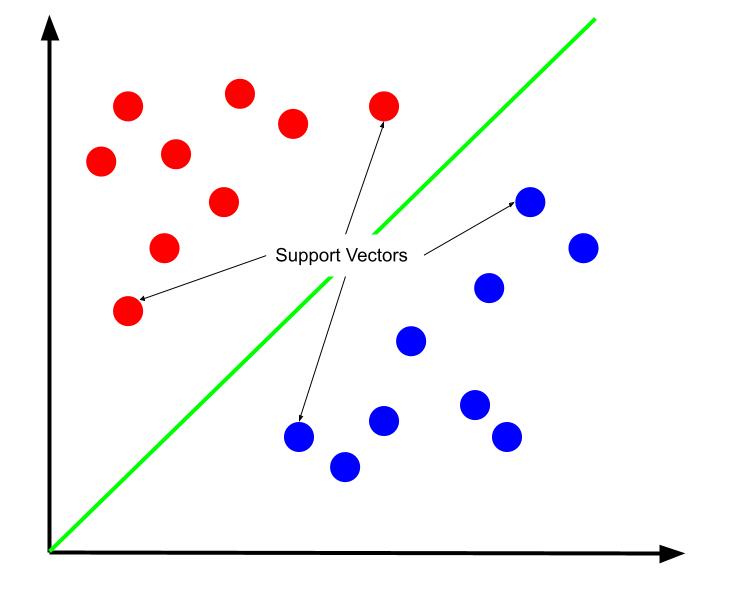
Επομένως, η εκπαίδευση μιας μηχανής φορέα υποστήριξης περιλαμβάνει την προσπάθεια εύρεσης μιας γραμμής που μεγιστοποιεί το περιθώριο μεταξύ των διανυσμάτων υποστήριξης.
Είναι επίσης σημαντικό να σημειωθεί ότι επειδή το όριο απόφασης είναι τοποθετημένο σε σχέση με τα διανύσματα υποστήριξης, είναι οι μόνοι καθοριστικοί παράγοντες της θέσης του ορίου απόφασης. Επομένως, τα άλλα σημεία δεδομένων είναι περιττά. Και έτσι, η εκπαίδευση απαιτεί μόνο τους φορείς υποστήριξης.
Σε αυτό το παράδειγμα, το όριο απόφασης που σχηματίζεται είναι μια ευθεία γραμμή. Αυτό συμβαίνει μόνο επειδή το σύνολο δεδομένων έχει μόνο δύο χαρακτηριστικά. Όταν το σύνολο δεδομένων έχει τρία χαρακτηριστικά, το όριο απόφασης που σχηματίζεται είναι ένα επίπεδο και όχι μια γραμμή. Και όταν έχει τέσσερα ή περισσότερα χαρακτηριστικά, το όριο απόφασης είναι γνωστό ως υπερεπίπεδο.
Μη Γραμμικά Διαχωρίσιμα Δεδομένα
Το παραπάνω παράδειγμα θεωρούσε πολύ απλά δεδομένα που, όταν σχεδιάζονται, μπορούν να διαχωριστούν από ένα γραμμικό όριο απόφασης. Εξετάστε μια διαφορετική περίπτωση όπου τα δεδομένα σχεδιάζονται ως εξής:
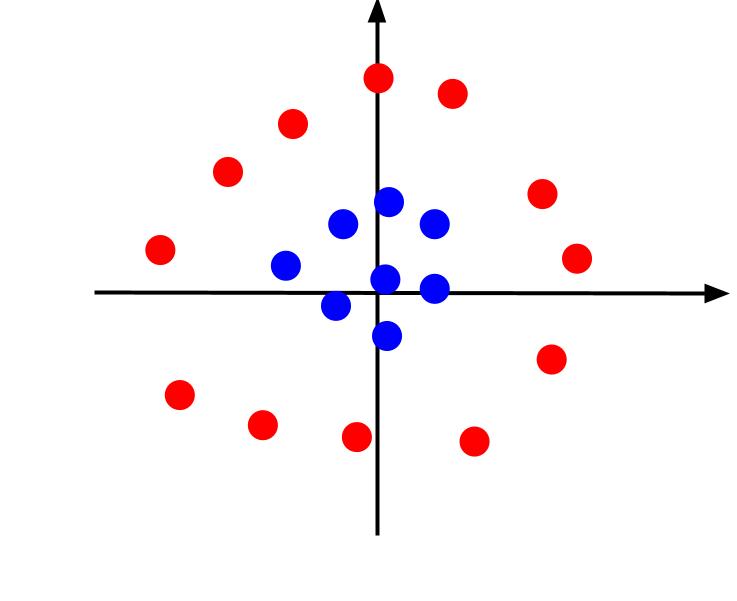
Σε αυτήν την περίπτωση, ο διαχωρισμός των δεδομένων χρησιμοποιώντας μια γραμμή είναι αδύνατος. Αλλά μπορεί να δημιουργήσουμε ένα άλλο χαρακτηριστικό, z. Και αυτό το χαρακτηριστικό μπορεί να οριστεί από την εξίσωση: z = x^2 + y^2. Μπορούμε να προσθέσουμε το z ως τρίτο άξονα στο επίπεδο για να το κάνουμε τρισδιάστατο.
Όταν κοιτάμε την τρισδιάστατη γραφική παράσταση από μια γωνία τέτοια ώστε ο άξονας x είναι οριζόντιος ενώ ο άξονας z κατακόρυφος, αυτή είναι η όψη που έχουμε κάτι που μοιάζει με αυτό:
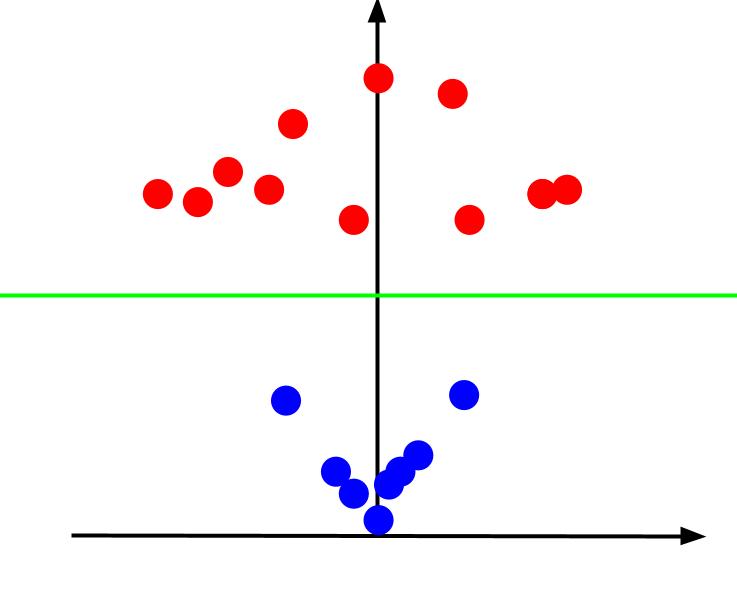
Η τιμή z αντιπροσωπεύει πόσο απέχει ένα σημείο από την αρχή σε σχέση με τα άλλα σημεία στο παλιό επίπεδο XY. Ως αποτέλεσμα, τα μπλε σημεία που είναι πιο κοντά στην αρχή έχουν χαμηλές τιμές z.
Ενώ τα κόκκινα σημεία πιο μακριά από την αρχή είχαν υψηλότερες τιμές z, η γραφική παράσταση τους έναντι των τιμών z μας δίνει μια σαφή ταξινόμηση που μπορεί να οριοθετηθεί από ένα γραμμικό όριο απόφασης, όπως φαίνεται.
Αυτή είναι μια ισχυρή ιδέα που χρησιμοποιείται σε Υποστήριξη Vector Machines. Γενικότερα, είναι η ιδέα της χαρτογράφησης των διαστάσεων σε μεγαλύτερο αριθμό διαστάσεων, έτσι ώστε τα σημεία δεδομένων να μπορούν να διαχωριστούν από ένα γραμμικό όριο. Οι συναρτήσεις που είναι υπεύθυνες για αυτό είναι οι λειτουργίες του πυρήνα. Υπάρχουν πολλές συναρτήσεις πυρήνα, όπως σιγμοειδές, γραμμικό, μη γραμμικό και RBF.
Για να γίνει πιο αποτελεσματική η χαρτογράφηση αυτών των χαρακτηριστικών, το SVM χρησιμοποιεί ένα τέχνασμα πυρήνα.
SVM στη Μηχανική Μάθηση
Το Support Vector Machine είναι ένας από τους πολλούς αλγόριθμους που χρησιμοποιούνται στη μηχανική εκμάθηση μαζί με δημοφιλείς όπως Decision Trees και Neural Networks. Ευνοείται επειδή λειτουργεί καλά με λιγότερα δεδομένα από άλλους αλγόριθμους. Συνήθως χρησιμοποιείται για να κάνει τα εξής:
- Ταξινόμηση κειμένου: Ταξινόμηση δεδομένων κειμένου όπως σχόλια και κριτικές σε μία ή περισσότερες κατηγορίες
- Ανίχνευση προσώπου: Ανάλυση εικόνων για ανίχνευση προσώπων για ενέργειες όπως προσθήκη φίλτρων για επαυξημένη πραγματικότητα
- Ταξινόμηση εικόνων: Οι μηχανές υποστήριξης διανυσμάτων μπορούν να ταξινομήσουν τις εικόνες αποτελεσματικά σε σύγκριση με άλλες προσεγγίσεις.
Το πρόβλημα ταξινόμησης κειμένων
Το Διαδίκτυο είναι γεμάτο με πολλά και πολλά δεδομένα κειμένου. Ωστόσο, πολλά από αυτά τα δεδομένα είναι αδόμητα και χωρίς ετικέτα. Για να χρησιμοποιήσετε καλύτερα αυτά τα δεδομένα κειμένου και να τα κατανοήσετε περισσότερο, υπάρχει ανάγκη ταξινόμησης. Παραδείγματα περιπτώσεων κατά τις οποίες το κείμενο ταξινομείται περιλαμβάνουν:
- Όταν τα tweets κατηγοριοποιούνται σε θέματα, ώστε οι άνθρωποι να μπορούν να ακολουθούν τα θέματα που θέλουν
- Όταν ένα μήνυμα ηλεκτρονικού ταχυδρομείου κατηγοριοποιείται ως Κοινωνικό, Προσφορές ή Ανεπιθύμητα
- Όταν τα σχόλια ταξινομούνται ως μίσους ή άσεμνα σε δημόσια φόρουμ
Πώς λειτουργεί το SVM με την ταξινόμηση φυσικής γλώσσας
Το Support Vector Machine χρησιμοποιείται για την ταξινόμηση κειμένου σε κείμενο που ανήκει σε ένα συγκεκριμένο θέμα και κείμενο που δεν ανήκει στο θέμα. Αυτό επιτυγχάνεται με την πρώτη μετατροπή και αναπαράσταση των δεδομένων κειμένου σε ένα σύνολο δεδομένων με πολλά χαρακτηριστικά.
Ένας τρόπος για να γίνει αυτό είναι δημιουργώντας δυνατότητες για κάθε λέξη στο σύνολο δεδομένων. Στη συνέχεια, για κάθε σημείο δεδομένων κειμένου, καταγράφετε πόσες φορές εμφανίζεται κάθε λέξη. Ας υποθέσουμε λοιπόν μοναδικές λέξεις που εμφανίζονται στο σύνολο δεδομένων. θα έχετε χαρακτηριστικά στο σύνολο δεδομένων.
Επιπλέον, θα παρέχετε ταξινομήσεις για αυτά τα σημεία δεδομένων. Ενώ αυτές οι ταξινομήσεις επισημαίνονται με κείμενο, οι περισσότερες υλοποιήσεις SVM αναμένουν αριθμητικές ετικέτες.
Επομένως, θα πρέπει να μετατρέψετε αυτές τις ετικέτες σε αριθμούς πριν από την προπόνηση. Μόλις προετοιμαστεί το σύνολο δεδομένων, χρησιμοποιώντας αυτές τις δυνατότητες ως συντεταγμένες, μπορείτε στη συνέχεια να χρησιμοποιήσετε ένα μοντέλο SVM για να ταξινομήσετε το κείμενο.
Δημιουργία SVM σε Python
Για να δημιουργήσετε μια μηχανή υποστήριξης διανυσμάτων (SVM) στην Python, μπορείτε να χρησιμοποιήσετε την κλάση SVC από τη βιβλιοθήκη sklearn.svm. Ακολουθεί ένα παράδειγμα για το πώς μπορείτε να χρησιμοποιήσετε την κλάση SVC για να δημιουργήσετε ένα μοντέλο SVM στην Python:
from sklearn.svm import SVC
# Load the dataset
X = ... y = ...
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19)
# Create an SVM model
model = SVC(kernel="linear")
# Train the model on the training data
model.fit(X_train, y_train)
# Evaluate the model on the test data
accuracy = model.score(X_test, y_test)
print("Accuracy: ", accuracy)
Σε αυτό το παράδειγμα, εισάγουμε πρώτα την κλάση SVC από τη βιβλιοθήκη sklearn.svm. Στη συνέχεια, φορτώνουμε το σύνολο δεδομένων και το χωρίζουμε σε σετ εκπαίδευσης και δοκιμών.
Στη συνέχεια, δημιουργούμε ένα μοντέλο SVM δημιουργώντας ένα αντικείμενο SVC και προσδιορίζοντας την παράμετρο του πυρήνα ως «γραμμική». Στη συνέχεια εκπαιδεύουμε το μοντέλο στα δεδομένα εκπαίδευσης χρησιμοποιώντας τη μέθοδο προσαρμογής και αξιολογούμε το μοντέλο στα δεδομένα δοκιμής χρησιμοποιώντας τη μέθοδο βαθμολογίας. Η μέθοδος score επιστρέφει την ακρίβεια του μοντέλου, το οποίο εκτυπώνουμε στην κονσόλα.
Μπορείτε επίσης να καθορίσετε άλλες παραμέτρους για το αντικείμενο SVC, όπως την παράμετρο C που ελέγχει την ισχύ της κανονικοποίησης και την παράμετρο γάμμα, η οποία ελέγχει τον συντελεστή πυρήνα για ορισμένους πυρήνες.
Οφέλη του SVM
Ακολουθεί μια λίστα με ορισμένα πλεονεκτήματα από τη χρήση μηχανών υποστήριξης διανυσμάτων (SVM):
- Αποτελεσματικά: Τα SVM είναι γενικά αποτελεσματικά στην εκπαίδευση, ειδικά όταν ο αριθμός των δειγμάτων είναι μεγάλος.
- Ισχυρό σε θόρυβο: Τα SVM είναι σχετικά ανθεκτικά στο θόρυβο στα δεδομένα εκπαίδευσης, καθώς προσπαθούν να βρουν τον ταξινομητή μέγιστου περιθωρίου, ο οποίος είναι λιγότερο ευαίσθητος στο θόρυβο από άλλους ταξινομητές.
- Memory Efficient: Τα SVM απαιτούν μόνο ένα υποσύνολο των δεδομένων εκπαίδευσης να είναι στη μνήμη ανά πάσα στιγμή, καθιστώντας τα πιο αποδοτικά στη μνήμη από άλλους αλγόριθμους.
- Αποτελεσματικά σε χώρους υψηλών διαστάσεων: Τα SVM εξακολουθούν να έχουν καλή απόδοση ακόμα και όταν ο αριθμός των χαρακτηριστικών υπερβαίνει τον αριθμό των δειγμάτων.
- Ευελιξία: Τα SVM μπορούν να χρησιμοποιηθούν για εργασίες ταξινόμησης και παλινδρόμησης και μπορούν να χειριστούν διάφορους τύπους δεδομένων, συμπεριλαμβανομένων γραμμικών και μη γραμμικών δεδομένων.
Τώρα, ας εξερευνήσουμε μερικούς από τους καλύτερους πόρους για την εκμάθηση του Support Vector Machine (SVM).
Πόροι μάθησης
Εισαγωγή στην υποστήριξη διανυσματικών μηχανών
Αυτό το βιβλίο για την Εισαγωγή στις Υποστήριξη Διανυσματικών Μηχανών σας εισάγει αναλυτικά και σταδιακά στις μεθόδους εκμάθησης που βασίζονται στον πυρήνα.
Σας δίνει μια σταθερή βάση στη θεωρία των Μηχανών Διανυσμάτων Υποστήριξης.
Εφαρμογές Υποστήριξης Vector Machines
Ενώ το πρώτο βιβλίο επικεντρώθηκε στη θεωρία των Υποστήριξης Διανυσματικών Μηχανών, αυτό το βιβλίο για τις Εφαρμογές Υποστήριξης Διανυσματικών Μηχανών εστιάζει στις πρακτικές τους εφαρμογές.
Εξετάζει πώς χρησιμοποιούνται τα SVM στην επεξεργασία εικόνας, στην ανίχνευση προτύπων και στην όραση υπολογιστή.
Υποστήριξη Vector Machines (Πληροφορική και Στατιστική)
Ο σκοπός αυτού του βιβλίου για τις Μηχανές Διανυσμάτων Υποστήριξης (Επιστήμη της Πληροφορίας και Στατιστική) είναι να παρέχει μια επισκόπηση των αρχών πίσω από την αποτελεσματικότητα των μηχανών διανυσμάτων υποστήριξης (SVM) σε διάφορες εφαρμογές.
Οι συγγραφείς επισημαίνουν αρκετούς παράγοντες που συμβάλλουν στην επιτυχία των SVM, όπως η ικανότητά τους να αποδίδουν καλά με περιορισμένο αριθμό ρυθμιζόμενων παραμέτρων, η αντοχή τους σε διάφορους τύπους σφαλμάτων και ανωμαλιών και η αποτελεσματική υπολογιστική τους απόδοση σε σύγκριση με άλλες μεθόδους.
Εκμάθηση με πυρήνες
Το “Learning with Kernels” είναι ένα βιβλίο που εισάγει τους αναγνώστες στην υποστήριξη διανυσματικών μηχανών (SVM) και σχετικών τεχνικών πυρήνα.
Έχει σχεδιαστεί για να παρέχει στους αναγνώστες μια βασική κατανόηση των μαθηματικών και τις γνώσεις που χρειάζονται για να αρχίσουν να χρησιμοποιούν αλγόριθμους πυρήνα στη μηχανική μάθηση. Το βιβλίο στοχεύει να παρέχει μια διεξοδική αλλά προσβάσιμη εισαγωγή στα SVM και τις μεθόδους πυρήνα.
Υποστήριξη Vector Machines with Sci-Kit Learn
Αυτό το διαδικτυακό μάθημα Support Vector Machines with Sci-kit Learn από το δίκτυο έργου Coursera διδάσκει πώς να εφαρμόσετε ένα μοντέλο SVM χρησιμοποιώντας τη δημοφιλή βιβλιοθήκη μηχανικής εκμάθησης, Sci-Kit Learn.

Επιπλέον, θα μάθετε τη θεωρία πίσω από τα SVM και θα προσδιορίσετε τα δυνατά και τα όριά τους. Το μάθημα είναι αρχαρίου και απαιτεί περίπου 2,5 ώρες.
Υποστήριξη διανυσματικών μηχανών στην Python: Έννοιες και κώδικας
Αυτό το διαδικτυακό μάθημα επί πληρωμή για το Support Vector Machines in Python από την Udemy έχει έως και 6 ώρες διδασκαλίας σε βίντεο και συνοδεύεται από πιστοποίηση.

Καλύπτει τα SVM και πώς μπορούν να εφαρμοστούν σταθερά στην Python. Επιπλέον, καλύπτει επιχειρηματικές εφαρμογές Υποστήριξης Διανυσματικών Μηχανών.
Machine Learning και AI: Υποστήριξη Vector Machines στην Python
Σε αυτό το μάθημα για τη Μηχανική Μάθηση και την Τεχνητή Νοημοσύνη, θα μάθετε πώς να χρησιμοποιείτε μηχανές διανυσμάτων υποστήριξης (SVM) για διάφορες πρακτικές εφαρμογές, συμπεριλαμβανομένης της αναγνώρισης εικόνας, της ανίχνευσης ανεπιθύμητων μηνυμάτων, της ιατρικής διάγνωσης και της ανάλυσης παλινδρόμησης.

Θα χρησιμοποιήσετε τη γλώσσα προγραμματισμού Python για να εφαρμόσετε μοντέλα ML για αυτές τις εφαρμογές.
Τελικές Λέξεις
Σε αυτό το άρθρο, μάθαμε εν συντομία για τη θεωρία πίσω από τις μηχανές διανυσμάτων υποστήριξης. Μάθαμε για την εφαρμογή τους στη Μηχανική Μάθηση και στην Επεξεργασία Φυσικής Γλώσσας.
Είδαμε επίσης πώς φαίνεται η υλοποίησή του με χρήση scikit-learn. Επιπλέον, μιλήσαμε για τις πρακτικές εφαρμογές και τα οφέλη των Υποστήριξης Διανυσματικών Μηχανών.
Αν και αυτό το άρθρο ήταν απλώς μια εισαγωγή, οι πρόσθετοι πόροι συνιστούσαν να μπείτε σε περισσότερες λεπτομέρειες, εξηγώντας περισσότερα σχετικά με τις μηχανές υποστήριξης διανυσμάτων. Δεδομένου του πόσο ευέλικτα και αποτελεσματικά είναι, τα SVM αξίζει να κατανοηθούν για να αναπτυχθούν ως επιστήμονας δεδομένων και μηχανικός ML.
Στη συνέχεια, μπορείτε να δείτε κορυφαία μοντέλα μηχανικής εκμάθησης.