

Σε αυτό το άρθρο, θα συζητήσουμε τη διανυσματοποίηση – μια τεχνική NLP και θα κατανοήσουμε τη σημασία της με έναν ολοκληρωμένο οδηγό για διαφορετικούς τύπους διανυσματοποίησης.
Έχουμε συζητήσει τις θεμελιώδεις έννοιες της προεπεξεργασίας NLP και του καθαρισμού κειμένου. Εξετάσαμε τα βασικά του NLP, τις διάφορες εφαρμογές του και τις τεχνικές του, όπως το tokenization, η κανονικοποίηση, η τυποποίηση και ο καθαρισμός κειμένου.

Πριν συζητήσουμε το Vectorization, ας αναθεωρήσουμε τι είναι το tokenization και πώς διαφέρει από το vectorization.
Πίνακας περιεχομένων
Τι είναι η Tokenization;
Tokenization είναι η διαδικασία διάσπασης των προτάσεων σε μικρότερες μονάδες που ονομάζονται tokens. Το Token βοηθά τους υπολογιστές να κατανοούν και να εργάζονται με το κείμενο εύκολα.
ΠΡΩΗΝ. “Αυτό το άρθρο είναι καλό”
Μαρτυρίες- [‘This’, ‘article’, ‘is’, ‘good’.]
Τι είναι η Vectorization;
Όπως γνωρίζουμε, τα μοντέλα μηχανικής εκμάθησης και οι αλγόριθμοι κατανοούν τα αριθμητικά δεδομένα. Η διανυσματοποίηση είναι μια διαδικασία μετατροπής κειμενικών ή κατηγορικών δεδομένων σε αριθμητικά διανύσματα. Μετατρέποντας δεδομένα σε αριθμητικά δεδομένα, μπορείτε να εκπαιδεύσετε το μοντέλο σας με μεγαλύτερη ακρίβεια.
Γιατί Χρειαζόμαστε Vectorization;
❇️ Το tokenization και η vectorization έχουν διαφορετική σημασία στην επεξεργασία φυσικής γλώσσας (NPL). Το tokenization σπάει τις προτάσεις σε μικρά διακριτικά. Η διανυσματοποίηση το μετατρέπει σε αριθμητική μορφή, ώστε το μοντέλο υπολογιστή/ML να μπορεί να το κατανοήσει.
❇️ Η διανυσματοποίηση δεν είναι μόνο χρήσιμη για τη μετατροπή της σε αριθμητική μορφή, αλλά επίσης χρήσιμη για την αποτύπωση σημασιολογικού νοήματος.
❇️ Η διανυσματοποίηση μπορεί να μειώσει τη διάσταση των δεδομένων και να τα κάνει πιο αποτελεσματικά. Αυτό θα μπορούσε να είναι πολύ χρήσιμο όταν εργάζεστε σε ένα μεγάλο σύνολο δεδομένων.
❇️ Πολλοί αλγόριθμοι μηχανικής μάθησης απαιτούν αριθμητική είσοδο, όπως τα νευρωνικά δίκτυα, έτσι ώστε η διανυσματοποίηση να μπορεί να μας βοηθήσει.
Υπάρχουν διάφοροι τύποι τεχνικών διανυσματοποίησης, τους οποίους θα κατανοήσουμε μέσα από αυτό το άρθρο.
Τσάντα με λέξεις
Εάν έχετε ένα σωρό έγγραφα ή προτάσεις και θέλετε να τα αναλύσετε, μια τσάντα λέξεων απλοποιεί αυτή τη διαδικασία αντιμετωπίζοντας το έγγραφο ως μια τσάντα που είναι γεμάτη λέξεις.
Η προσέγγιση της τσάντας λέξεων μπορεί να είναι χρήσιμη για την ταξινόμηση κειμένου, την ανάλυση συναισθημάτων και την ανάκτηση εγγράφων.
Ας υποθέσουμε ότι εργάζεστε σε πολλά κείμενα. Μια τσάντα με λέξεις θα σας βοηθήσει να αναπαραστήσετε δεδομένα κειμένου δημιουργώντας ένα λεξιλόγιο μοναδικών λέξεων στα δεδομένα κειμένου μας. Μετά τη δημιουργία λεξιλογίου, θα κωδικοποιήσει κάθε λέξη ως διάνυσμα με βάση τη συχνότητα (πόσο συχνά κάθε λέξη εμφανίζεται σε αυτό το κείμενο) αυτών των λέξεων.
Αυτά τα διανύσματα αποτελούνται από μη αρνητικούς αριθμούς (0,1,2…..) που αντιπροσωπεύουν τον αριθμό των συχνοτήτων σε αυτό το έγγραφο.
Ο σάκος των λέξεων περιλαμβάνει τρία βήματα:
Βήμα 1: Tokenization
Θα σπάσει τα έγγραφα σε μάρκες.
Πρώην – (Πρόταση: «I love Pizza and I love Burgers»)
Βήμα 2: Μοναδικός διαχωρισμός λέξεων/δημιουργία λεξιλογίου
Δημιουργήστε μια λίστα με όλες τις μοναδικές λέξεις που εμφανίζονται στις προτάσεις σας.
[“I”, “love”, “Pizza”, “and”, “Burgers”]
Βήμα 3: Καταμέτρηση εμφάνισης λέξης/δημιουργία διανύσματος
Αυτό το βήμα θα μετρήσει πόσες φορές κάθε λέξη επαναλαμβάνεται από το λεξιλόγιο και θα την αποθηκεύσει σε έναν αραιό πίνακα. Στον αραιό πίνακα, κάθε γραμμή σε ένα διάνυσμα πρότασης του οποίου το μήκος (οι στήλες του πίνακα) είναι ίσο με το μέγεθος του λεξιλογίου.
Εισαγωγή CountVetorizer
Θα εισαγάγουμε το CountVetorizer για να εκπαιδεύσουμε το μοντέλο Bag of words
from sklearn.feature_extraction.text import CountVectorizer
Δημιουργία Vectorizer
Σε αυτό το βήμα, θα δημιουργήσουμε το μοντέλο μας χρησιμοποιώντας το CountVetorizer και θα το εκπαιδεύσουμε χρησιμοποιώντας το δείγμα εγγράφου κειμένου.
# Sample text documents
documents = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
# Create a CountVectorizer
cv = CountVectorizer()
# Fit and Transform X = cv.fit_transform(documents)
Μετατροπή σε πυκνό πίνακα
Σε αυτό το βήμα, θα μετατρέψουμε τις παραστάσεις μας σε πυκνό πίνακα. Επίσης, θα λάβουμε ονόματα ή λέξεις χαρακτηριστικών.
# Get the feature names/words feature_names = vectorizer.get_feature_names_out() # Convert to dense array X_dense = X.toarray()
Ας εκτυπώσουμε τον πίνακα όρου του εγγράφου και τις λέξεις χαρακτηριστικών
# Print the DTM and feature names
print("Document-Term Matrix (DTM):")
print(X_dense)
print("\nFeature Names:")
print(feature_names)
Document – Term Matrix (DTM):
 Μήτρα
Μήτρα
Ονόματα χαρακτηριστικών:
 Χαρακτηριστικές λέξεις
Χαρακτηριστικές λέξεις
Όπως μπορείτε να δείτε, τα διανύσματα αποτελούνται από μη αρνητικούς αριθμούς (0,1,2……) που αντιπροσωπεύει τη συχνότητα των λέξεων στο έγγραφο.
Έχουμε τέσσερα δείγματα εγγράφων κειμένου και έχουμε εντοπίσει εννέα μοναδικές λέξεις από αυτά τα έγγραφα. Αποθηκεύσαμε αυτές τις μοναδικές λέξεις στο λεξιλόγιό μας εκχωρώντας τους «Ονόματα χαρακτηριστικών».
Στη συνέχεια, το μοντέλο Bag of Words ελέγχει εάν η πρώτη μοναδική λέξη υπάρχει στο πρώτο μας έγγραφο. Εάν υπάρχει, εκχωρεί τιμή 1 διαφορετικά, εκχωρεί 0.
Εάν η λέξη εμφανίζεται πολλές φορές (π.χ. 2 φορές), εκχωρεί μια τιμή ανάλογα.
Για παράδειγμα, στο δεύτερο έγγραφο, η λέξη ‘document’ επαναλαμβάνεται δύο φορές, επομένως η τιμή της στον πίνακα θα είναι 2.
Αν θέλουμε μια μεμονωμένη λέξη ως χαρακτηριστικό στο κλειδί λεξιλογίου – αναπαράσταση Unigram.
n – γραμμάρια = Μονόγραμμα, διγράμματα…….κ.λπ.
Υπάρχουν πολλές βιβλιοθήκες όπως το scikit-learn για την εφαρμογή τσάντα λέξεων: Keras, Gensim και άλλες. Αυτό είναι απλό και μπορεί να είναι χρήσιμο σε διαφορετικές περιπτώσεις.
Όμως, το Bag of words είναι πιο γρήγορο αλλά έχει κάποιους περιορισμούς.
Για να λύσουμε αυτό το πρόβλημα μπορούμε να επιλέξουμε καλύτερες προσεγγίσεις, μία από αυτές είναι η TF-IDF. Ας καταλάβουμε αναλυτικά.
TF-IDF
Το TF-IDF ή Term Frequency – Αντίστροφη Συχνότητα Εγγράφου, είναι μια αριθμητική αναπαράσταση για τον προσδιορισμό της σημασίας των λέξεων στο έγγραφο.
Γιατί χρειαζόμαστε το TF-IDF πάνω από το Bag of Words;
Μια τσάντα λέξεων αντιμετωπίζει όλες τις λέξεις εξίσου και απλώς ασχολείται με τη συχνότητα των μοναδικών λέξεων στις προτάσεις. Το TF- IDF δίνει σημασία στις λέξεις σε ένα έγγραφο λαμβάνοντας υπόψη τόσο τη συχνότητα όσο και τη μοναδικότητα.
Οι λέξεις που επαναλαμβάνονται πολύ συχνά δεν υπερισχύουν των λιγότερο συχνών και πιο σημαντικών λέξεων.
TF: Η συχνότητα όρου μετρά πόσο σημαντική είναι μια λέξη σε μια μόνο πρόταση.
IDF: Η αντίστροφη συχνότητα εγγράφων μετρά πόσο σημαντική είναι μια λέξη σε ολόκληρη τη συλλογή εγγράφων.
TF = Συχνότητα λέξεων σε ένα έγγραφο / Συνολικός αριθμός λέξεων σε αυτό το έγγραφο
DF = Έγγραφο που περιέχει τη λέξη w / Συνολικός αριθμός εγγράφων
IDF = ημερολόγιο (Συνολικός αριθμός εγγράφων / Εγγράφων που περιέχουν τη λέξη w)
Το IDF είναι αμοιβαίο του DF. Ο λόγος πίσω από αυτό είναι ότι όσο πιο κοινή είναι η λέξη σε όλα τα έγγραφα, τόσο μικρότερη είναι η σημασία της στο τρέχον έγγραφο.
Τελική βαθμολογία TF-IDF: TF-IDF = TF * IDF
Είναι ένας τρόπος για να μάθετε ποιες λέξεις είναι κοινές σε ένα μόνο έγγραφο και μοναδικές σε όλα τα έγγραφα. Αυτές οι λέξεις μπορούν να είναι χρήσιμες για την εύρεση του κύριου θέματος του εγγράφου.
Για παράδειγμα,
Doc1 = “Λατρεύω τη μηχανική μάθηση”
Doc2 = “Λατρεύω το grtechpc.org”
Πρέπει να βρούμε τον πίνακα TF-IDF για τα έγγραφά μας.
Αρχικά, θα δημιουργήσουμε ένα λεξιλόγιο μοναδικών λέξεων.
Λεξιλόγιο = [“I,” “love,” “machine,” “learning,” “Geekflare”]
Έτσι, έχουμε 5 πέντε λέξεις. Ας βρούμε TF και IDF για αυτές τις λέξεις.
TF = Συχνότητα λέξεων σε ένα έγγραφο / Συνολικός αριθμός λέξεων σε αυτό το έγγραφο
TF:
- Για “I” = TF για Doc1: 1/4 = 0,25 και για Doc2: 1/3 ≈ 0,33
- Για “αγάπη”: TF για Doc1: 1/4 = 0,25 και για Doc2: 1/3 ≈ 0,33
- Για “Machine”: TF για Doc1: 1/4 = 0,25 και για Doc2: 0/3 ≈ 0
- Για “Learning”: TF για Doc1: 1/4 = 0,25 και για Doc2: 0/3 ≈ 0
- Για “grtechpc.org”: TF για Doc1: 0/4 = 0 και για Doc2: 1/3 ≈ 0,33
Τώρα, ας υπολογίσουμε το IDF.
IDF = ημερολόγιο (Συνολικός αριθμός εγγράφων / Εγγράφων που περιέχουν τη λέξη w)
IDF:
- Για το “I”: IDF είναι log(2/2) = 0
- Για “αγάπη”: IDF είναι log (2/2) = 0
- Για “Μηχανή”: IDF είναι log(2/1) = log(2) ≈ 0,69
- Για “Learning”: IDF είναι log(2/1) = log(2) ≈ 0,69
- Για “grtechpc.org”: IDF είναι log(2/1) = log(2) ≈ 0,69
Τώρα, ας υπολογίσουμε την τελική βαθμολογία του TF-IDF:
- Για “I”: TF-IDF για Doc1: 0,25 * 0 = 0 και TF-IDF για Doc2: 0,33 * 0 = 0
- Για “αγάπη”: TF-IDF για Έγγραφο 1: 0,25 * 0 = 0 και TF-IDF για Έγγραφο 2: 0,33 * 0 = 0
- Για “Machine”: TF-IDF για Doc1: 0,25 * 0,69 ≈ 0,17 και TF-IDF για Doc2: 0 * 0,69 = 0
- Για “Learning”: TF-IDF για Doc1: 0,25 * 0,69 ≈ 0,17 και TF-IDF για Doc2: 0 * 0,69 = 0
- Για “grtechpc.org”: TF-IDF για Doc1: 0 * 0,69 = 0 και TF-IDF για Doc2: 0,33 * 0,69 ≈ 0,23
Ο πίνακας TF-IDF μοιάζει με αυτό:
I love machine learning grtechpc.org Doc1 0.0 0.0 0.17 0.17 0.0 Doc2 0.0 0.0 0.0 0.0 0.23
Οι τιμές σε έναν πίνακα TF-IDF σας λένε πόσο σημαντικός είναι κάθε όρος σε κάθε έγγραφο. Οι υψηλές τιμές υποδηλώνουν ότι ένας όρος είναι σημαντικός σε ένα συγκεκριμένο έγγραφο, ενώ οι χαμηλές τιμές υποδηλώνουν ότι ο όρος είναι λιγότερο σημαντικός ή κοινός σε αυτό το πλαίσιο.
Το TF-IDF χρησιμοποιείται ως επί το πλείστον στην ταξινόμηση κειμένου, στη δημιουργία ανάκτησης πληροφοριών chatbot και στη σύνοψη κειμένου.
Εισαγωγή TfidfVetorizer
Ας εισάγουμε το TfidfVetorizer από το sklearn
from sklearn.feature_extraction.text import TfidfVectorizer
Δημιουργία Vectorizer
Όπως βλέπετε, θα δημιουργήσουμε το μοντέλο Tf Idf χρησιμοποιώντας το TfidfVetorizer.
# Sample text documents
text = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
# Create a TfidfVectorizer
cv = TfidfVectorizer()
Δημιουργία TF-IDF Matrix
Ας εκπαιδεύσουμε το μοντέλο μας παρέχοντας κείμενο. Μετά από αυτό, θα μετατρέψουμε τον αντιπροσωπευτικό πίνακα σε πυκνό πίνακα.
# Fit and transform to create the TF-IDF matrix X = cv.fit_transform(text)
# Get the feature names/words feature_names = vectorizer.get_feature_names_out() # Convert the TF-IDF matrix to a dense array for easier manipulation (optional) X_dense = X.toarray()
Εκτυπώστε το TF-IDF Matrix και Feature Words
# Print the TF-IDF matrix and feature words
print("TF-IDF Matrix:")
print(X_dense)
print("\nFeature Names:")
print(feature_names)
TF-IDF Matrix:
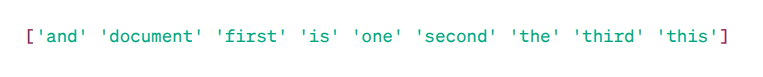 Χαρακτηριστικά Λέξεις
Χαρακτηριστικά Λέξεις
Όπως μπορείτε να δείτε, αυτοί οι ακέραιοι δεκαδικοί αριθμοί υποδεικνύουν τη σημασία των λέξεων σε συγκεκριμένα έγγραφα.
Επίσης, μπορείτε να συνδυάσετε λέξεις σε ομάδες των 2,3,4 και ούτω καθεξής χρησιμοποιώντας n-γραμμάρια.
Υπάρχουν και άλλες παράμετροι που μπορούμε να συμπεριλάβουμε: min_df, max_feature, subliner_tf, κ.λπ.
Μέχρι τώρα, έχουμε εξερευνήσει βασικές τεχνικές που βασίζονται στη συχνότητα.
Όμως, το TF-IDF δεν μπορεί να προσφέρει σημασιολογικό νόημα και κατανόηση του κειμένου.
Ας κατανοήσουμε πιο προηγμένες τεχνικές που έχουν αλλάξει τον κόσμο της ενσωμάτωσης λέξεων και ποιες είναι καλύτερες για το σημασιολογικό νόημα και την κατανόηση των συμφραζομένων.
Word2Vec
Το Word2vec είναι δημοφιλές ενσωμάτωση λέξης ( τύπος διανύσματος λέξης και χρήσιμος για την αποτύπωση σημασιολογικής και συντακτικής ομοιότητας) τεχνική στο NLP. Αυτό αναπτύχθηκε από τον Tomas Mikolov και την ομάδα του στη Google το 2013. Το Word2vec αντιπροσωπεύει τις λέξεις ως συνεχή διανύσματα σε έναν πολυδιάστατο χώρο.
Το Word2vec στοχεύει να αναπαραστήσει τις λέξεις με τρόπο που να συλλαμβάνει τη σημασιολογική τους σημασία. Τα διανύσματα λέξεων που δημιουργούνται από το word2vec τοποθετούνται σε έναν συνεχή διανυσματικό χώρο.
Πρώην – Τα διανύσματα «Γάτα» και «Σκύλος» θα ήταν πιο κοντά από τα διανύσματα «γάτας» και «κορίτσι».
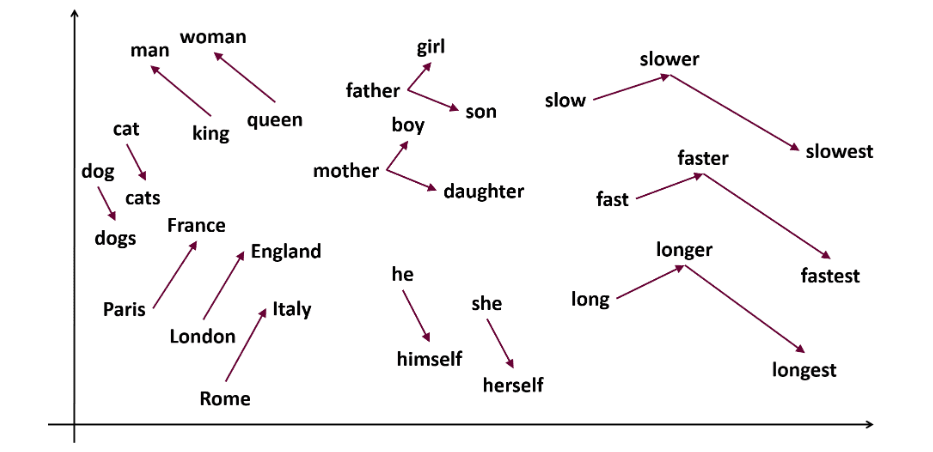 Πηγή: usna.edu
Πηγή: usna.edu
Δύο αρχιτεκτονικές μοντέλων μπορούν να χρησιμοποιηθούν από το word2vec για τη δημιουργία ενσωμάτωσης λέξεων.
CBOW: Ο συνεχής σάκος λέξεων ή το CBOW προσπαθεί να προβλέψει μια λέξη υπολογίζοντας τον μέσο όρο της σημασίας των κοντινών λέξεων. Παίρνει έναν σταθερό αριθμό ή παράθυρο λέξεων γύρω από τη λέξη-στόχο, στη συνέχεια τη μετατρέπει σε αριθμητική μορφή (Ενσωμάτωση), στη συνέχεια υπολογίζει τον μέσο όρο όλων και χρησιμοποιεί αυτόν τον μέσο όρο για να προβλέψει τη λέξη-στόχο με το νευρωνικό δίκτυο.
Πρώην πρόβλεψη στόχου: ‘Fox’
Λέξεις προτάσεων: “Το”, “γρήγορο”, “καφέ”, “άλματα”, “πάνω”, “το”
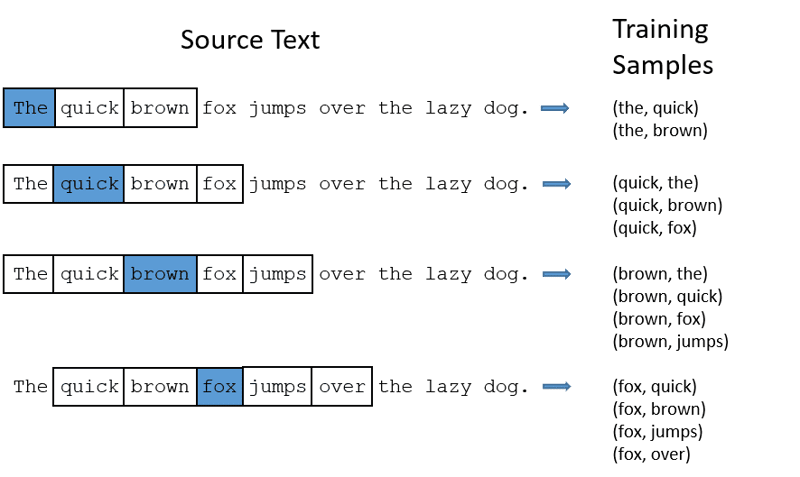 Word2Vec
Word2Vec
- Το CBOW παίρνει παράθυρο σταθερού μεγέθους (αριθμός) λέξεων όπως 2 (2 προς τα αριστερά και 2 προς τα δεξιά)
- Μετατροπή σε ενσωμάτωση λέξης.
- Το CBOW υπολογίζει τον μέσο όρο της λέξης ενσωμάτωσης.
- Το CBOW υπολογίζει τον μέσο όρο της λέξης που ενσωματώνεται στις λέξεις περιβάλλοντος.
- Το μέσο διάνυσμα προσπαθεί να προβλέψει μια λέξη-στόχο χρησιμοποιώντας ένα νευρωνικό δίκτυο.
Τώρα, ας καταλάβουμε πώς το skip-gram είναι διαφορετικό από το CBOW.
Skip-gram: Είναι ένα μοντέλο ενσωμάτωσης λέξης, αλλά λειτουργεί διαφορετικά. Αντί να προβλέπει τη λέξη-στόχο, το skip-gram προβλέπει τις λέξεις περιβάλλοντος που δίνονται στις λέξεις-στόχους.
Το Skip-grams είναι καλύτερο στην αποτύπωση των σημασιολογικών σχέσεων μεταξύ των λέξεων.
Πρώην «Βασιλιάς – Άνδρες + Γυναίκες = Βασίλισσα»
Εάν θέλετε να εργαστείτε με το Word2Vec, έχετε δύο επιλογές: είτε μπορείτε να εκπαιδεύσετε το δικό σας μοντέλο είτε να χρησιμοποιήσετε ένα προεκπαιδευμένο μοντέλο. Θα περάσουμε από ένα προεκπαιδευμένο μοντέλο.
Εισαγωγή gensim
Μπορείτε να εγκαταστήσετε το gensim χρησιμοποιώντας εγκατάσταση pip:
pip install gensim
Προσαρμόστε την πρόταση χρησιμοποιώντας το word_tokenize:
Αρχικά, θα μετατρέψουμε τις προτάσεις σε χαμηλότερες. Μετά από αυτό, θα κάνουμε tokenize τις προτάσεις μας χρησιμοποιώντας το word_tokenize.
# Import necessary libraries
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Sample sentences
sentences = [
"I love thor",
"Hulk is an important member of Avengers",
"Ironman helps Spiderman",
"Spiderman is one of the popular members of Avengers",
]
# Tokenize the sentences
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
Ας εκπαιδεύσουμε το μοντέλο μας:
Θα εκπαιδεύσουμε το μοντέλο μας παρέχοντας συμβολικές προτάσεις. Χρησιμοποιούμε 5 παράθυρα για αυτό το μοντέλο εκπαίδευσης, μπορείτε να προσαρμόσετε σύμφωνα με τις απαιτήσεις σας.
# Train a Word2Vec model
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, sg=0)
# Find similar words
similar_words = model.wv.most_similar("avengers")
# Print similar words
print("Similar words to 'avengers':")
for word, score in similar_words:
print(f"{word}: {score}")
Παρόμοιες λέξεις με τους «εκδικητές»:
 Ομοιότητα Word2Vec
Ομοιότητα Word2Vec
Αυτές είναι μερικές από τις λέξεις που μοιάζουν με τους “εκδικητές” με βάση το μοντέλο Word2Vec, μαζί με τους βαθμούς ομοιότητάς τους.
Το μοντέλο υπολογίζει μια βαθμολογία ομοιότητας (κυρίως ομοιότητα συνημίτονου) μεταξύ των διανυσμάτων λέξεων του «εκδικητές» και άλλων λέξεων στο λεξιλόγιό του. Η βαθμολογία ομοιότητας δείχνει πόσο στενά συνδέονται δύο λέξεις στο διανυσματικό χώρο.
Πρώην –
Εδώ, η λέξη «βοηθά» με ομοιότητα συνημιτόνου -0,005911458611011982 με τη λέξη «εκδικητές». Η αρνητική τιμή υποδηλώνει ότι μπορεί να είναι ανόμοια μεταξύ τους.
Οι τιμές ομοιότητας συνημιτονίου κυμαίνονται από -1 έως 1, όπου:
- Το 1 δείχνει ότι τα δύο διανύσματα είναι πανομοιότυπα και έχουν θετική ομοιότητα.
- Τιμές κοντά στο 1 δείχνουν υψηλή θετική ομοιότητα.
- Τιμές κοντά στο 0 δείχνουν ότι τα διανύσματα δεν σχετίζονται στενά.
- Τιμές κοντά στο -1 υποδηλώνουν υψηλή ανομοιότητα.
- Το -1 δείχνει ότι τα δύο διανύσματα είναι εντελώς αντίθετα και έχουν τέλεια αρνητική ομοιότητα.
Επισκεφθείτε αυτό Σύνδεσμος εάν θέλετε μια καλύτερη κατανόηση των μοντέλων word2vec και μια οπτική αναπαράσταση του τρόπου λειτουργίας τους. Είναι ένα πραγματικά υπέροχο εργαλείο για να δείτε το CBOW και το skip-gram σε δράση.
Παρόμοια με το Word2Vec, έχουμε το GloVe. Το GloVe μπορεί να παράγει ενσωματώσεις που απαιτούν λιγότερη μνήμη σε σύγκριση με το Word2Vec. Ας καταλάβουμε περισσότερα για το GloVe.
Γάντι
Τα καθολικά διανύσματα για την αναπαράσταση λέξεων (GloVe) είναι μια τεχνική όπως το word2vec. Χρησιμοποιείται για να αναπαραστήσει λέξεις ως διανύσματα σε συνεχή χώρο. Η ιδέα πίσω από το GloVe είναι η ίδια με αυτή του Word2Vec: παράγει ενσωματώσεις λέξεων με βάση τα συμφραζόμενα, ενώ λαμβάνει υπόψη την ανώτερη απόδοση του Word2Vec.
Γιατί χρειαζόμαστε το GloVe;
Το Word2vec είναι μια μέθοδος που βασίζεται σε παράθυρο και χρησιμοποιεί κοντινές λέξεις για να κατανοεί λέξεις. Αυτό σημαίνει ότι η σημασιολογική σημασία της λέξης-στόχου επηρεάζεται μόνο από τις περιβάλλουσες λέξεις σε προτάσεις, κάτι που αποτελεί αναποτελεσματική χρήση στατιστικών στοιχείων.
Ενώ το GloVe καταγράφει τόσο παγκόσμια όσο και τοπικά στατιστικά στοιχεία που συνοδεύουν την ενσωμάτωση λέξεων.
Πότε να χρησιμοποιήσετε το GloVe;
Χρησιμοποιήστε το GloVe όταν θέλετε ενσωμάτωση λέξης που αποτυπώνει ευρύτερες σημασιολογικές σχέσεις και καθολική συσχέτιση λέξεων.
Το GloVe είναι καλύτερο από άλλα μοντέλα σε εργασίες αναγνώρισης ονομαστικών οντοτήτων, αναλογία λέξεων και ομοιότητα λέξεων.
Πρώτα, πρέπει να εγκαταστήσουμε το Gensim:
pip install gensim
Βήμα 1: Θα εγκαταστήσουμε σημαντικές βιβλιοθήκες
# Import the required libraries import numpy as np import matplotlib.pyplot as plt from sklearn.manifold import TSNE import gensim.downloader as api
Βήμα 2: Εισαγωγή μοντέλου γαντιών
import gensim.downloader as api
glove_model = api.load('glove-wiki-gigaword-300')
Βήμα 3: Ανάκτηση διανυσματικής αναπαράστασης λέξης για τη λέξη “χαριτωμένο”
glove_model["cute"]
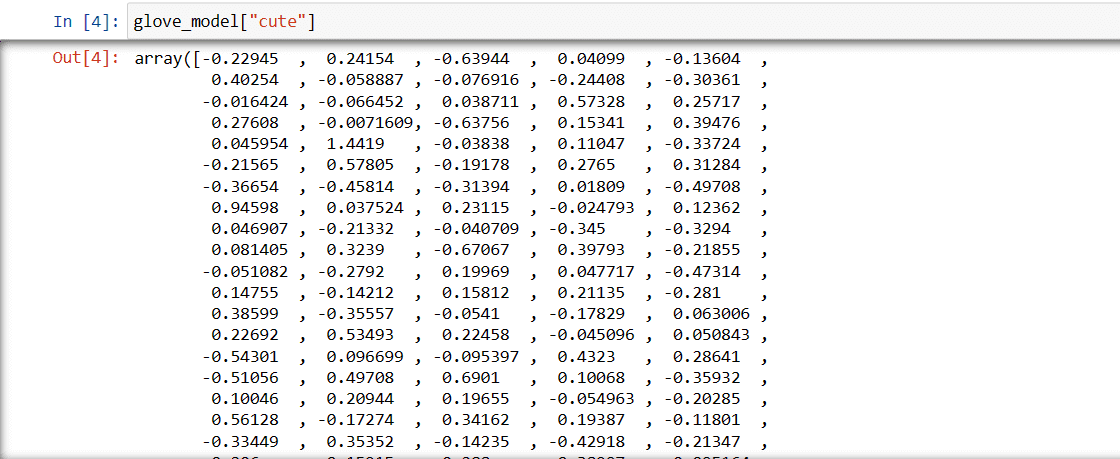 Διάνυσμα για τη λέξη “χαριτωμένο”
Διάνυσμα για τη λέξη “χαριτωμένο”
Αυτές οι αξίες αποτυπώνουν το νόημα της λέξης και τις σχέσεις με άλλες λέξεις. Οι θετικές τιμές υποδηλώνουν θετικές συσχετίσεις με ορισμένες έννοιες, ενώ οι αρνητικές τιμές υποδηλώνουν αρνητικές συσχετίσεις με άλλες έννοιες.
Σε ένα μοντέλο GloVe, κάθε διάσταση στο διάνυσμα λέξης αντιπροσωπεύει μια συγκεκριμένη πτυχή της σημασίας ή του πλαισίου της λέξης.
Οι αρνητικές και θετικές τιμές σε αυτές τις διαστάσεις συμβάλλουν στο πόσο σημασιολογικά σχετίζεται το «χαριτωμένο» με άλλες λέξεις στο λεξιλόγιο του μοντέλου.
Οι τιμές μπορεί να είναι διαφορετικές για διαφορετικά μοντέλα. Ας βρούμε μερικές παρόμοιες λέξεις με τη λέξη “αγόρι”
Top 10 παρόμοιες λέξεις που το μοντέλο πιστεύει ότι μοιάζουν περισσότερο με τη λέξη «αγόρι»
# find similar word
glove_model.most_similar("boy")
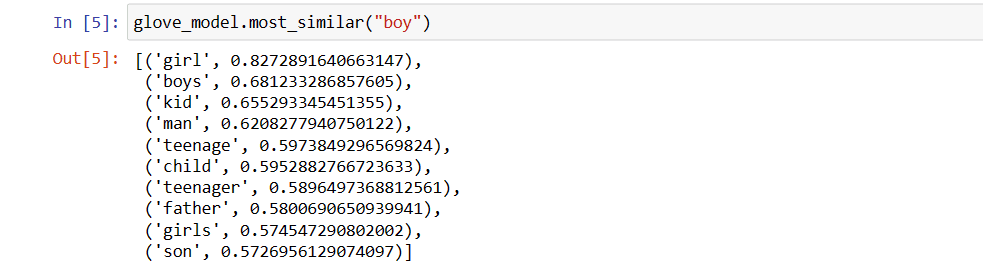 Οι 10 πιο παρόμοιες λέξεις με το «αγόρι»
Οι 10 πιο παρόμοιες λέξεις με το «αγόρι»
Όπως μπορείτε να δείτε, η πιο παρόμοια λέξη με το «αγόρι» είναι «κορίτσι».
Τώρα, θα προσπαθήσουμε να βρούμε πόσο ακριβή θα αποκτήσει το μοντέλο σημασιολογικό νόημα από τις παρεχόμενες λέξεις.
glove_model.most_similar(positive=['boy', 'queen'], negative=['girl'], topn=1)
 Η πιο σχετική λέξη για τη «βασίλισσα»
Η πιο σχετική λέξη για τη «βασίλισσα»
Το μοντέλο μας είναι σε θέση να βρει τέλεια σχέση μεταξύ των λέξεων.
Ορισμός λίστας λεξιλογίων:
Τώρα, ας προσπαθήσουμε να κατανοήσουμε τη σημασιολογική σημασία ή τη σχέση μεταξύ των λέξεων χρησιμοποιώντας μια πλοκή. Καθορίστε τη λίστα των λέξεων που θέλετε να οπτικοποιήσετε.
# Define the list of words you want to visualize vocab = ["boy", "girl", "man", "woman", "king", "queen", "banana", "apple", "mango", "cow", "coconut", "orange", "cat", "dog"]
Δημιουργία μήτρας ενσωμάτωσης:
Ας γράψουμε κώδικα για τη δημιουργία μήτρας ενσωμάτωσης.
# Your code for creating the embedding matrix
EMBEDDING_DIM = glove_model.vectors.shape[1]
word_index = {word: index for index, word in enumerate(vocab)}
num_words = len(vocab)
embedding_matrix = np.zeros((num_words, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = glove_model[word]
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
Ορίστε μια συνάρτηση για οπτικοποίηση t-SNE:
Από αυτόν τον κώδικα, θα ορίσουμε συνάρτηση για την γραφική παράσταση οπτικοποίησης μας.
def tsne_plot(embedding_matrix, words):
tsne_model = TSNE(perplexity=3, n_components=2, init="pca", random_state=42)
coordinates = tsne_model.fit_transform(embedding_matrix)
x, y = coordinates[:, 0], coordinates[:, 1]
plt.figure(figsize=(14, 8))
for i, word in enumerate(words):
plt.scatter(x[i], y[i])
plt.annotate(word,
xy=(x[i], y[i]),
xytext=(2, 2),
textcoords="offset points",
ha="right",
va="bottom")
plt.show()
Ας δούμε πώς φαίνεται η πλοκή μας:
# Call the tsne_plot function with your embedding matrix and list of words tsne_plot(embedding_matrix, vocab)
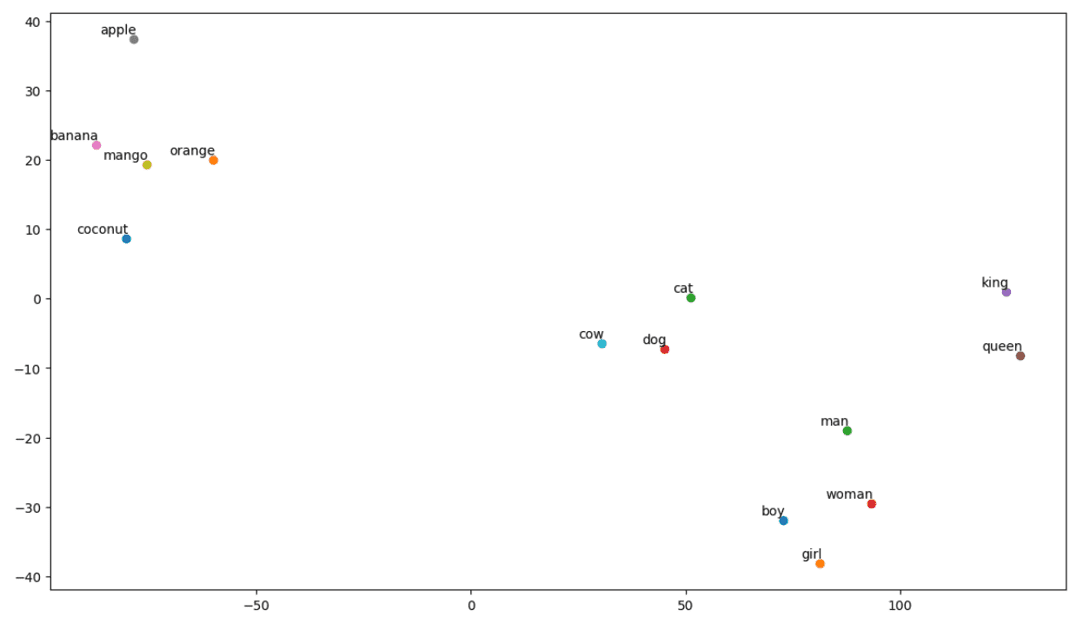 οικόπεδο t-SNE
οικόπεδο t-SNE
Έτσι, όπως μπορούμε να δούμε, υπάρχουν λέξεις όπως «μπανάνα», «μάνγκο», «πορτοκάλι», «καρύδα» και «μήλο» στην αριστερή πλευρά του οικοπέδου μας. Ενώ τα «αγελάδα», «σκύλος» και «γάτα» είναι παρόμοια μεταξύ τους επειδή είναι ζώα.
Έτσι, το μοντέλο μας μπορεί επίσης να βρει σημασιολογικό νόημα και σχέσεις μεταξύ των λέξεων!
Αλλάζοντας απλώς τη λέξη ή δημιουργώντας το μοντέλο σας από την αρχή, μπορείτε να πειραματιστείτε με διαφορετικές λέξεις.
Μπορείτε να χρησιμοποιήσετε αυτήν τη μήτρα ενσωμάτωσης όπως θέλετε. Μπορεί να εφαρμοστεί μόνο σε εργασίες ομοιότητας λέξεων ή να τροφοδοτηθεί στο στρώμα ενσωμάτωσης ενός νευρωνικού δικτύου.
Το GloVe εκπαιδεύεται σε μια μήτρα συν-συμβάντος για να παράγει σημασιολογικό νόημα. Βασίζεται στην ιδέα ότι οι συνυπάρχουσες λέξεις-λέξεις είναι ένα ουσιαστικό κομμάτι γνώσης και ότι η χρήση τους είναι ένας αποτελεσματικός τρόπος χρήσης στατιστικών για την παραγωγή ενσωματώσεων λέξεων. Αυτός είναι ο τρόπος με τον οποίο το GloVe καταφέρνει να προσθέσει «παγκόσμια στατιστικά στοιχεία» στο τελικό προϊόν.
Και αυτό είναι το GloVe. Μια άλλη δημοφιλής μέθοδος διανυσματοποίησης είναι το FastText. Ας το συζητήσουμε περισσότερο.
FastText
Το FastText είναι μια βιβλιοθήκη ανοιχτού κώδικα που εισήχθη από την ερευνητική ομάδα AI του Facebook για ταξινόμηση κειμένων και ανάλυση συναισθημάτων. Το FastText παρέχει εργαλεία για την εκπαίδευση της ενσωμάτωσης λέξεων, τα οποία είναι πυκνά διανυσματικά που αντιπροσωπεύουν λέξεις. Αυτό είναι χρήσιμο για την αποτύπωση της σημασιολογικής σημασίας του εγγράφου. Το FastText υποστηρίζει ταξινόμηση πολλαπλών ετικετών και πολλαπλών κλάσεων.
Γιατί FastText;
Το FastText είναι καλύτερο από άλλα μοντέλα λόγω της ικανότητάς του να γενικεύει σε άγνωστες λέξεις, που έλειπαν σε άλλες μεθόδους. Το FastText παρέχει προ-εκπαιδευμένα διανύσματα λέξεων για διαφορετικές γλώσσες, τα οποία θα μπορούσαν να είναι χρήσιμα σε διάφορες εργασίες όπου χρειαζόμαστε προηγούμενη γνώση σχετικά με τις λέξεις και τη σημασία τους.
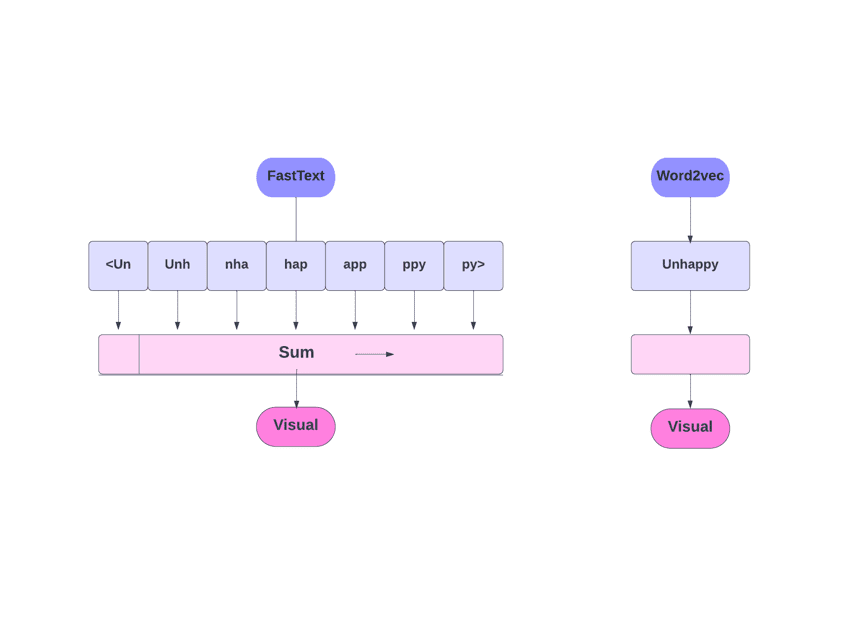 FastText εναντίον Word2Vec
FastText εναντίον Word2Vec
Πώς λειτουργεί;
Όπως συζητήσαμε, άλλα μοντέλα, όπως το Word2Vec και το GloVe, χρησιμοποιούν λέξεις για ενσωμάτωση λέξεων. Όμως, το δομικό στοιχείο του FastText είναι τα γράμματα αντί για λέξεις. Που σημαίνει ότι χρησιμοποιούν γράμματα για την ενσωμάτωση λέξεων.
Η χρήση χαρακτήρων αντί για λέξεις έχει ένα άλλο πλεονέκτημα. Απαιτούνται λιγότερα δεδομένα για την εκπαίδευση. Καθώς μια λέξη γίνεται το περιεχόμενό της, με αποτέλεσμα να μπορούν να εξαχθούν περισσότερες πληροφορίες από το κείμενο.
Η ενσωμάτωση λέξεων που λαμβάνεται μέσω του FastText είναι ένας συνδυασμός ενσωματώσεων χαμηλότερου επιπέδου.
Τώρα, ας δούμε πώς το FastText χρησιμοποιεί πληροφορίες υπολέξεων.
Ας πούμε ότι έχουμε τη λέξη «διάβασμα». Για αυτήν τη λέξη, οι χαρακτήρες n-γραμμάρια μήκους 3-6 θα δημιουργηθούν ως εξής:
- Η αρχή και το τέλος υποδεικνύονται με γωνιακές αγκύλες.
- Ο κατακερματισμός χρησιμοποιείται επειδή μπορεί να υπάρχει μεγάλος αριθμός n-γραμμαρίων. Αντί να μάθουμε μια ενσωμάτωση για κάθε ξεχωριστό n-γραμμάριο, μαθαίνουμε συνολικές ενσωματώσεις B, όπου το B σημαίνει το μέγεθος του κάδου. Το μέγεθος του κάδου των 2 εκατομμυρίων χρησιμοποιήθηκε στο αρχικό χαρτί.
- Κάθε χαρακτήρας n-gram, όπως το “eadi”, αντιστοιχίζεται σε έναν ακέραιο αριθμό μεταξύ 1 και B χρησιμοποιώντας αυτήν τη συνάρτηση κατακερματισμού και αυτός ο δείκτης έχει την αντίστοιχη ενσωμάτωση.
- Με τον μέσο όρο αυτών των συστατικών ενσωματώσεων n-gram, λαμβάνεται στη συνέχεια η πλήρης ενσωμάτωση λέξης.
- Ακόμα κι αν αυτή η προσέγγιση κατακερματισμού έχει ως αποτέλεσμα συγκρούσεις, βοηθάει σε μεγάλο βαθμό στο χειρισμό του μεγέθους του λεξιλογίου.
- Το δίκτυο που χρησιμοποιείται στο FastText είναι παρόμοιο με το Word2Vec. Όπως και εκεί, μπορούμε να εκπαιδεύσουμε το FastText σε δύο λειτουργίες – CBOW και skip-gram. Επομένως, δεν χρειάζεται να επαναλάβουμε αυτό το μέρος ξανά εδώ.
Μπορείτε να εκπαιδεύσετε το δικό σας μοντέλο ή μπορείτε να χρησιμοποιήσετε ένα προεκπαιδευμένο μοντέλο. Θα χρησιμοποιήσουμε ένα προεκπαιδευμένο μοντέλο.
Πρώτα, πρέπει να εγκαταστήσετε το FastText.
pip install fasttext
Θα χρησιμοποιήσουμε ένα σύνολο δεδομένων που αποτελείται από κείμενο συνομιλίας σχετικά με μερικά φάρμακα και πρέπει να ταξινομήσουμε αυτά τα κείμενα σε 3 τύπους. Όπως και με το είδος των ναρκωτικών με τα οποία σχετίζονται.
 Σύνολο δεδομένων
Σύνολο δεδομένων
Τώρα, για να εκπαιδεύσουμε ένα μοντέλο FastText σε οποιοδήποτε σύνολο δεδομένων, πρέπει να προετοιμάσουμε τα δεδομένα εισόδου σε μια συγκεκριμένη μορφή, η οποία είναι:
__label__<τιμή ετικέτας>
Ας το κάνουμε αυτό και για το σύνολο δεδομένων μας.
all_texts = train['text'].tolist()
all_labels = train['drug type'].tolist()
prep_datapoints=[]
for i in range(len(all_texts)):
sample="__label__"+ str(all_labels[i]) + ' '+ all_texts[i]
prep_datapoints.append(sample)
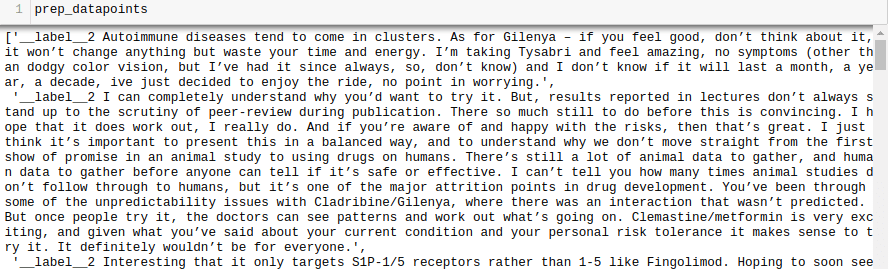 prep_datapoints
prep_datapoints
Παραλείψαμε πολλή προεπεξεργασία σε αυτό το βήμα. Διαφορετικά, το άρθρο μας θα είναι πολύ μεγάλο. Σε προβλήματα του πραγματικού κόσμου, είναι καλύτερο να κάνετε προεπεξεργασία για να καταστήσετε τα δεδομένα κατάλληλα για μοντελοποίηση.
Τώρα, γράψτε τα έτοιμα σημεία δεδομένων σε ένα αρχείο .txt.
with open('train_fasttext.txt','w') as f:
for datapoint in prep_datapoints:
f.write(datapoint)
f.write('n')
f.close()
Ας εκπαιδεύσουμε το μοντέλο μας.
model = fasttext.train_supervised('train_fasttext.txt')
Θα λάβουμε Προβλέψεις από το μοντέλο μας.

Το μοντέλο προβλέπει την ετικέτα και της αποδίδει βαθμολογία εμπιστοσύνης.
Όπως και με οποιοδήποτε άλλο μοντέλο, η απόδοση αυτού του μοντέλου εξαρτάται από μια ποικιλία μεταβλητών, αλλά αν θέλετε να πάρετε μια γρήγορη ιδέα της αναμενόμενης ακρίβειας, το FastText μπορεί να είναι μια εξαιρετική επιλογή.
συμπέρασμα
Συμπερασματικά, οι μέθοδοι διανυσματοποίησης κειμένου όπως το Bag of Words (BoW), το TF-IDF, το Word2Vec, το GloVe και το FastText παρέχουν μια ποικιλία δυνατοτήτων για εργασίες NLP.
Ενώ το Word2Vec καταγράφει τη σημασιολογία των λέξεων και είναι προσαρμόσιμο για μια ποικιλία εργασιών NLP, το BoW και το TF-IDF είναι απλά και κατάλληλα για ταξινόμηση κειμένου και σύσταση.
Για εφαρμογές όπως η ανάλυση συναισθήματος, το GloVe προσφέρει προεκπαιδευμένες ενσωματώσεις και το FastText τα πάει καλά στην ανάλυση σε επίπεδο υπολέξεων, καθιστώντας το χρήσιμο για δομικά πλούσιες γλώσσες και αναγνώριση οντοτήτων.
Η επιλογή της τεχνικής εξαρτάται από την εργασία, τα δεδομένα και τους πόρους. Θα συζητήσουμε τις πολυπλοκότητες του NLP πιο βαθιά καθώς προχωρά αυτή η σειρά. Καλή μάθηση!
Στη συνέχεια, ελέγξτε τα καλύτερα μαθήματα NLP για να μάθετε Επεξεργασία Φυσικής Γλώσσας.