

Το web scraping είναι η ιδέα της εξαγωγής πληροφοριών από έναν ιστότοπο και της χρήσης τους για μια συγκεκριμένη περίπτωση χρήσης.
Ας υποθέσουμε ότι προσπαθείτε να εξαγάγετε έναν πίνακα από μια ιστοσελίδα, να τον μετατρέψετε σε αρχείο JSON και να χρησιμοποιήσετε το αρχείο JSON για τη δημιουργία ορισμένων εσωτερικών εργαλείων. Με τη βοήθεια του web scraping, μπορείτε να εξαγάγετε τα δεδομένα που θέλετε στοχεύοντας τα συγκεκριμένα στοιχεία σε μια ιστοσελίδα. Η απόξεση ιστού με χρήση Python είναι μια πολύ δημοφιλής επιλογή καθώς η Python παρέχει πολλαπλές βιβλιοθήκες όπως το BeautifulSoup ή το Scrapy για την αποτελεσματική εξαγωγή δεδομένων.
Το να έχετε την ικανότητα αποτελεσματικής εξαγωγής δεδομένων είναι επίσης πολύ σημαντικό ως προγραμματιστής ή ως επιστήμονας δεδομένων. Αυτό το άρθρο θα σας βοηθήσει να κατανοήσετε πώς να ξύσετε έναν ιστότοπο αποτελεσματικά και να αποκτήσετε το απαραίτητο περιεχόμενο για να τον χειριστείτε σύμφωνα με τις ανάγκες σας. Για αυτό το σεμινάριο, θα χρησιμοποιήσουμε το πακέτο BeautifulSoup. Είναι ένα μοντέρνο πακέτο για την απόξεση δεδομένων σε Python.
Πίνακας περιεχομένων
Γιατί να χρησιμοποιήσετε την Python για Web Scraping;
Η Python είναι η πρώτη επιλογή για πολλούς προγραμματιστές κατά την κατασκευή web scrapers. Υπάρχουν πολλοί λόγοι για τους οποίους η Python είναι η πρώτη επιλογή, αλλά για αυτό το άρθρο, ας συζητήσουμε τρεις κύριους λόγους για τους οποίους η Python χρησιμοποιείται για την απόξεση δεδομένων.
Βιβλιοθήκη και υποστήριξη κοινότητας: Υπάρχουν πολλές εξαιρετικές βιβλιοθήκες, όπως BeautifulSoup, Scrapy, Selenium, κ.λπ., που παρέχουν εξαιρετικές λειτουργίες για την αποτελεσματική απόξεση ιστοσελίδων. Έχει δημιουργήσει ένα εξαιρετικό οικοσύστημα για την απόξεση ιστού και επίσης επειδή πολλοί προγραμματιστές παγκοσμίως χρησιμοποιούν ήδη Python, μπορείτε να λάβετε γρήγορα βοήθεια όταν είστε κολλημένοι.
Αυτοματισμός: Η Python φημίζεται για τις δυνατότητες αυτοματοποίησής της. Απαιτείται κάτι περισσότερο από το ξύσιμο ιστού εάν προσπαθείτε να φτιάξετε ένα σύνθετο εργαλείο που βασίζεται στην απόξεση. Για παράδειγμα, εάν θέλετε να δημιουργήσετε ένα εργαλείο που παρακολουθεί την τιμή των αντικειμένων σε ένα ηλεκτρονικό κατάστημα, θα πρέπει να προσθέσετε κάποιες δυνατότητες αυτοματισμού, ώστε να μπορεί να παρακολουθεί τις τιμές καθημερινά και να τις προσθέτει στη βάση δεδομένων σας. Η Python σάς δίνει τη δυνατότητα να αυτοματοποιείτε τέτοιες διαδικασίες με ευκολία.
Οπτικοποίηση δεδομένων: Η απόξεση Ιστού χρησιμοποιείται σε μεγάλο βαθμό από τους επιστήμονες δεδομένων. Οι επιστήμονες δεδομένων συχνά χρειάζεται να εξάγουν δεδομένα από ιστοσελίδες. Με βιβλιοθήκες όπως οι Pandas, η Python κάνει την οπτικοποίηση δεδομένων πιο απλή από τα ακατέργαστα δεδομένα.
Βιβλιοθήκες για Web Scraping στην Python
Υπάρχουν αρκετές βιβλιοθήκες διαθέσιμες στην Python για απλούστερη απόξεση ιστού. Ας συζητήσουμε τις τρεις πιο δημοφιλείς βιβλιοθήκες εδώ.
#1. Όμορφη Σούπα
Μία από τις πιο δημοφιλείς βιβλιοθήκες για απόξεση ιστού. Το BeautifulSoup βοηθά τους προγραμματιστές να σκαρώνουν ιστοσελίδες από το 2004. Παρέχει απλές μεθόδους πλοήγησης, αναζήτησης και τροποποίησης του δέντρου ανάλυσης. Το ίδιο το Beautifulsoup κάνει επίσης την κωδικοποίηση για εισερχόμενα και εξερχόμενα δεδομένα. Είναι καλοδιατηρημένο και έχει μεγάλη κοινότητα.
#2. Scrapy
Ένα άλλο δημοφιλές πλαίσιο εξαγωγής δεδομένων. Το Scrapy έχει περισσότερα από 43000 αστέρια στο GitHub. Μπορεί επίσης να χρησιμοποιηθεί για την απόξεση δεδομένων από API. Έχει επίσης μερικές ενδιαφέρουσες ενσωματωμένη υποστήριξη, όπως η αποστολή email.
#3. Σελήνιο
Το Selenium δεν είναι κυρίως μια βιβλιοθήκη απόξεσης ιστού. Αντίθετα, είναι ένα πακέτο αυτοματισμού προγράμματος περιήγησης. Μπορούμε όμως εύκολα να επεκτείνουμε τις λειτουργίες του για το ξύσιμο ιστοσελίδων. Χρησιμοποιεί το πρωτόκολλο WebDriver για τον έλεγχο διαφορετικών προγραμμάτων περιήγησης. Το σελήνιο βρίσκεται στην αγορά σχεδόν 20 χρόνια τώρα. Ωστόσο, χρησιμοποιώντας το Selenium, μπορείτε εύκολα να αυτοματοποιήσετε και να αφαιρέσετε δεδομένα από ιστοσελίδες.
Προκλήσεις με το Python Web Scraping
Κάποιος μπορεί να αντιμετωπίσει πολλές προκλήσεις όταν προσπαθεί να αφαιρέσει δεδομένα από ιστότοπους. Υπάρχουν ζητήματα όπως αργά δίκτυα, εργαλεία κατά της απόξεσης, αποκλεισμός βάσει IP, αποκλεισμός captcha κ.λπ. Αυτά τα ζητήματα μπορεί να προκαλέσουν τεράστια προβλήματα κατά την προσπάθεια απόξεσης ενός ιστότοπου.
Αλλά μπορείτε να παρακάμψετε αποτελεσματικά τις προκλήσεις ακολουθώντας μερικούς τρόπους. Για παράδειγμα, στις περισσότερες περιπτώσεις, μια διεύθυνση IP αποκλείεται από έναν ιστότοπο όταν αποστέλλονται περισσότερα από ένα συγκεκριμένο αριθμό αιτημάτων σε ένα συγκεκριμένο χρονικό διάστημα. Για να αποφύγετε τον αποκλεισμό IP, θα χρειαστεί να κωδικοποιήσετε το scraper σας ώστε να κρυώσει μετά την αποστολή αιτημάτων.

Οι προγραμματιστές τείνουν επίσης να βάζουν παγίδες honeypot για ξύστρες. Αυτές οι παγίδες είναι συνήθως αόρατες στα γυμνά ανθρώπινα μάτια, αλλά μπορούν να συρθούν από μια ξύστρα. Εάν ξύνετε έναν ιστότοπο που τοποθετεί μια τέτοια παγίδα honeypot, θα χρειαστεί να κωδικοποιήσετε το scraper σας ανάλογα.
Το Captcha είναι ένα άλλο σοβαρό πρόβλημα με τις ξύστρες. Οι περισσότεροι ιστότοποι σήμερα χρησιμοποιούν ένα captcha για να προστατεύσουν την πρόσβαση bot στις σελίδες τους. Σε μια τέτοια περίπτωση, ίσως χρειαστεί να χρησιμοποιήσετε μια λύση captcha.
Ξύσιμο ιστότοπου με Python
Όπως συζητήσαμε, θα χρησιμοποιήσουμε το BeautifulSoup για να καταργήσουμε έναν ιστότοπο. Σε αυτό το σεμινάριο, θα ξύσουμε τα ιστορικά δεδομένα του Ethereum από το Coingecko και θα αποθηκεύσουμε τα δεδομένα του πίνακα ως αρχείο JSON. Ας προχωρήσουμε στην κατασκευή του ξύστρα.
Το πρώτο βήμα είναι να εγκαταστήσετε το BeautifulSoup and Requests. Για αυτό το σεμινάριο, θα χρησιμοποιήσω το Pipenv. Το Pipenv είναι ένας διαχειριστής εικονικού περιβάλλοντος για την Python. Μπορείτε επίσης να χρησιμοποιήσετε το Venv αν θέλετε, αλλά προτιμώ το Pipenv. Η συζήτηση για το Pipenv είναι πέρα από το πεδίο αυτού του σεμιναρίου. Αλλά αν θέλετε να μάθετε πώς μπορεί να χρησιμοποιηθεί το Pipenv, ακολουθήστε αυτόν τον οδηγό. Ή, εάν θέλετε να κατανοήσετε τα εικονικά περιβάλλοντα Python, ακολουθήστε αυτόν τον οδηγό.
Εκκινήστε το κέλυφος Pipenv στον κατάλογο του έργου σας εκτελώντας την εντολή pipenv κέλυφος. Θα ξεκινήσει ένα υποκέλυφος στο εικονικό σας περιβάλλον. Τώρα, για να εγκαταστήσετε το BeautifulSoup, εκτελέστε την ακόλουθη εντολή:
pipenv install beautifulsoup4
Και, για την εγκατάσταση αιτημάτων, εκτελέστε την εντολή παρόμοια με την παραπάνω:
pipenv install requests
Μόλις ολοκληρωθεί η εγκατάσταση, εισάγετε τα απαραίτητα πακέτα στο κύριο αρχείο. Δημιουργήστε ένα αρχείο που ονομάζεται main.py και εισαγάγετε τα πακέτα όπως παρακάτω:
from bs4 import BeautifulSoup import requests import json
Το επόμενο βήμα είναι να λάβετε τα περιεχόμενα της σελίδας ιστορικών δεδομένων και να τα αναλύσετε χρησιμοποιώντας τον αναλυτή HTML που είναι διαθέσιμος στο BeautifulSoup.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')
Στον παραπάνω κώδικα, η πρόσβαση στη σελίδα γίνεται χρησιμοποιώντας τη μέθοδο λήψης που είναι διαθέσιμη στη βιβλιοθήκη αιτημάτων. Το αναλυμένο περιεχόμενο στη συνέχεια αποθηκεύεται σε μια μεταβλητή που ονομάζεται σούπα.
Το αρχικό τμήμα απόξεσης ξεκινά τώρα. Αρχικά, θα πρέπει να προσδιορίσετε σωστά τον πίνακα στο DOM. Εάν ανοίξετε αυτήν τη σελίδα και την επιθεωρήσετε χρησιμοποιώντας τα εργαλεία προγραμματιστή που είναι διαθέσιμα στο πρόγραμμα περιήγησης, θα δείτε ότι ο πίνακας έχει αυτούς τους πίνακες τάξεων με ριγέ text-sm text-lg-normal.
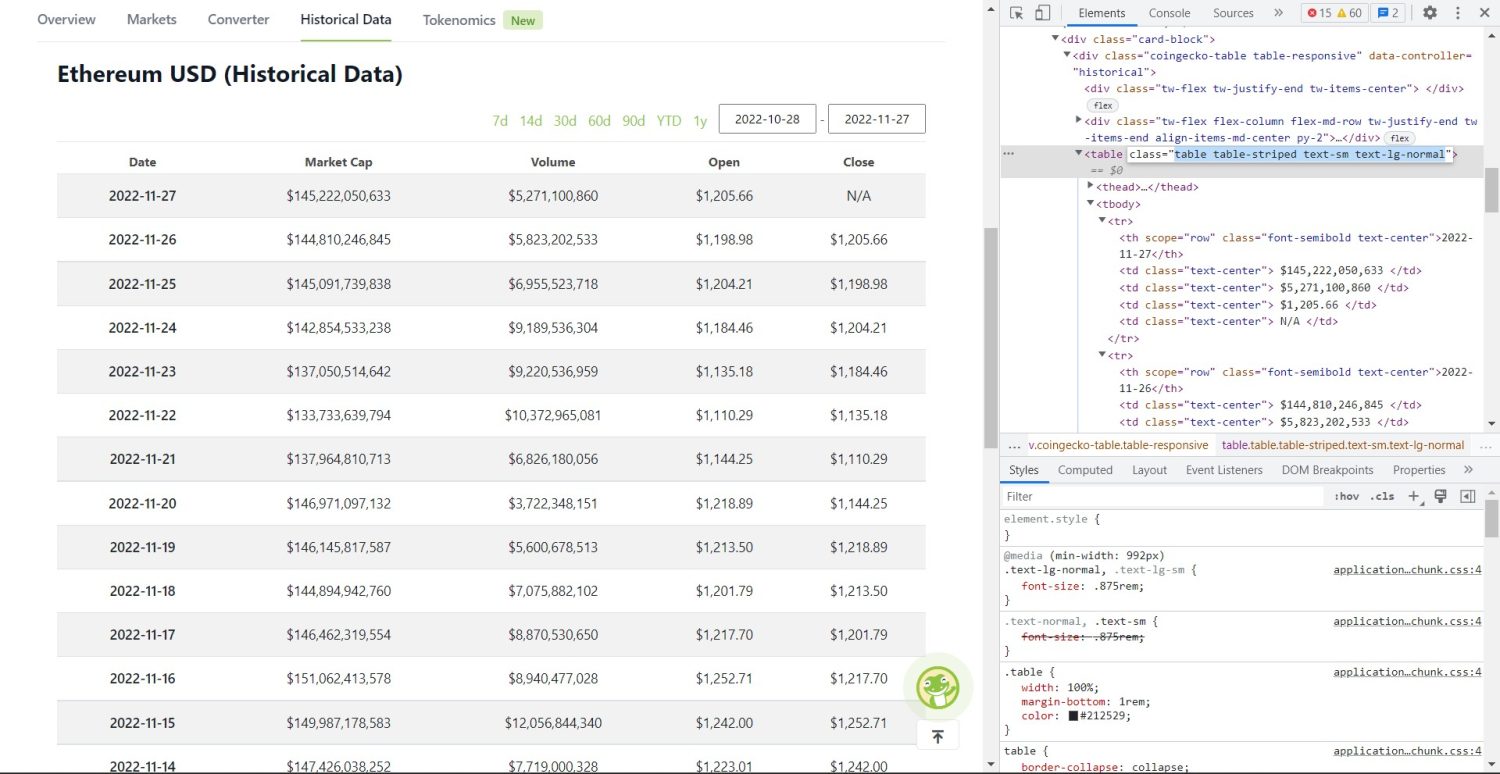 Πίνακας ιστορικών δεδομένων Coingecko Ethereum
Πίνακας ιστορικών δεδομένων Coingecko Ethereum
Για να στοχεύσετε σωστά αυτόν τον πίνακα, μπορείτε να χρησιμοποιήσετε τη μέθοδο εύρεσης.
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)
Στον παραπάνω κώδικα, αρχικά, ο πίνακας βρίσκεται χρησιμοποιώντας τη μέθοδο soup.find και, στη συνέχεια, χρησιμοποιώντας τη μέθοδο find_all, αναζητούνται όλα τα στοιχεία tr μέσα στον πίνακα. Αυτά τα στοιχεία tr αποθηκεύονται σε μια μεταβλητή που ονομάζεται table_data. Ο πίνακας έχει μερικά στοιχεία για τον τίτλο. Μια νέα μεταβλητή που ονομάζεται table_headings προετοιμάζεται για τη διατήρηση των τίτλων σε μια λίστα.
Στη συνέχεια εκτελείται ένας βρόχος for για την πρώτη σειρά του πίνακα. Σε αυτήν τη σειρά, αναζητούνται όλα τα στοιχεία με το th και η τιμή κειμένου τους προστίθεται στη λίστα επικεφαλίδων του πίνακα. Το κείμενο εξάγεται χρησιμοποιώντας τη μέθοδο κειμένου. Εάν εκτυπώσετε τη μεταβλητή table_headings τώρα, θα μπορείτε να δείτε την ακόλουθη έξοδο:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']
Το επόμενο βήμα είναι να ξύσετε τα υπόλοιπα στοιχεία, να δημιουργήσετε ένα λεξικό για κάθε σειρά και, στη συνέχεια, να προσθέσετε τις σειρές σε μια λίστα.
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)):
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i+1]: td[i].text.replace('n', '')})
if data.__len__() > 0:
table_details.append(data)
Αυτό είναι το ουσιαστικό μέρος του κώδικα. Για κάθε tr στη μεταβλητή table_data, πρώτα αναζητούνται τα th στοιχεία. Τα στοιχεία ου είναι η ημερομηνία που φαίνεται στον πίνακα. Αυτά τα στοιχεία αποθηκεύονται σε μια μεταβλητή th. Ομοίως, όλα τα στοιχεία td αποθηκεύονται στη μεταβλητή td.
Αρχικοποιείται ένα κενό λεξικό δεδομένων. Μετά την αρχικοποίηση, κάνουμε βρόχο μέσω του εύρους των στοιχείων td. Για κάθε σειρά, πρώτα, ενημερώνουμε το πρώτο πεδίο του λεξικού με το πρώτο στοιχείο του ου. Ο κωδικός table_headings[0]: ου[0]Το .text εκχωρεί ένα ζεύγος κλειδιού-τιμής ημερομηνίας και το πρώτο στοιχείο.
Μετά την προετοιμασία του πρώτου στοιχείου, τα άλλα στοιχεία εκχωρούνται χρησιμοποιώντας data.update({table_headings[i+1]: td[i].text.replace(‘n’, ”)}). Εδώ, το κείμενο των στοιχείων td εξάγεται αρχικά χρησιμοποιώντας τη μέθοδο κειμένου και, στη συνέχεια, όλα τα n αντικαθίστανται χρησιμοποιώντας τη μέθοδο αντικατάστασης. Στη συνέχεια, η τιμή εκχωρείται στο i+1ο στοιχείο της λίστας επικεφαλίδων_επικεφαλίδων επειδή το στοιχείο i έχει ήδη εκχωρηθεί.
Στη συνέχεια, εάν το μήκος του λεξικού δεδομένων υπερβαίνει το μηδέν, προσθέτουμε το λεξικό στη λίστα table_details. Μπορείτε να εκτυπώσετε τη λίστα table_details για έλεγχο. Αλλά θα γράφουμε τις τιμές σε ένα αρχείο JSON. Ας ρίξουμε μια ματιά στον κώδικα για αυτό,
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('Data saved to json file...')
Εδώ χρησιμοποιούμε τη μέθοδο json.dump για να γράψουμε τις τιμές σε ένα αρχείο JSON που ονομάζεται table.json. Μόλις ολοκληρωθεί η εγγραφή, εκτυπώνουμε δεδομένα που είναι αποθηκευμένα στο αρχείο json… στην κονσόλα.
Τώρα, εκτελέστε το αρχείο χρησιμοποιώντας την ακόλουθη εντολή,
python run main.py
Μετά από κάποιο χρονικό διάστημα, θα μπορείτε να δείτε τα δεδομένα που είναι αποθηκευμένα στο αρχείο JSON… κείμενο στην κονσόλα. Θα δείτε επίσης ένα νέο αρχείο που ονομάζεται table.json στον κατάλογο αρχείων εργασίας. Το αρχείο θα μοιάζει με το ακόλουθο αρχείο JSON:
[
{
"Date": "2022-11-27",
"Market Cap": "$145,222,050,633",
"Volume": "$5,271,100,860",
"Open": "$1,205.66",
"Close": "N/A"
},
{
"Date": "2022-11-26",
"Market Cap": "$144,810,246,845",
"Volume": "$5,823,202,533",
"Open": "$1,198.98",
"Close": "$1,205.66"
},
{
"Date": "2022-11-25",
"Market Cap": "$145,091,739,838",
"Volume": "$6,955,523,718",
"Open": "$1,204.21",
"Close": "$1,198.98"
},
// ...
// ...
]
Έχετε εφαρμόσει με επιτυχία ένα web scraper χρησιμοποιώντας Python. Για να δείτε τον πλήρη κώδικα, μπορείτε να επισκεφτείτε αυτό το αποθετήριο GitHub.
συμπέρασμα
Αυτό το άρθρο εξέτασε πώς θα μπορούσατε να εφαρμόσετε ένα απλό ξύσιμο Python. Συζητήσαμε πώς θα μπορούσε να χρησιμοποιηθεί το BeautifulSoup για γρήγορη απόξεση δεδομένων από τον ιστότοπο. Συζητήσαμε επίσης άλλες διαθέσιμες βιβλιοθήκες και γιατί η Python είναι η πρώτη επιλογή για πολλούς προγραμματιστές για την απόξεση ιστοτόπων.
Μπορείτε επίσης να δείτε αυτά τα πλαίσια απόξεσης ιστού.