
Εάν είστε νέοι στην ανάλυση μεγάλων δεδομένων, ο πλήθος των εργαλείων apache μπορεί να βρίσκεται στο ραντάρ σας. Ωστόσο, το σύνολο των διαφορετικών εργαλείων μπορεί να γίνει μπερδεμένο και, μερικές φορές, συντριπτικό.
Αυτή η ανάρτηση θα επιλύσει αυτή τη σύγχυση και θα εξηγήσει τι είναι το Apache Hive και το Impala και τι τα κάνει να διαφέρουν το ένα από το άλλο!
Πίνακας περιεχομένων
Apache Hive
Το Apache Hive είναι μια διεπαφή πρόσβασης δεδομένων SQL για την πλατφόρμα Apache Hadoop. Το Hive σάς επιτρέπει να ρωτάτε, να συγκεντρώνετε και να αναλύετε δεδομένα χρησιμοποιώντας σύνταξη SQL.
Ένα σχήμα πρόσβασης ανάγνωσης χρησιμοποιείται για δεδομένα στο σύστημα αρχείων HDFS, επιτρέποντάς σας να χειρίζεστε τα δεδομένα σαν έναν συνηθισμένο πίνακα ή σχεσιακό DBMS. Τα ερωτήματα HiveQL μεταφράζονται σε κώδικα Java για εργασίες MapReduce.
Τα ερωτήματα Hive γράφονται στη γλώσσα ερωτημάτων HiveQL, η οποία βασίζεται στη γλώσσα SQL, αλλά δεν υποστηρίζει πλήρως το πρότυπο SQL-92.
Ωστόσο, αυτή η γλώσσα επιτρέπει στους προγραμματιστές να χρησιμοποιούν τα ερωτήματά τους όταν δεν είναι βολικό ή αναποτελεσματικό η χρήση των δυνατοτήτων HiveQL. Το HiveQL μπορεί να επεκταθεί με βαθμωτές συναρτήσεις που ορίζονται από το χρήστη (UDF), συναθροίσεις (κώδικες UDAF) και συναρτήσεις πίνακα (UDTF).
Πώς λειτουργεί το Apache Hive
Το Apache Hive μεταφράζει προγράμματα γραμμένα σε γλώσσα HiveQL (κοντά στη SQL) σε μία ή περισσότερες εργασίες MapReduce, Apache Tez ή Apache Spark. Αυτές είναι τρεις μηχανές εκτέλεσης που μπορούν να εκκινηθούν στο Hadoop. Στη συνέχεια, το Apache Hive οργανώνει τα δεδομένα σε μια συστοιχία για το αρχείο Hadoop Distributed File System (HDFS) για να εκτελέσει τις εργασίες σε ένα σύμπλεγμα για να παράγει μια απόκριση.
Οι πίνακες Apache Hive είναι παρόμοιοι με τις σχεσιακές βάσεις δεδομένων και οι μονάδες δεδομένων οργανώνονται από την πιο σημαντική μονάδα έως την πιο αναλυτική. Οι βάσεις δεδομένων είναι πίνακες που αποτελούνται από διαμερίσματα, τα οποία μπορούν και πάλι να αναλυθούν σε “κουβάδες”.
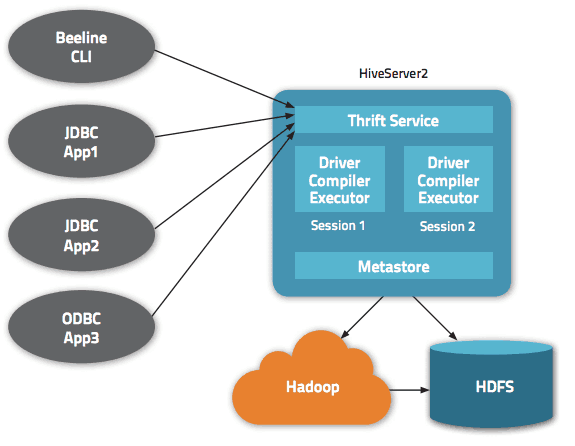
Τα δεδομένα είναι προσβάσιμα μέσω HiveQL. Μέσα σε κάθε βάση δεδομένων, τα δεδομένα είναι αριθμημένα και κάθε πίνακας αντιστοιχεί σε έναν κατάλογο HDFS.
Πολλαπλές διεπαφές είναι διαθέσιμες στην αρχιτεκτονική του Apache Hive, όπως η διεπαφή ιστού, το CLI ή οι εξωτερικοί πελάτες.
Πράγματι, ο διακομιστής “Apache Hive Thrift” επιτρέπει σε απομακρυσμένους πελάτες να υποβάλλουν εντολές και αιτήματα στο Apache Hive χρησιμοποιώντας διάφορες γλώσσες προγραμματισμού. Ο κεντρικός κατάλογος του Apache Hive είναι ένα “μετακατάστημα” που περιέχει όλες τις πληροφορίες.
Ο κινητήρας που κάνει το Hive να λειτουργεί ονομάζεται «οδηγός». Συνδυάζει έναν μεταγλωττιστή και έναν βελτιστοποιητή για να καθορίσει το βέλτιστο σχέδιο εκτέλεσης.
Τέλος, η ασφάλεια παρέχεται από το Hadoop. Επομένως, βασίζεται στο Kerberos για αμοιβαίο έλεγχο ταυτότητας μεταξύ του πελάτη και του διακομιστή. Η άδεια για αρχεία που δημιουργήθηκαν πρόσφατα στο Apache Hive υπαγορεύεται από το HDFS, επιτρέποντας εξουσιοδότηση χρήστη, ομάδας ή με άλλο τρόπο.
Χαρακτηριστικά του Hive
- Υποστηρίζει την υπολογιστική μηχανή τόσο του Hadoop όσο και του Spark
- Χρησιμοποιεί HDFS και λειτουργεί ως αποθήκη δεδομένων.
- Χρησιμοποιεί το MapReduce και υποστηρίζει ETL
- Λόγω του HDFS, έχει ανοχή σφαλμάτων παρόμοια με το Hadoop
Apache Hive: Οφέλη
Το Apache Hive είναι μια ιδανική λύση για ερωτήματα και ανάλυση δεδομένων. Καθιστά δυνατή την απόκτηση ποιοτικών γνώσεων, παρέχοντας ανταγωνιστικό πλεονέκτημα και διευκολύνοντας την ανταπόκριση στη ζήτηση της αγοράς.
Μεταξύ των βασικών πλεονεκτημάτων του Apache Hive, μπορούμε να αναφέρουμε την ευκολία χρήσης που συνδέεται με τη γλώσσα «φιλική προς την SQL». Επιπλέον, επιταχύνει την αρχική εισαγωγή δεδομένων, καθώς τα δεδομένα δεν χρειάζεται να διαβαστούν ή να αριθμηθούν από δίσκο στην εσωτερική μορφή βάσης δεδομένων.
Γνωρίζοντας ότι τα δεδομένα αποθηκεύονται σε HDFS, είναι δυνατή η αποθήκευση μεγάλων συνόλων δεδομένων έως και εκατοντάδων petabytes δεδομένων στο Apache Hive. Αυτή η λύση είναι πολύ πιο επεκτάσιμη από μια παραδοσιακή βάση δεδομένων. Γνωρίζοντας ότι είναι μια υπηρεσία cloud, το Apache Hive επιτρέπει στους χρήστες να ξεκινούν γρήγορα εικονικούς διακομιστές με βάση τις διακυμάνσεις του φόρτου εργασίας (δηλαδή, εργασίες).
Η ασφάλεια είναι επίσης μια πτυχή όπου το Hive αποδίδει καλύτερα, με την ικανότητά του να αναπαράγει κρίσιμους φόρτους εργασίας για την ανάκτηση σε περίπτωση προβλήματος. Τέλος, η ικανότητα εργασίας είναι απαράμιλλη αφού μπορεί να εκτελέσει έως και 100.000 αιτήματα ανά ώρα.
Απάτσι Ιμπάλα
Το Apache Impala είναι μια μαζικά παράλληλη μηχανή ερωτημάτων SQL για τη διαδραστική εκτέλεση ερωτημάτων SQL σε δεδομένα που είναι αποθηκευμένα στο Apache Hadoop, γραμμένα σε C++ και διανέμονται με την άδεια Apache 2.0.
Το Impala ονομάζεται επίσης μηχανή MPP (Massively Parallel Processing), κατανεμημένο DBMS, ακόμη και βάση δεδομένων στοίβας SQL-on-Hadoop.

Το Impala λειτουργεί σε κατανεμημένη λειτουργία, όπου οι περιπτώσεις διεργασίας εκτελούνται σε διαφορετικούς κόμβους συμπλέγματος, λαμβάνουν, προγραμματίζουν και συντονίζουν αιτήματα πελατών. Σε αυτήν την περίπτωση, είναι δυνατή η παράλληλη εκτέλεση τμημάτων του ερωτήματος SQL.
Οι πελάτες είναι χρήστες και εφαρμογές που στέλνουν ερωτήματα SQL σε δεδομένα που είναι αποθηκευμένα στο Apache Hadoop (HBase και HDFS) ή στο Amazon S3. Η αλληλεπίδραση με το Impala πραγματοποιείται μέσω της διεπαφής ιστού HUE (Hadoop User Experience), ODBC, JDBC και του κελύφους της γραμμής εντολών Impala Shell.
Το Impala εξαρτάται από υποδομή από ένα άλλο δημοφιλές εργαλείο SQL-on-Hadoop, το Apache Hive, χρησιμοποιώντας το χώρο αποθήκευσης μεταδεδομένων του. Συγκεκριμένα, το Hive Metastore ενημερώνει την Impala σχετικά με τη διαθεσιμότητα και τη δομή των βάσεων δεδομένων.
Κατά τη δημιουργία, την τροποποίηση και τη διαγραφή αντικειμένων σχήματος ή τη φόρτωση δεδομένων σε πίνακες μέσω δηλώσεων SQL, οι αντίστοιχες αλλαγές μεταδεδομένων διαδίδονται αυτόματα σε όλους τους κόμβους Impala χρησιμοποιώντας μια εξειδικευμένη υπηρεσία καταλόγου.
Τα βασικά στοιχεία του Impala είναι τα ακόλουθα εκτελέσιμα:
- Το Impalad ή το Impala daemon είναι μια υπηρεσία συστήματος που προγραμματίζει και εκτελεί ερωτήματα σε δεδομένα HDFS, HBase και Amazon S3. Μια διεργασία impalad εκτελείται σε κάθε κόμβο συμπλέγματος.
- Το Statestore είναι μια υπηρεσία ονοματοδοσίας που παρακολουθεί την τοποθεσία και την κατάσταση όλων των παρουσιών impalad στο σύμπλεγμα. Μία παρουσία αυτής της υπηρεσίας συστήματος εκτελείται σε κάθε κόμβο και στον κύριο διακομιστή (Name Node).
- Ο Κατάλογος είναι μια υπηρεσία συντονισμού μεταδεδομένων που διαδίδει αλλαγές από δηλώσεις Impala DDL και DML σε όλους τους κόμβους Impala που επηρεάζονται, έτσι ώστε οι νέοι πίνακες ή τα πρόσφατα φορτωμένα δεδομένα να είναι άμεσα ορατά σε οποιονδήποτε κόμβο στο σύμπλεγμα. Συνιστάται να εκτελείται μία παρουσία του Catalog στον ίδιο κεντρικό υπολογιστή συμπλέγματος με τον δαίμονα που αποθηκεύονται σε κατάσταση.
Πώς λειτουργεί το Apache Impala
Η Impala, όπως και το Apache Hive, χρησιμοποιεί μια παρόμοια δηλωτική γλώσσα ερωτημάτων, την Hive Query Language (HiveQL), η οποία είναι υποσύνολο της SQL92, αντί της SQL.
Η πραγματική εκτέλεση του αιτήματος στο Impala έχει ως εξής:
Η εφαρμογή πελάτη στέλνει ένα ερώτημα SQL συνδέοντας σε οποιοδήποτε impalad μέσω τυποποιημένων διεπαφών προγραμμάτων οδήγησης ODBC ή JDBC. Το συνδεδεμένο impalad γίνεται ο συντονιστής του τρέχοντος αιτήματος.
Το ερώτημα SQL αναλύεται για να προσδιοριστούν οι εργασίες για τις παρουσίες impalad στο σύμπλεγμα. Στη συνέχεια, δημιουργείται το βέλτιστο σχέδιο εκτέλεσης ερωτήματος.
Το Impalad έχει απευθείας πρόσβαση στο HDFS και το HBase χρησιμοποιώντας τοπικές παρουσίες υπηρεσιών συστήματος για την παροχή δεδομένων. Σε αντίθεση με το Apache Hive, μια τέτοια άμεση αλληλεπίδραση εξοικονομεί σημαντικά χρόνο εκτέλεσης ερωτημάτων, καθώς τα ενδιάμεσα αποτελέσματα δεν αποθηκεύονται.
Σε απάντηση, κάθε δαίμονας επιστρέφει δεδομένα στο συντονιστικό impalad, στέλνοντας τα αποτελέσματα πίσω στον πελάτη.
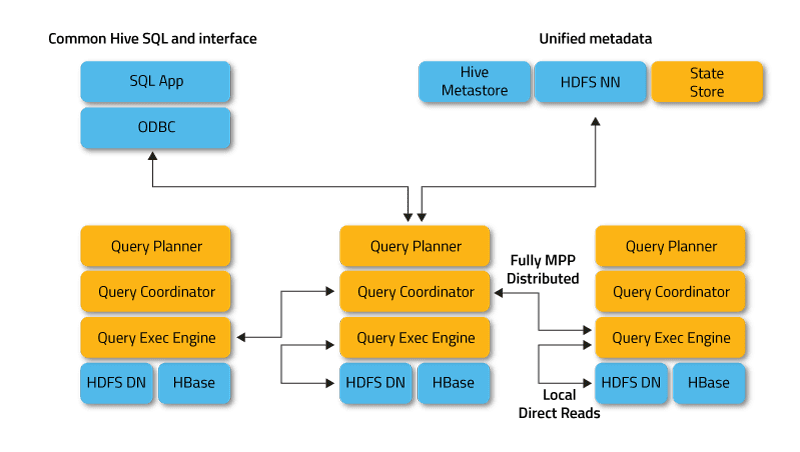
Χαρακτηριστικά του Impala
- Υποστήριξη για επεξεργασία στη μνήμη σε πραγματικό χρόνο
- SQL φιλικό
- Υποστηρίζει συστήματα αποθήκευσης όπως HDFS, Apache HBase και Amazon S3
- Υποστηρίζει την ενοποίηση με εργαλεία BI όπως το Pentaho και το Tableau
- Χρησιμοποιεί σύνταξη HiveQL
Apache Impala: Οφέλη
Το Impala αποφεύγει πιθανές επιβαρύνσεις εκκίνησης επειδή όλες οι διαδικασίες δαίμονα συστήματος ξεκινούν απευθείας κατά την εκκίνηση. Εξοικονομεί σημαντικά χρόνο εκτέλεσης ερωτήματος. Μια επιπλέον αύξηση στην ταχύτητα του Impala οφείλεται στο ότι αυτό το εργαλείο SQL για το Hadoop, σε αντίθεση με το Hive, δεν αποθηκεύει ενδιάμεσα αποτελέσματα και έχει απευθείας πρόσβαση στο HDFS ή στο HBase.
Επιπλέον, η Impala δημιουργεί κώδικα προγράμματος κατά την εκτέλεση και όχι κατά τη μεταγλώττιση, όπως κάνει το Hive. Ωστόσο, μια παρενέργεια της απόδοσης υψηλής ταχύτητας της Impala είναι η μειωμένη αξιοπιστία.
Συγκεκριμένα, εάν ο κόμβος δεδομένων πέσει κατά την εκτέλεση ενός ερωτήματος SQL, η παρουσία Impala θα επανεκκινηθεί και το Hive θα συνεχίσει να διατηρεί μια σύνδεση με την πηγή δεδομένων, παρέχοντας ανοχή σφαλμάτων.
Άλλα πλεονεκτήματα του Impala περιλαμβάνουν ενσωματωμένη υποστήριξη για ένα ασφαλές πρωτόκολλο ελέγχου ταυτότητας δικτύου Kerberos, ιεράρχηση προτεραιοτήτων και δυνατότητα διαχείρισης της ουράς αιτημάτων και υποστήριξη δημοφιλών μορφών Big Data όπως LZO, Avro, RCFile, Parquet και Sequence.
Hive Vs Impala: Ομοιότητες
Το Hive και το Impala διανέμονται ελεύθερα με την άδεια του Apache Software Foundation και αναφέρονται σε εργαλεία SQL για εργασία με δεδομένα που είναι αποθηκευμένα σε ένα σύμπλεγμα Hadoop. Επιπλέον, χρησιμοποιούν επίσης το κατανεμημένο σύστημα αρχείων HDFS.
Η Impala και η Hive υλοποιούν διαφορετικές εργασίες με κοινή εστίαση στην επεξεργασία SQL μεγάλων δεδομένων που είναι αποθηκευμένα σε ένα σύμπλεγμα Apache Hadoop. Το Impala παρέχει μια διεπαφή τύπου SQL, που σας επιτρέπει να διαβάζετε και να γράφετε πίνακες Hive, επιτρέποντας έτσι την εύκολη ανταλλαγή δεδομένων.
Ταυτόχρονα, η Impala κάνει τις λειτουργίες SQL στο Hadoop αρκετά γρήγορες και αποτελεσματικές, επιτρέποντας τη χρήση αυτού του DBMS σε ερευνητικά έργα ανάλυσης Big Data. Όποτε είναι δυνατόν, η Impala συνεργάζεται με μια υπάρχουσα υποδομή Apache Hive που χρησιμοποιείται ήδη για την εκτέλεση μακροχρόνιων ερωτημάτων δέσμης SQL.
Επίσης, η Impala αποθηκεύει τους ορισμούς των πινάκων της σε ένα metastore, μια παραδοσιακή βάση δεδομένων MySQL ή PostgreSQL, δηλαδή στο ίδιο μέρος όπου το Hive αποθηκεύει παρόμοια δεδομένα. Επιτρέπει στην Impala να έχει πρόσβαση στους πίνακες Hive, εφόσον όλες οι στήλες χρησιμοποιούν τους υποστηριζόμενους τύπους δεδομένων, τις μορφές αρχείων και τους κωδικοποιητές συμπίεσης της Impala.
Hive Vs Impala: Differences

Γλώσσα προγραμματισμού
Το Hive είναι γραμμένο σε Java, ενώ το Impala είναι γραμμένο σε C++. Ωστόσο, η Impala χρησιμοποιεί επίσης ορισμένα UDF Hive που βασίζονται σε Java.
Θήκες χρήσης
Οι Μηχανικοί Δεδομένων χρησιμοποιούν το Hive σε διεργασίες ETL (Εξαγωγή, Μετασχηματισμός, Φόρτωση), για παράδειγμα, για μακροχρόνιες ομαδικές εργασίες σε μεγάλα σύνολα δεδομένων, για παράδειγμα, σε ταξιδιωτικούς συγκεντρωτές και συστήματα πληροφοριών αεροδρομίου. Με τη σειρά του, το Impala προορίζεται κυρίως για αναλυτές και επιστήμονες δεδομένων και χρησιμοποιείται κυρίως σε εργασίες όπως η επιχειρηματική ευφυΐα.
Εκτέλεση
Το Impala εκτελεί ερωτήματα SQL σε πραγματικό χρόνο, ενώ το Hive χαρακτηρίζεται από χαμηλή ταχύτητα επεξεργασίας δεδομένων. Με απλά ερωτήματα SQL, το Impala μπορεί να τρέξει 6-69 φορές πιο γρήγορα από το Hive. Ωστόσο, το Hive χειρίζεται καλύτερα πολύπλοκα ερωτήματα.
Καθυστέρηση/απόδοση
Η απόδοση του Hive είναι σημαντικά υψηλότερη από αυτή του Impala. Η δυνατότητα LLAP (Live Long and Process), η οποία επιτρέπει την προσωρινή αποθήκευση ερωτημάτων στη μνήμη, προσφέρει στο Hive καλή απόδοση χαμηλού επιπέδου.
Το LLAP περιλαμβάνει μακροπρόθεσμες υπηρεσίες συστήματος (δαίμονες), οι οποίες σας επιτρέπουν να αλληλεπιδράτε απευθείας με τους κόμβους δεδομένων HDFS και να αντικαθιστάτε την αυστηρά ενσωματωμένη δομή ερωτήματος DAG (Directed acyclic graph) – ένα μοντέλο γραφήματος που χρησιμοποιείται ενεργά στον υπολογισμό Big Data.
Ανοχή σε σφάλματα
Το Hive είναι ένα σύστημα ανοχής σε σφάλματα που διατηρεί όλα τα ενδιάμεσα αποτελέσματα. Επίσης, επηρεάζει θετικά την επεκτασιμότητα, αλλά οδηγεί σε μείωση της ταχύτητας επεξεργασίας δεδομένων. Με τη σειρά του, το Impala δεν μπορεί να ονομαστεί πλατφόρμα ανεκτική σε σφάλματα επειδή είναι περισσότερο δεσμευμένη στη μνήμη.
Μετατροπή κώδικα
Το Hive δημιουργεί εκφράσεις ερωτήματος κατά το χρόνο μεταγλώττισης, ενώ το Impala τις δημιουργεί κατά το χρόνο εκτέλεσης. Το Hive χαρακτηρίζεται από πρόβλημα «ψυχρής εκκίνησης» την πρώτη φορά που εκκινείται η εφαρμογή. Τα ερωτήματα μετατρέπονται αργά λόγω της ανάγκης δημιουργίας σύνδεσης με την πηγή δεδομένων.
Η Impala δεν έχει τέτοιου είδους έξοδα εκκίνησης. Οι απαραίτητες υπηρεσίες συστήματος (δαίμονες) για την επεξεργασία ερωτημάτων SQL ξεκινούν κατά την εκκίνηση, γεγονός που επιταχύνει την εργασία.
Υποστήριξη αποθήκευσης
Το Impala υποστηρίζει μορφές LZO, Avro και Parquet, ενώ το Hive λειτουργεί με Απλό κείμενο και ORC. Ωστόσο, και οι δύο υποστηρίζουν τις μορφές RCFIle και Sequence.
Apache HiveApache ImpalaLanguage JavaC++ Use CasesData EngineeringAnalysis and analyticsPerformanceHigh για απλά ερωτήματα Συγκριτικά χαμηλή καθυστέρησηΜεγαλύτερη καθυστέρηση λόγω προσωρινής αποθήκευσηςΛιγότερο λανθάνον Ανοχή σφαλμάτωνΠερισσότερη ανοχή λόγω MapReduceLess tolerant λόγω MapReduceLess tolerant λόγω της εκκίνησης του MPPOsterquenver,Av.
Τελικές Λέξεις
Η Hive και η Impala δεν ανταγωνίζονται αλλά αλληλοσυμπληρώνονται αποτελεσματικά. Παρόλο που υπάρχουν σημαντικές διαφορές μεταξύ των δύο, υπάρχουν επίσης πολλά κοινά και η επιλογή ενός έναντι του άλλου εξαρτάται από τα δεδομένα και τις ιδιαίτερες απαιτήσεις του έργου.
Μπορείτε επίσης να εξερευνήσετε κατ’ ιδίαν συγκρίσεις μεταξύ Hadoop και Spark.
.