
Τα δεδομένα γίνονται όλο και πιο σημαντικά για τη δημιουργία μοντέλων μηχανικής εκμάθησης, τη δοκιμή εφαρμογών και την κατάρτιση επιχειρηματικών πληροφοριών.
Ωστόσο, για συμμόρφωση με τους πολλούς κανονισμούς για τα δεδομένα, συχνά φυλάσσεται και προστατεύεται αυστηρά. Η πρόσβαση σε αυτά τα δεδομένα μπορεί να πάρει μήνες για να ληφθούν οι απαραίτητες εγγραφές. Εναλλακτικά, οι επιχειρήσεις μπορούν να χρησιμοποιούν συνθετικά δεδομένα.
Πίνακας περιεχομένων
Τι είναι τα συνθετικά δεδομένα;
Φωτογραφία: Twinify
Τα συνθετικά δεδομένα είναι δεδομένα που δημιουργούνται τεχνητά και μοιάζουν στατιστικά με το παλιό σύνολο δεδομένων. Μπορεί να χρησιμοποιηθεί με πραγματικά δεδομένα για την υποστήριξη και τη βελτίωση μοντέλων AI ή μπορεί να χρησιμοποιηθεί ως υποκατάστατο συνολικά.
Επειδή δεν ανήκει σε κανένα υποκείμενο δεδομένων και δεν περιέχει πληροφορίες προσωπικής ταυτοποίησης ή ευαίσθητα δεδομένα, όπως αριθμούς κοινωνικής ασφάλισης, μπορεί να χρησιμοποιηθεί ως εναλλακτική λύση προστασίας της ιδιωτικής ζωής έναντι των πραγματικών δεδομένων παραγωγής.
Διαφορές μεταξύ πραγματικών και συνθετικών δεδομένων
- Η πιο κρίσιμη διαφορά είναι στον τρόπο δημιουργίας των δύο τύπων δεδομένων. Τα πραγματικά δεδομένα προέρχονται από πραγματικά υποκείμενα των οποίων τα δεδομένα συλλέχθηκαν κατά τη διάρκεια ερευνών ή όπως χρησιμοποίησαν την αίτησή σας. Από την άλλη πλευρά, τα συνθετικά δεδομένα δημιουργούνται τεχνητά, αλλά εξακολουθούν να μοιάζουν με το αρχικό σύνολο δεδομένων.
- Η δεύτερη διαφορά έγκειται στους κανονισμούς προστασίας δεδομένων που επηρεάζουν πραγματικά και συνθετικά δεδομένα. Με πραγματικά δεδομένα, τα υποκείμενα θα πρέπει να είναι σε θέση να γνωρίζουν ποια δεδομένα σχετικά με αυτά συλλέγονται και γιατί συλλέγονται, και υπάρχουν όρια στον τρόπο χρήσης τους. Ωστόσο, αυτοί οι κανονισμοί δεν ισχύουν πλέον για συνθετικά δεδομένα, επειδή τα δεδομένα δεν μπορούν να αποδοθούν σε ένα υποκείμενο και δεν περιέχουν προσωπικές πληροφορίες.
- Η τρίτη διαφορά είναι στις ποσότητες των διαθέσιμων δεδομένων. Με πραγματικά δεδομένα, μπορείτε να έχετε μόνο όσα σας δίνουν οι χρήστες. Από την άλλη πλευρά, μπορείτε να δημιουργήσετε όσα συνθετικά δεδομένα θέλετε.
Γιατί πρέπει να εξετάσετε το ενδεχόμενο να χρησιμοποιήσετε συνθετικά δεδομένα
- Είναι σχετικά φθηνότερο να παραχθεί επειδή μπορείτε να δημιουργήσετε πολύ μεγαλύτερα σύνολα δεδομένων που μοιάζουν με το μικρότερο σύνολο δεδομένων που έχετε ήδη. Αυτό σημαίνει ότι τα μοντέλα μηχανικής εκμάθησης θα έχουν περισσότερα δεδομένα για εκπαίδευση.
- Τα δεδομένα που δημιουργούνται επισημαίνονται αυτόματα και καθαρίζονται για εσάς. Αυτό σημαίνει ότι δεν χρειάζεται να ξοδεύετε χρόνο κάνοντας τη χρονοβόρα εργασία προετοιμασίας των δεδομένων για μηχανική εκμάθηση ή ανάλυση.
- Δεν υπάρχουν ζητήματα απορρήτου, καθώς τα δεδομένα δεν ταυτοποιούνται προσωπικά και δεν ανήκουν σε ένα υποκείμενο των δεδομένων. Αυτό σημαίνει ότι μπορείτε να το χρησιμοποιήσετε και να το μοιραστείτε ελεύθερα.
- Μπορείτε να ξεπεράσετε την προκατάληψη της τεχνητής νοημοσύνης διασφαλίζοντας ότι οι μειονοτικές τάξεις εκπροσωπούνται καλά. Αυτό σας βοηθά να δημιουργήσετε δίκαιο και υπεύθυνο AI.
Πώς να δημιουργήσετε συνθετικά δεδομένα
Ενώ η διαδικασία δημιουργίας ποικίλλει ανάλογα με το εργαλείο που χρησιμοποιείτε, γενικά, η διαδικασία ξεκινά με τη σύνδεση μιας γεννήτριας σε ένα υπάρχον σύνολο δεδομένων. Στη συνέχεια, προσδιορίζετε τα πεδία προσωπικής ταυτοποίησης στο σύνολο δεδομένων σας και τα επισημαίνετε για εξαίρεση ή συσκότιση.
Στη συνέχεια, η γεννήτρια αρχίζει να αναγνωρίζει τους τύπους δεδομένων των υπόλοιπων στηλών και τα στατιστικά μοτίβα σε αυτές τις στήλες. Από τότε, μπορείτε να δημιουργήσετε όσα συνθετικά δεδομένα χρειάζεστε.
Συνήθως, μπορείτε να συγκρίνετε τα δεδομένα που δημιουργούνται με το αρχικό σύνολο δεδομένων για να δείτε πόσο καλά τα συνθετικά δεδομένα μοιάζουν με τα πραγματικά δεδομένα.
Τώρα, θα εξερευνήσουμε τα εργαλεία για τη δημιουργία συνθετικών δεδομένων για την εκπαίδευση μοντέλων μηχανικής εκμάθησης.
Κυρίως AI

Κυρίως η τεχνητή νοημοσύνη διαθέτει μια γεννήτρια συνθετικών δεδομένων που τροφοδοτείται από AI που μαθαίνει από τα στατιστικά μοτίβα του αρχικού συνόλου δεδομένων. Στη συνέχεια, το AI δημιουργεί φανταστικούς χαρακτήρες που συμμορφώνονται με τα μαθημένα μοτίβα.
Με το Mostly AI, μπορείτε να δημιουργήσετε ολόκληρες βάσεις δεδομένων με ακεραιότητα αναφοράς. Μπορείτε να συνθέσετε όλα τα είδη δεδομένων για να σας βοηθήσουν να δημιουργήσετε καλύτερα μοντέλα AI.
Synthesized.io

Το Synthesized.io χρησιμοποιείται από κορυφαίες εταιρείες για τις πρωτοβουλίες AI τους. Για να χρησιμοποιήσετε το synthesize.io, καθορίζετε τις απαιτήσεις δεδομένων σε ένα αρχείο διαμόρφωσης YAML.
Στη συνέχεια, δημιουργείτε μια εργασία και την εκτελείτε ως μέρος μιας διοχέτευσης δεδομένων. Διαθέτει επίσης μια πολύ γενναιόδωρη δωρεάν βαθμίδα που σας επιτρέπει να πειραματιστείτε και να δείτε αν ταιριάζει στις ανάγκες δεδομένων σας.
YData

Με το YData, μπορείτε να δημιουργήσετε δεδομένα πινάκων, χρονοσειρών, συναλλαγών, πολλών πινάκων και σχεσιακών δεδομένων. Αυτό σας επιτρέπει να αποφύγετε τα προβλήματα που σχετίζονται με τη συλλογή, την κοινή χρήση και την ποιότητα δεδομένων.
Έρχεται με AI και SDK για χρήση για αλληλεπίδραση με την πλατφόρμα τους. Επιπλέον, διαθέτουν μια γενναιόδωρη δωρεάν βαθμίδα που μπορείτε να χρησιμοποιήσετε για την επίδειξη του προϊόντος.
Gretel AI

Η Gretel AI προσφέρει API για τη δημιουργία απεριόριστων ποσοτήτων συνθετικών δεδομένων. Η Gretel διαθέτει μια γεννήτρια δεδομένων ανοιχτού κώδικα που μπορείτε να εγκαταστήσετε και να χρησιμοποιήσετε.
Εναλλακτικά, μπορείτε να χρησιμοποιήσετε το REST API ή το CLI τους, το οποίο θα έχει κόστος. Η τιμολόγησή τους είναι, ωστόσο, λογική και κλιμακώνεται ανάλογα με το μέγεθος της επιχείρησης.
Κόπουλας
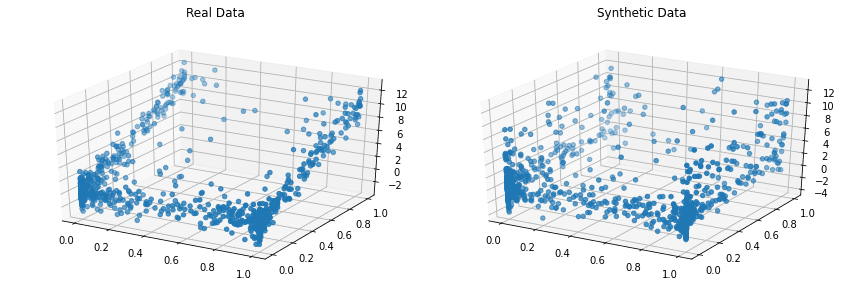
Το Copulas είναι μια βιβλιοθήκη Python ανοιχτού κώδικα για τη μοντελοποίηση πολυμεταβλητών διανομών χρησιμοποιώντας συναρτήσεις copula και τη δημιουργία συνθετικών δεδομένων που ακολουθούν τις ίδιες στατιστικές ιδιότητες.
Το έργο ξεκίνησε το 2018 στο MIT ως μέρος του Synthetic Data Vault Project.
CTGAN
Το CTGAN αποτελείται από γεννήτριες που μπορούν να μάθουν από πραγματικά δεδομένα ενός πίνακα και να παράγουν συνθετικά δεδομένα από τα προσδιορισμένα μοτίβα.
Υλοποιείται ως βιβλιοθήκη Python ανοιχτού κώδικα. Το CTGAN, μαζί με το Copulas, είναι μέρος του Synthetic Data Vault Project.
Σωσίας
Το DoppelGANger είναι μια εφαρμογή ανοιχτού κώδικα των Generative Adversarial Networks για τη δημιουργία συνθετικών δεδομένων.
Το DoppelGANger είναι χρήσιμο για τη δημιουργία δεδομένων χρονοσειρών και χρησιμοποιείται από εταιρείες όπως η Gretel AI. Η βιβλιοθήκη Python είναι διαθέσιμη δωρεάν και είναι ανοιχτού κώδικα.
Synth

Το Synth είναι μια πηγή δεδομένων ανοιχτού κώδικα που σας βοηθά να δημιουργήσετε ρεαλιστικά δεδομένα σύμφωνα με τις προδιαγραφές σας, να αποκρύψετε προσωπικά αναγνωρίσιμες πληροφορίες και να αναπτύξετε δεδομένα δοκιμής για τις εφαρμογές σας.
Μπορείτε να χρησιμοποιήσετε το Synth για να δημιουργήσετε σειρές και σχεσιακά δεδομένα σε πραγματικό χρόνο για τις ανάγκες σας σε μηχανική μάθηση. Το Synth είναι επίσης αγνωστικό στη βάση δεδομένων, ώστε να μπορείτε να το χρησιμοποιήσετε με τις βάσεις δεδομένων SQL και NoSQL.
SDV.dev
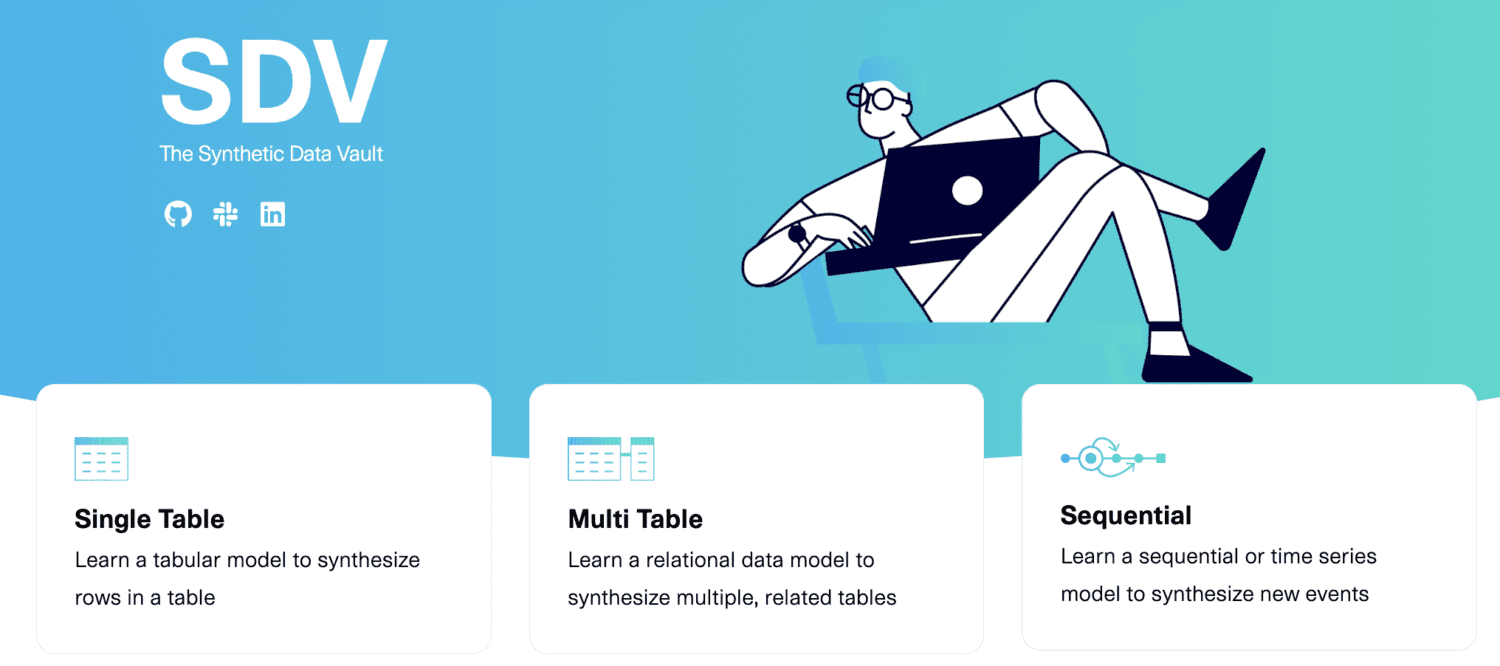
Το SDV σημαίνει συνθετικό θησαυροφυλάκιο δεδομένων. Το SDV.dev είναι ένα έργο λογισμικού που ξεκίνησε στο MIT το 2016 και έχει δημιουργήσει διαφορετικά εργαλεία για τη δημιουργία συνθετικών δεδομένων.
Αυτά τα εργαλεία περιλαμβάνουν τα Copulas, CTGAN, DeepEcho και RDT. Αυτά τα εργαλεία υλοποιούνται ως βιβλιοθήκες Python ανοιχτού κώδικα που μπορείτε να χρησιμοποιήσετε εύκολα.
Τόφου
Το Tofu είναι μια βιβλιοθήκη Python ανοιχτού κώδικα για τη δημιουργία συνθετικών δεδομένων που βασίζονται σε δεδομένα βιοτραπεζών του Ηνωμένου Βασιλείου. Σε αντίθεση με τα εργαλεία που αναφέρθηκαν προηγουμένως που θα σας βοηθήσουν να δημιουργήσετε οποιοδήποτε είδος δεδομένων με βάση το υπάρχον σύνολο δεδομένων σας, το Tofu δημιουργεί δεδομένα που μοιάζουν μόνο με αυτά της βιοτράπεζας.
Η UK Biobank είναι μια μελέτη για τα φαινοτυπικά και γονοτυπικά χαρακτηριστικά 500.000 ενηλίκων μέσης ηλικίας από το Ηνωμένο Βασίλειο.
Twinify
Το Twinify είναι ένα πακέτο λογισμικού που χρησιμοποιείται ως βιβλιοθήκη ή εργαλείο γραμμής εντολών για τη διπλή επιλογή ευαίσθητων δεδομένων παράγοντας συνθετικά δεδομένα με πανομοιότυπες στατιστικές κατανομές.

Για να χρησιμοποιήσετε το Twinify, παρέχετε τα πραγματικά δεδομένα ως αρχείο CSV και μαθαίνει από τα δεδομένα να παράγει ένα μοντέλο που μπορεί να χρησιμοποιηθεί για τη δημιουργία συνθετικών δεδομένων. Είναι εντελώς δωρεάν στη χρήση.
Datanamic
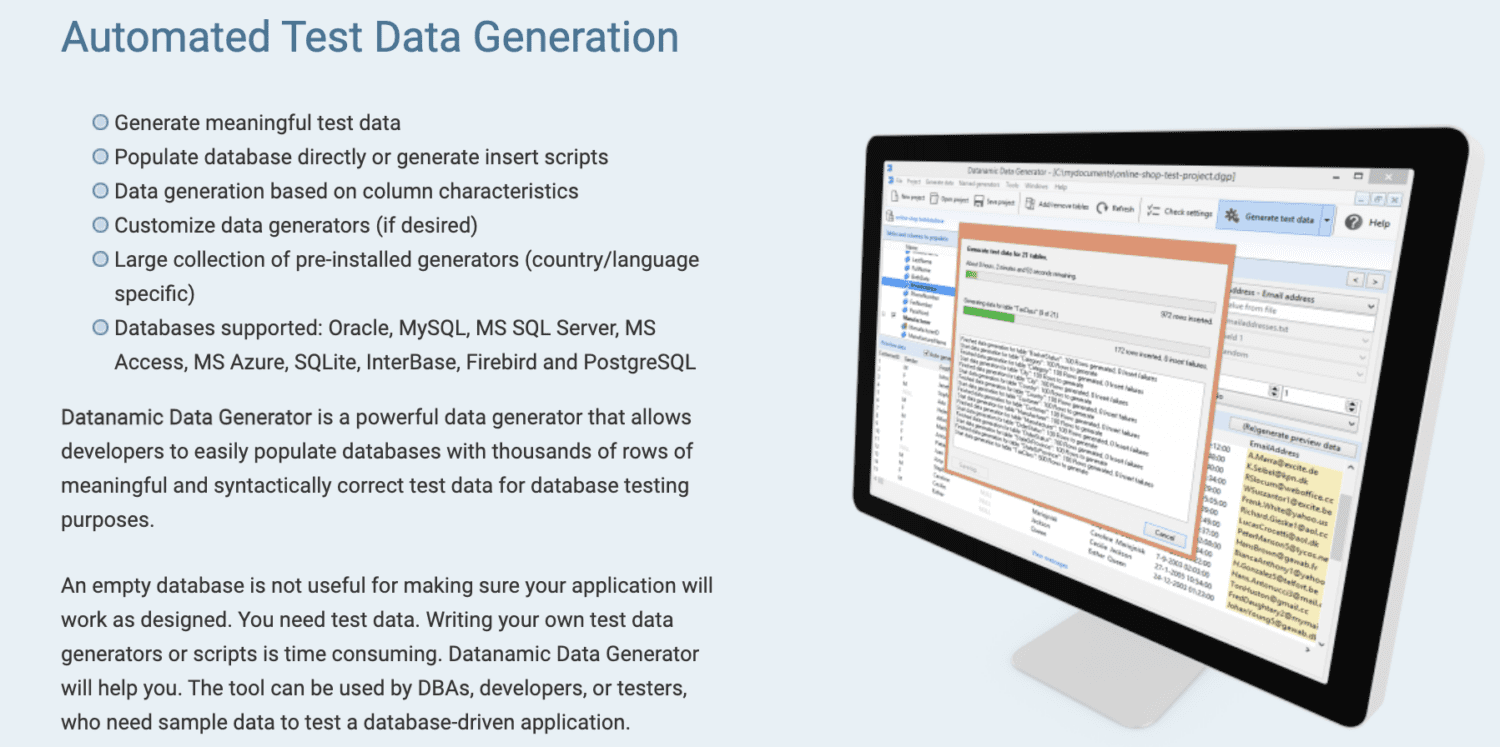
Το Datanamic σάς βοηθά να δημιουργήσετε δεδομένα δοκιμών για εφαρμογές που βασίζονται σε δεδομένα και εφαρμογές μηχανικής μάθησης. Παράγει δεδομένα με βάση τα χαρακτηριστικά της στήλης, όπως email, όνομα και αριθμό τηλεφώνου.
Οι γεννήτριες δεδομένων Datanamic είναι προσαρμόσιμες και υποστηρίζουν τις περισσότερες βάσεις δεδομένων όπως Oracle, MySQL, MySQL Server, MS Access και Postgres. Υποστηρίζει και διασφαλίζει την ακεραιότητα αναφοράς στα δεδομένα που δημιουργούνται.
Benerator
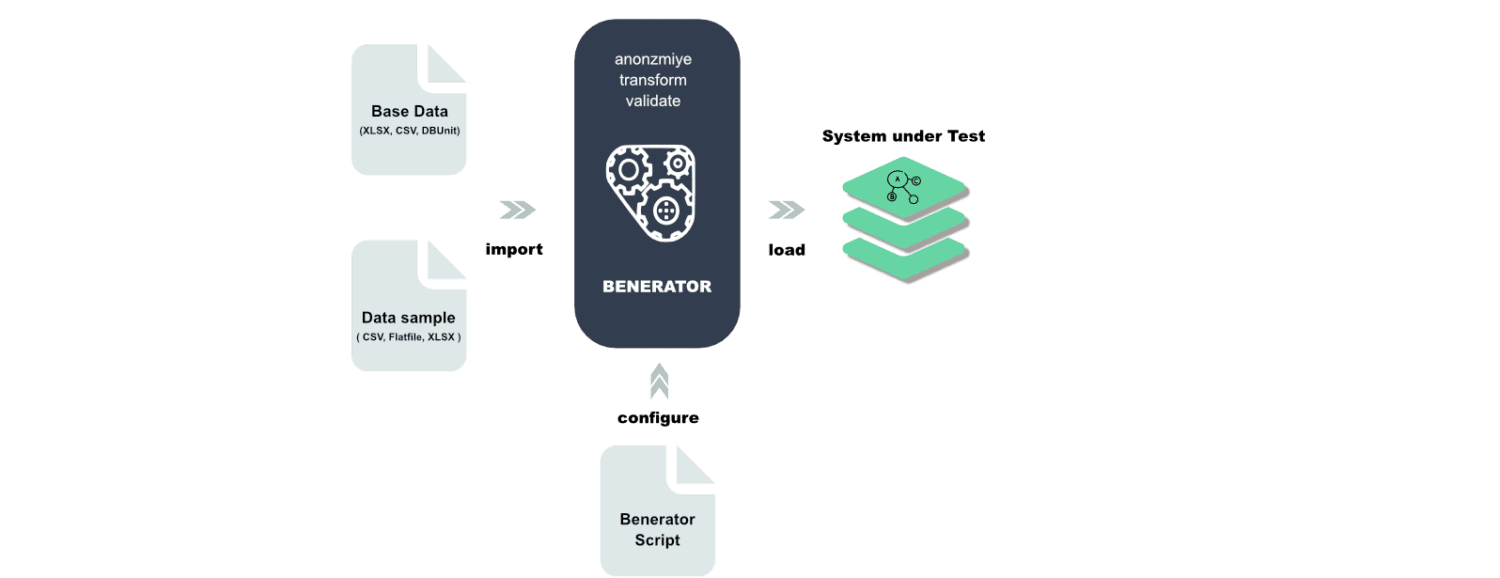
Το Benerator είναι λογισμικό για συσκότιση δεδομένων, δημιουργία και μετεγκατάσταση για σκοπούς δοκιμών και εκπαίδευσης. Χρησιμοποιώντας το Benerator, περιγράφετε δεδομένα χρησιμοποιώντας XML (Extensible Markup Language) και δημιουργείτε χρησιμοποιώντας το εργαλείο γραμμής εντολών.
Είναι κατασκευασμένο για να μπορεί να χρησιμοποιηθεί από μη προγραμματιστές και με αυτό μπορείτε να δημιουργήσετε δισεκατομμύρια σειρές δεδομένων. Το Benerator είναι δωρεάν και ανοιχτού κώδικα.
Τελικές Λέξεις
Υπολογίζεται από την Gartner ότι μέχρι το 2030, θα υπάρχουν περισσότερα συνθετικά δεδομένα που θα χρησιμοποιούνται για τη μηχανική μάθηση από ό,τι θα υπάρχουν πραγματικά δεδομένα.
Δεν είναι δύσκολο να καταλάβουμε γιατί, δεδομένων των ανησυχιών κόστους και απορρήτου της χρήσης πραγματικών δεδομένων. Ως εκ τούτου, είναι απαραίτητο οι επιχειρήσεις να μάθουν για τα συνθετικά δεδομένα και τα διάφορα εργαλεία που θα τις βοηθήσουν στη δημιουργία τους.
Στη συνέχεια, ελέγξτε τα συνθετικά εργαλεία παρακολούθησης για την επιχείρησή σας στο διαδίκτυο.