
Ο πίνακας σύγχυσης είναι ένα εργαλείο για την αξιολόγηση της απόδοσης του τύπου ταξινόμησης των εποπτευόμενων αλγορίθμων μηχανικής εκμάθησης.
Πίνακας περιεχομένων
Τι είναι η μήτρα σύγχυσης;
Εμείς, οι άνθρωποι, αντιλαμβανόμαστε τα πράγματα διαφορετικά – ακόμα και την αλήθεια και το ψέμα. Αυτό που μπορεί να μου φαίνεται γραμμή μήκους 10 εκατοστών μπορεί να σας φαίνεται σαν γραμμή 9 εκατοστών. Αλλά η πραγματική τιμή μπορεί να είναι 9, 10 ή κάτι άλλο. Αυτό που υποθέτουμε είναι η προβλεπόμενη τιμή!
Πώς σκέφτεται ο ανθρώπινος εγκέφαλος
Ακριβώς όπως ο εγκέφαλός μας εφαρμόζει τη δική μας λογική για να προβλέψει κάτι, οι μηχανές εφαρμόζουν διάφορους αλγόριθμους (που ονομάζονται αλγόριθμοι μηχανικής μάθησης) για να καταλήξουν σε μια προβλεπόμενη τιμή για μια ερώτηση. Και πάλι, αυτές οι τιμές μπορεί να είναι ίδιες ή διαφορετικές από την πραγματική τιμή.
Σε έναν ανταγωνιστικό κόσμο, θα θέλαμε να μάθουμε εάν η πρόβλεψή μας είναι σωστή ή όχι για να κατανοήσουμε την απόδοσή μας. Με τον ίδιο τρόπο, μπορούμε να προσδιορίσουμε την απόδοση ενός αλγορίθμου μηχανικής μάθησης με βάση πόσες προβλέψεις έκανε σωστά.
Λοιπόν, τι είναι ένας αλγόριθμος μηχανικής εκμάθησης;
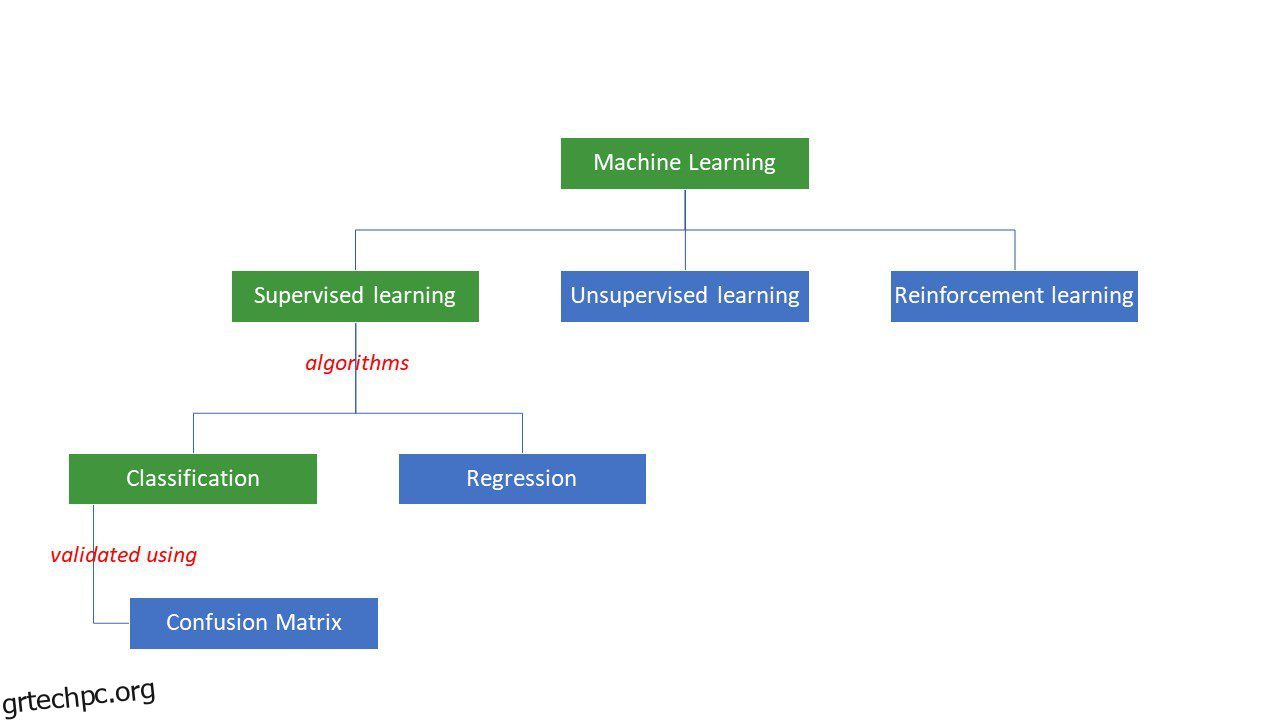
Οι μηχανές προσπαθούν να καταλήξουν σε συγκεκριμένες απαντήσεις σε ένα πρόβλημα εφαρμόζοντας συγκεκριμένη λογική ή σύνολο εντολών, που ονομάζονται αλγόριθμοι μηχανικής μάθησης. Οι αλγόριθμοι μηχανικής μάθησης είναι τριών τύπων – εποπτευόμενοι, χωρίς επίβλεψη ή ενισχυτικοί.
 Τύποι αλγορίθμων μηχανικής μάθησης
Τύποι αλγορίθμων μηχανικής μάθησης
Οι απλούστεροι τύποι αλγορίθμων εποπτεύονται, όπου γνωρίζουμε ήδη την απάντηση, και εκπαιδεύουμε τις μηχανές να φτάνουν σε αυτήν την απάντηση εκπαιδεύοντας τον αλγόριθμο με πολλά δεδομένα – όπως το πώς ένα παιδί θα διαφοροποιούσε μεταξύ ατόμων διαφορετικών ηλικιακών ομάδων με κοιτάζοντας τα χαρακτηριστικά τους ξανά και ξανά.
Οι εποπτευόμενοι αλγόριθμοι ML είναι δύο τύπων – ταξινόμησης και παλινδρόμησης.
Οι αλγόριθμοι ταξινόμησης ταξινομούν ή ταξινομούν δεδομένα με βάση κάποιο σύνολο κριτηρίων. Για παράδειγμα, εάν θέλετε ο αλγόριθμός σας να ομαδοποιεί τους πελάτες με βάση τις προτιμήσεις τους στα τρόφιμα – σε αυτούς που τους αρέσει η πίτσα και σε αυτούς που δεν τους αρέσει η πίτσα, θα χρησιμοποιούσατε έναν αλγόριθμο ταξινόμησης όπως δέντρο αποφάσεων, τυχαίο δάσος, αφελής Bayes ή SVM (Υποστήριξη Vector Machine).
Ποιος από αυτούς τους αλγόριθμους θα έκανε την καλύτερη δουλειά; Γιατί να επιλέξετε έναν αλγόριθμο έναντι του άλλου;
Εισαγάγετε τη μήτρα σύγχυσης….
Ένας πίνακας σύγχυσης είναι ένας πίνακας ή ένας πίνακας που παρέχει πληροφορίες σχετικά με το πόσο ακριβής είναι ένας αλγόριθμος ταξινόμησης στην ταξινόμηση ενός συνόλου δεδομένων. Λοιπόν, το όνομα δεν είναι για να μπερδεύουμε τους ανθρώπους, αλλά πάρα πολλές λανθασμένες προβλέψεις μάλλον σημαίνουν ότι ο αλγόριθμος μπερδεύτηκε!
Έτσι, ένας πίνακας σύγχυσης είναι μια μέθοδος αξιολόγησης της απόδοσης ενός αλγορίθμου ταξινόμησης.
Πως?
Ας υποθέσουμε ότι εφαρμόσατε διαφορετικούς αλγόριθμους στο δυαδικό πρόβλημα που αναφέραμε προηγουμένως: ταξινομήστε (διαχωρίστε) άτομα με βάση το αν τους αρέσει ή όχι η πίτσα. Για να αξιολογήσετε τον αλγόριθμο που έχει τιμές πλησιέστερες στη σωστή απάντηση, θα χρησιμοποιούσατε έναν πίνακα σύγχυσης. Για ένα πρόβλημα δυαδικής ταξινόμησης (μου αρέσει/δεν μου αρέσει, αληθές/λάθος, 1/0), ο πίνακας σύγχυσης δίνει τέσσερις τιμές πλέγματος, και συγκεκριμένα:
- Αληθινό θετικό (TP)
- Αληθινό αρνητικό (TN)
- Ψευδώς θετικά (FP)
- False Negative (FN)
Ποια είναι τα τέσσερα πλέγματα σε έναν πίνακα σύγχυσης;
Οι τέσσερις τιμές που προσδιορίζονται χρησιμοποιώντας τον πίνακα σύγχυσης σχηματίζουν τα πλέγματα του πίνακα.
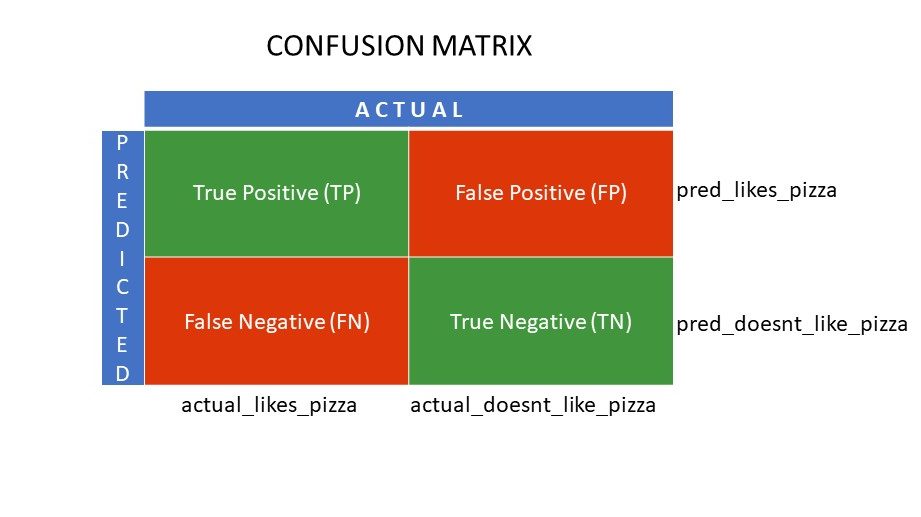 Πλέγματα μήτρας σύγχυσης
Πλέγματα μήτρας σύγχυσης
True Positive (TP) και True Negative (TN) είναι οι τιμές που προβλέπονται σωστά από τον αλγόριθμο ταξινόμησης,
- Το TP αντιπροσωπεύει αυτούς που τους αρέσει η πίτσα και το μοντέλο τους ταξινόμησε σωστά,
- Το TN αντιπροσωπεύει όσους δεν τους αρέσει η πίτσα και το μοντέλο τους ταξινόμησε σωστά,
False Positive (FP) και False Negative (FN) είναι οι τιμές που προβλέπονται λανθασμένα από τον ταξινομητή,
- Το FP αντιπροσωπεύει όσους δεν τους αρέσει η πίτσα (αρνητικό), αλλά ο ταξινομητής προέβλεψε ότι τους αρέσει η πίτσα (λανθασμένα θετική). Το FP ονομάζεται επίσης σφάλμα τύπου I.
- Το FN αντιπροσωπεύει αυτούς που τους αρέσει η πίτσα (θετική), αλλά ο ταξινομητής προέβλεψε ότι δεν τους αρέσει (λανθασμένα αρνητικό). Το FN ονομάζεται επίσης σφάλμα τύπου II.
Για να κατανοήσουμε περαιτέρω την έννοια, ας πάρουμε ένα πραγματικό σενάριο.
Ας υποθέσουμε ότι έχετε ένα σύνολο δεδομένων 400 ατόμων που υποβλήθηκαν στο τεστ Covid. Τώρα, έχετε τα αποτελέσματα διαφόρων αλγορίθμων που καθόρισαν τον αριθμό των θετικών και αρνητικών ατόμων Covid.
Ακολουθούν οι δύο πίνακες σύγχυσης για σύγκριση:
Εξετάζοντας και τα δύο, μπορεί να μπείτε στον πειρασμό να πείτε ότι ο 1ος αλγόριθμος είναι πιο ακριβής. Όμως, για να έχουμε ένα συγκεκριμένο αποτέλεσμα, χρειαζόμαστε κάποιες μετρήσεις που μπορούν να μετρήσουν την ακρίβεια, την ακρίβεια και πολλές άλλες τιμές που αποδεικνύουν ποιος αλγόριθμος είναι καλύτερος.
Μετρήσεις με χρήση πίνακα σύγχυσης και η σημασία τους
Οι κύριες μετρήσεις που μας βοηθούν να αποφασίσουμε εάν ο ταξινομητής έκανε τις σωστές προβλέψεις είναι:
#1. Ανάκληση/Ευαισθησία
Η ανάκληση ή η ευαισθησία ή ο πραγματικός θετικός ρυθμός (TPR) ή η πιθανότητα ανίχνευσης είναι η αναλογία των σωστών θετικών προβλέψεων (TP) προς τα συνολικά θετικά (δηλαδή, TP και FN).
R = TP/(TP + FN)
Η ανάκληση είναι το μέτρο των σωστών θετικών αποτελεσμάτων που επιστρέφονται από τον αριθμό των σωστών θετικών αποτελεσμάτων που θα μπορούσαν να είχαν παραχθεί. Μια υψηλότερη τιμή της Ανάκλησης σημαίνει ότι υπάρχουν λιγότερα ψευδώς αρνητικά, κάτι που είναι καλό για τον αλγόριθμο. Χρησιμοποιήστε την Ανάκληση όταν είναι σημαντικό να γνωρίζετε τα ψευδώς αρνητικά. Για παράδειγμα, εάν ένα άτομο έχει πολλαπλά μπλοκαρίσματα στην καρδιά και το μοντέλο δείχνει ότι είναι απολύτως καλά, θα μπορούσε να αποβεί μοιραίο.
#2. Ακρίβεια
Η ακρίβεια είναι το μέτρο των σωστών θετικών αποτελεσμάτων από όλα τα θετικά αποτελέσματα που έχουν προβλεφθεί, συμπεριλαμβανομένων τόσο των αληθών όσο και των ψευδών θετικών.
Pr = TP/(TP + FP)
Η ακρίβεια είναι πολύ σημαντική όταν τα ψευδώς θετικά είναι πολύ σημαντικά για να αγνοηθούν. Για παράδειγμα, εάν ένα άτομο δεν έχει διαβήτη, αλλά το δείχνει το μοντέλο και ο γιατρός συνταγογραφεί ορισμένα φάρμακα. Αυτό μπορεί να οδηγήσει σε σοβαρές παρενέργειες.
#3. Ιδιαιτερότητα
Το Specificity ή το True Negative Rate (TNR) είναι τα σωστά αρνητικά αποτελέσματα που βρέθηκαν από όλα τα αποτελέσματα που θα μπορούσαν να ήταν αρνητικά.
S = TN/(TN + FP)
Είναι ένα μέτρο του πόσο καλά ο ταξινομητής σας προσδιορίζει τις αρνητικές τιμές.
#4. Ακρίβεια
Ακρίβεια είναι ο αριθμός των σωστών προβλέψεων από τον συνολικό αριθμό των προβλέψεων. Έτσι, εάν βρήκατε σωστά 20 θετικές και 10 αρνητικές τιμές από ένα δείγμα 50, η ακρίβεια του μοντέλου σας θα είναι 30/50.
Ακρίβεια A = (TP + TN)/(TP + TN + FP + FN)
#5. Επικράτηση
Ο επιπολασμός είναι το μέτρο του αριθμού των θετικών αποτελεσμάτων που λαμβάνονται από όλα τα αποτελέσματα.
P = (TP + FN)/(TP + TN + FP + FN)
#6. Σκορ F
Μερικές φορές, είναι δύσκολο να συγκρίνουμε δύο ταξινομητές (μοντέλα) χρησιμοποιώντας μόνο την Ακρίβεια και την Ανάκληση, τα οποία είναι απλώς αριθμητικά μέσα ενός συνδυασμού των τεσσάρων πλεγμάτων. Σε τέτοιες περιπτώσεις, μπορούμε να χρησιμοποιήσουμε το F Score ή το F1 Score, το οποίο είναι ο αρμονικός μέσος όρος – που είναι πιο ακριβής επειδή δεν διαφέρει πολύ για εξαιρετικά υψηλές τιμές. Η υψηλότερη βαθμολογία F (max 1) υποδηλώνει καλύτερο μοντέλο.
Βαθμολογία F = 2*Ακρίβεια*Ανάκληση/ (Ανάκληση + Ακρίβεια)
Όταν είναι ζωτικής σημασίας να φροντίζετε τόσο τα ψευδώς θετικά όσο και τα ψευδώς αρνητικά, η βαθμολογία F1 είναι μια καλή μέτρηση. Για παράδειγμα, όσοι δεν είναι θετικοί στον Covid (αλλά το έδειξε ο αλγόριθμος) δεν χρειάζεται να απομονώνονται άσκοπα. Με τον ίδιο τρόπο, όσοι είναι θετικοί στον Covid (αλλά ο αλγόριθμος είπε ότι δεν είναι) πρέπει να απομονωθούν.
#7. Καμπύλες ROC
Παράμετροι όπως η ακρίβεια και η ακρίβεια είναι καλές μετρήσεις εάν τα δεδομένα είναι ισορροπημένα. Για ένα μη ισορροπημένο σύνολο δεδομένων, μια υψηλή ακρίβεια μπορεί να μην σημαίνει απαραίτητα ότι ο ταξινομητής είναι αποτελεσματικός. Για παράδειγμα, 90 στους 100 μαθητές σε μια παρτίδα γνωρίζουν ισπανικά. Τώρα, ακόμα κι αν ο αλγόριθμός σας λέει ότι και οι 100 γνωρίζουν ισπανικά, η ακρίβειά του θα είναι 90%, κάτι που μπορεί να δώσει λάθος εικόνα για το μοντέλο. Σε περιπτώσεις μη ισορροπημένων συνόλων δεδομένων, μετρήσεις όπως το ROC είναι πιο αποτελεσματικοί προσδιοριστές.
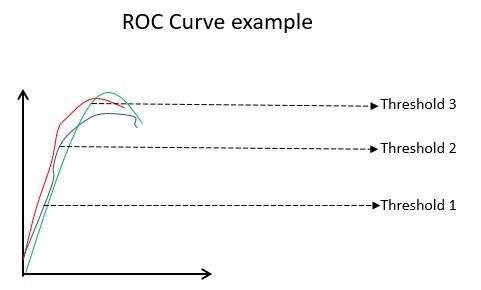 Παράδειγμα καμπύλης ROC
Παράδειγμα καμπύλης ROC
Η καμπύλη ROC (Receiver Operating Characteristic) εμφανίζει οπτικά την απόδοση ενός μοντέλου δυαδικής ταξινόμησης σε διάφορα κατώφλια ταξινόμησης. Είναι μια γραφική παράσταση TPR (True Positive Rate) έναντι FPR (False Positive Rate), η οποία υπολογίζεται ως (1-Specificity) σε διαφορετικές τιμές κατωφλίου. Η τιμή που είναι πλησιέστερη στις 45 μοίρες (πάνω αριστερά) στο διάγραμμα είναι η πιο ακριβής τιμή κατωφλίου. Εάν το όριο είναι πολύ υψηλό, δεν θα έχουμε πολλά ψευδώς θετικά, αλλά θα έχουμε περισσότερα ψευδώς αρνητικά και το αντίστροφο.
Γενικά, όταν σχεδιάζεται η καμπύλη ROC για διάφορα μοντέλα, αυτό που έχει τη μεγαλύτερη περιοχή κάτω από την καμπύλη (AUC) θεωρείται το καλύτερο μοντέλο.
Ας υπολογίσουμε όλες τις μετρικές τιμές για τους πίνακες σύγχυσης του Classifier I και του Classifier II:
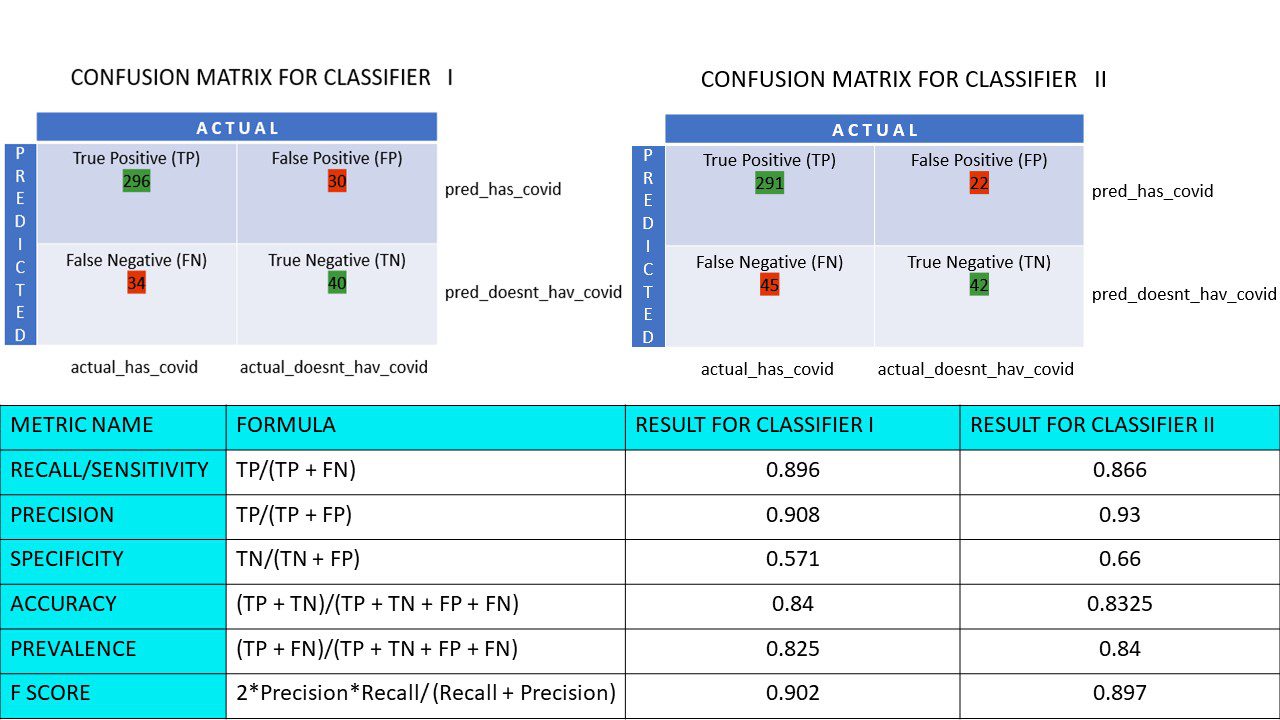 Μετρική σύγκριση για τους ταξινομητές 1 και 2 της έρευνας πίτσας
Μετρική σύγκριση για τους ταξινομητές 1 και 2 της έρευνας πίτσας
Βλέπουμε ότι η ακρίβεια είναι μεγαλύτερη στον ταξινομητή II, ενώ η ακρίβεια είναι ελαφρώς υψηλότερη στον ταξινομητή Ι. Με βάση το πρόβλημα που παρουσιάζεται, οι υπεύθυνοι λήψης αποφάσεων μπορούν να επιλέξουν τους ταξινομητές I ή II.
N x N πίνακας σύγχυσης
Μέχρι στιγμής, έχουμε δει έναν πίνακα σύγχυσης για δυαδικούς ταξινομητές. Τι θα γινόταν αν υπήρχαν περισσότερες κατηγορίες από απλώς ναι/όχι ή μου αρέσει/δεν μου αρέσει. Για παράδειγμα, εάν ο αλγόριθμός σας επρόκειτο να ταξινομήσει εικόνες με κόκκινα, πράσινα και μπλε χρώματα. Αυτός ο τύπος ταξινόμησης ονομάζεται ταξινόμηση πολλαπλών κλάσεων. Ο αριθμός των μεταβλητών εξόδου καθορίζει επίσης το μέγεθος του πίνακα. Άρα, σε αυτήν την περίπτωση, ο πίνακας σύγχυσης θα είναι 3×3.
 Πίνακας σύγχυσης για έναν ταξινομητή πολλαπλών κλάσεων
Πίνακας σύγχυσης για έναν ταξινομητή πολλαπλών κλάσεων
Περίληψη
Ένας πίνακας σύγχυσης είναι ένα εξαιρετικό σύστημα αξιολόγησης, καθώς παρέχει λεπτομερείς πληροφορίες σχετικά με την απόδοση ενός αλγορίθμου ταξινόμησης. Λειτουργεί καλά για δυαδικούς καθώς και για ταξινομητές πολλαπλών κλάσεων, όπου υπάρχουν περισσότερες από 2 παράμετροι που πρέπει να ληφθούν υπόψη. Είναι εύκολο να απεικονίσουμε έναν πίνακα σύγχυσης και μπορούμε να δημιουργήσουμε όλες τις άλλες μετρήσεις απόδοσης, όπως το F Score, την ακρίβεια, το ROC και την ακρίβεια χρησιμοποιώντας τον πίνακα σύγχυσης.
Μπορείτε επίσης να δείτε πώς να επιλέξετε αλγόριθμους ML για προβλήματα παλινδρόμησης.