

Η επεξεργασία μεγάλων δεδομένων είναι μια από τις πιο σύνθετες διαδικασίες που αντιμετωπίζουν οι οργανισμοί. Η διαδικασία γίνεται πιο περίπλοκη όταν έχετε μεγάλο όγκο δεδομένων σε πραγματικό χρόνο.
Σε αυτήν την ανάρτηση, θα ανακαλύψουμε τι είναι η επεξεργασία μεγάλων δεδομένων, πώς γίνεται και θα εξερευνήσουμε το Apache Kafka και το Spark – τα δύο από τα πιο διάσημα εργαλεία επεξεργασίας δεδομένων!
Πίνακας περιεχομένων
Τι είναι η Επεξεργασία Δεδομένων; Πώς γίνεται;
Η επεξεργασία δεδομένων ορίζεται ως οποιαδήποτε λειτουργία ή σύνολο λειτουργιών, είτε πραγματοποιείται είτε όχι με χρήση αυτοματοποιημένης διαδικασίας. Μπορεί να θεωρηθεί ως η συλλογή, η παραγγελία και η οργάνωση πληροφοριών σύμφωνα με μια λογική και κατάλληλη διάθεση για ερμηνεία.
Όταν ένας χρήστης αποκτά πρόσβαση σε μια βάση δεδομένων και λαμβάνει αποτελέσματα για την αναζήτησή του, είναι η επεξεργασία δεδομένων που του δίνει τα αποτελέσματα που χρειάζονται. Οι πληροφορίες που εξάγονται ως αποτέλεσμα αναζήτησης είναι το αποτέλεσμα επεξεργασίας δεδομένων. Αυτός είναι ο λόγος για τον οποίο η τεχνολογία της πληροφορίας έχει το επίκεντρο της ύπαρξής της με επίκεντρο την επεξεργασία δεδομένων.
Η παραδοσιακή επεξεργασία δεδομένων πραγματοποιήθηκε με χρήση απλού λογισμικού. Ωστόσο, με την εμφάνιση των Big Data, τα πράγματα έχουν αλλάξει. Τα Big Data αναφέρονται σε πληροφορίες των οποίων ο όγκος μπορεί να ξεπεράσει τα εκατό terabyte και petabyte.
Επιπλέον, αυτές οι πληροφορίες ενημερώνονται τακτικά. Παραδείγματα περιλαμβάνουν δεδομένα που προέρχονται από κέντρα επικοινωνίας, μέσα κοινωνικής δικτύωσης, δεδομένα συναλλαγών χρηματιστηρίου κ.λπ. Αυτά τα δεδομένα μερικές φορές ονομάζονται επίσης ροή δεδομένων – μια σταθερή, ανεξέλεγκτη ροή δεδομένων. Το κύριο χαρακτηριστικό του είναι ότι τα δεδομένα δεν έχουν καθορισμένα όρια, επομένως είναι αδύνατο να πούμε πότε ξεκινά ή πότε τελειώνει η ροή.
Τα δεδομένα υποβάλλονται σε επεξεργασία καθώς φτάνουν στον προορισμό. Μερικοί συγγραφείς το ονομάζουν επεξεργασία σε πραγματικό χρόνο ή σε απευθείας σύνδεση. Μια διαφορετική προσέγγιση είναι η επεξεργασία μπλοκ, παρτίδας ή εκτός σύνδεσης, κατά την οποία μπλοκ δεδομένων υποβάλλονται σε επεξεργασία σε χρονικά παράθυρα ωρών ή ημερών. Συχνά η παρτίδα είναι μια διαδικασία που εκτελείται τη νύχτα, ενοποιώντας τα δεδομένα εκείνης της ημέρας. Υπάρχουν περιπτώσεις χρονικών παραθύρων μιας εβδομάδας ή ακόμα και ενός μήνα που δημιουργούν απαρχαιωμένες αναφορές.
Δεδομένου ότι οι καλύτερες πλατφόρμες επεξεργασίας Big Data μέσω streaming είναι ανοιχτές πηγές όπως το Kafka και το Spark, αυτές οι πλατφόρμες επιτρέπουν τη χρήση άλλων διαφορετικών και συμπληρωματικών. Αυτό σημαίνει ότι όντας ανοιχτού κώδικα, εξελίσσονται πιο γρήγορα και χρησιμοποιούν περισσότερα εργαλεία. Με αυτόν τον τρόπο, λαμβάνονται ροές δεδομένων από άλλα μέρη με μεταβλητό ρυθμό και χωρίς διακοπές.
Τώρα, θα δούμε δύο από τα πιο ευρέως γνωστά εργαλεία επεξεργασίας δεδομένων και θα τα συγκρίνουμε:
Απάτσι Κάφκα
Το Apache Kafka είναι ένα σύστημα ανταλλαγής μηνυμάτων που δημιουργεί εφαρμογές ροής με συνεχή ροή δεδομένων. Αρχικά δημιουργήθηκε από το LinkedIn, ο Kafka βασίζεται σε log. ένα αρχείο καταγραφής είναι μια βασική μορφή αποθήκευσης επειδή κάθε νέα πληροφορία προστίθεται στο τέλος του αρχείου.

Το Kafka είναι μια από τις καλύτερες λύσεις για μεγάλα δεδομένα επειδή το κύριο χαρακτηριστικό του είναι η υψηλή απόδοση. Με το Apache Kafka, είναι ακόμη δυνατός ο μετασχηματισμός της επεξεργασίας κατά παρτίδες σε πραγματικό χρόνο,
Το Apache Kafka είναι ένα σύστημα ανταλλαγής μηνυμάτων δημοσίευσης-εγγραφής στο οποίο μια εφαρμογή δημοσιεύει και μια εφαρμογή που εγγράφεται λαμβάνει μηνύματα. Ο χρόνος μεταξύ της δημοσίευσης και της λήψης του μηνύματος μπορεί να είναι χιλιοστά του δευτερολέπτου, επομένως μια λύση Kafka έχει χαμηλή καθυστέρηση.
Δουλειά του Κάφκα
Η αρχιτεκτονική του Απάτσι Κάφκα περιλαμβάνει παραγωγούς, καταναλωτές και το ίδιο το σύμπλεγμα. Ο παραγωγός είναι οποιαδήποτε εφαρμογή που δημοσιεύει μηνύματα στο σύμπλεγμα. Καταναλωτής είναι κάθε εφαρμογή που λαμβάνει μηνύματα από τον Κάφκα. Το σύμπλεγμα Kafka είναι ένα σύνολο κόμβων που λειτουργούν ως ένα μόνο παράδειγμα της υπηρεσίας ανταλλαγής μηνυμάτων.
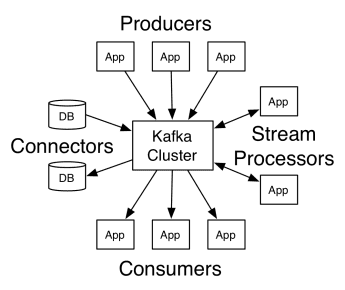 Δουλειά του Κάφκα
Δουλειά του Κάφκα
Ένα σύμπλεγμα Κάφκα αποτελείται από πολλούς μεσίτες. Ένας μεσίτης είναι ένας διακομιστής Kafka που λαμβάνει μηνύματα από παραγωγούς και τα γράφει στο δίσκο. Κάθε μεσίτης διαχειρίζεται μια λίστα θεμάτων και κάθε θέμα χωρίζεται σε πολλά διαμερίσματα.
Αφού λάβει τα μηνύματα, ο μεσίτης τα στέλνει στους εγγεγραμμένους καταναλωτές για κάθε θέμα.
Οι ρυθμίσεις του Apache Kafka διαχειρίζονται από το Apache Zookeeper, το οποίο αποθηκεύει μεταδεδομένα συμπλέγματος, όπως τοποθεσία διαμερίσματος, λίστα ονομάτων, λίστα θεμάτων και διαθέσιμους κόμβους. Έτσι, το Zookeeper διατηρεί τον συγχρονισμό μεταξύ των διαφορετικών στοιχείων του συμπλέγματος.
Το Zookeeper είναι σημαντικό γιατί ο Kafka είναι ένα κατανεμημένο σύστημα. δηλαδή η γραφή και η ανάγνωση γίνονται από πολλούς πελάτες ταυτόχρονα. Όταν υπάρχει βλάβη, ο Zookeeper επιλέγει έναν αντικαταστάτη και ανακτά τη λειτουργία.
Περιπτώσεις χρήσης
Το Kafka έγινε δημοφιλές, ειδικά για τη χρήση του ως εργαλείο ανταλλαγής μηνυμάτων, αλλά η ευελιξία του ξεπερνά αυτό και μπορεί να χρησιμοποιηθεί σε διάφορα σενάρια, όπως στα παρακάτω παραδείγματα.
Μηνύματα
Ασύγχρονη μορφή επικοινωνίας που αποσυνδέει τα μέρη που επικοινωνούν. Σε αυτό το μοντέλο, ένα μέρος στέλνει τα δεδομένα ως μήνυμα στον Κάφκα, οπότε μια άλλη εφαρμογή τα καταναλώνει αργότερα.
Παρακολούθηση δραστηριότητας
Σας δίνει τη δυνατότητα να αποθηκεύετε και να επεξεργάζεστε δεδομένα παρακολούθησης της αλληλεπίδρασης ενός χρήστη με έναν ιστότοπο, όπως προβολές σελίδας, κλικ, εισαγωγή δεδομένων κ.λπ. αυτός ο τύπος δραστηριότητας δημιουργεί συνήθως μεγάλο όγκο δεδομένων.
Μετρήσεις
Περιλαμβάνει τη συγκέντρωση δεδομένων και στατιστικών από πολλαπλές πηγές για τη δημιουργία μιας κεντρικής αναφοράς.
Συνάθροιση αρχείων καταγραφής
Συγκεντρώνει κεντρικά και αποθηκεύει αρχεία καταγραφής που προέρχονται από άλλα συστήματα.
Επεξεργασία ροής
Η επεξεργασία των αγωγών δεδομένων αποτελείται από πολλαπλά στάδια, όπου τα ακατέργαστα δεδομένα καταναλώνονται από θέματα και συγκεντρώνονται, εμπλουτίζονται ή μετατρέπονται σε άλλα θέματα.
Για την υποστήριξη αυτών των δυνατοτήτων, η πλατφόρμα ουσιαστικά παρέχει τρία API:
- Streams API: Λειτουργεί ως επεξεργαστής ροής που καταναλώνει δεδομένα από ένα θέμα, το μετατρέπει και το γράφει σε ένα άλλο.
- Connectors API: Επιτρέπει τη σύνδεση θεμάτων με υπάρχοντα συστήματα, όπως σχεσιακές βάσεις δεδομένων.
- API παραγωγού και καταναλωτή: Επιτρέπει στις εφαρμογές να δημοσιεύουν και να καταναλώνουν δεδομένα Kafka.
Πλεονεκτήματα
Αναπαραγωγή, Διαμερισμός και Παραγγελία
Τα μηνύματα στο Kafka αναπαράγονται σε κατατμήσεις σε κόμβους συμπλέγματος με τη σειρά που φτάνουν για να διασφαλιστεί η ασφάλεια και η ταχύτητα παράδοσης.
Μετασχηματισμός Δεδομένων
Με το Apache Kafka, είναι ακόμη δυνατός ο μετασχηματισμός της μαζικής επεξεργασίας σε πραγματικό χρόνο χρησιμοποιώντας το API ροών παρτίδας ETL.
Διαδοχική πρόσβαση στο δίσκο
Ο Apache Kafka επιμένει το μήνυμα στο δίσκο και όχι στη μνήμη, καθώς υποτίθεται ότι είναι πιο γρήγορο. Στην πραγματικότητα, η πρόσβαση στη μνήμη είναι ταχύτερη στις περισσότερες περιπτώσεις, ειδικά όταν εξετάζετε την πρόσβαση σε δεδομένα που βρίσκονται σε τυχαίες θέσεις στη μνήμη. Ωστόσο, ο Kafka κάνει διαδοχική πρόσβαση και σε αυτήν την περίπτωση, ο δίσκος είναι πιο αποτελεσματικός.
Apache Spark
Το Apache Spark είναι μια μηχανή υπολογιστών μεγάλων δεδομένων και ένα σύνολο βιβλιοθηκών για την επεξεργασία παράλληλων δεδομένων μεταξύ συστάδων. Το Spark είναι μια εξέλιξη του Hadoop και του παραδείγματος προγραμματισμού Map-Reduce. Μπορεί να είναι 100 φορές πιο γρήγορο χάρη στην αποτελεσματική χρήση της μνήμης που δεν διατηρεί δεδομένα στους δίσκους κατά την επεξεργασία.
Το Spark οργανώνεται σε τρία επίπεδα:
- API χαμηλού επιπέδου: Αυτό το επίπεδο περιέχει τη βασική λειτουργικότητα για την εκτέλεση εργασιών και άλλες λειτουργίες που απαιτούνται από τα άλλα στοιχεία. Άλλες σημαντικές λειτουργίες αυτού του επιπέδου είναι η διαχείριση της ασφάλειας, του δικτύου, του προγραμματισμού και της λογικής πρόσβασης στα συστήματα αρχείων HDFS, GlusterFS, Amazon S3 και άλλα.
- Δομημένα API: Το επίπεδο Structured API ασχολείται με τον χειρισμό δεδομένων μέσω συνόλων δεδομένων ή DataFrames, τα οποία μπορούν να διαβαστούν σε μορφές όπως Hive, Parquet, JSON και άλλες. Χρησιμοποιώντας το SparkSQL (API που μας επιτρέπει να γράφουμε ερωτήματα σε SQL), μπορούμε να χειριστούμε τα δεδομένα με τον τρόπο που θέλουμε.
- Υψηλό επίπεδο: Στο υψηλότερο επίπεδο, έχουμε το οικοσύστημα Spark με διάφορες βιβλιοθήκες, συμπεριλαμβανομένων των Spark Streaming, Spark MLlib και Spark GraphX. Είναι υπεύθυνοι για τη φροντίδα της απορρόφησης ροής και των γύρω διεργασιών, όπως η ανάκτηση σφαλμάτων, η δημιουργία και η επικύρωση κλασικών μοντέλων μηχανικής εκμάθησης και η αντιμετώπιση γραφημάτων και αλγορίθμων.
Εργασία του Spark
Η αρχιτεκτονική μιας εφαρμογής Spark αποτελείται από τρία κύρια μέρη:
Πρόγραμμα οδήγησης: Είναι υπεύθυνο για την ενορχήστρωση της εκτέλεσης της επεξεργασίας δεδομένων.
Cluster Manager: Είναι το στοιχείο που είναι υπεύθυνο για τη διαχείριση των διαφορετικών μηχανημάτων σε ένα σύμπλεγμα. Χρειάζεται μόνο εάν το Spark τρέχει διανεμημένο.
Κόμβοι εργαζομένων: Είναι οι μηχανές που εκτελούν τις εργασίες ενός προγράμματος. Εάν το Spark εκτελείται τοπικά στο μηχάνημά σας, θα παίξει ένα πρόγραμμα οδήγησης και έναν ρόλο Workes. Αυτός ο τρόπος λειτουργίας του Spark ονομάζεται Standalone.
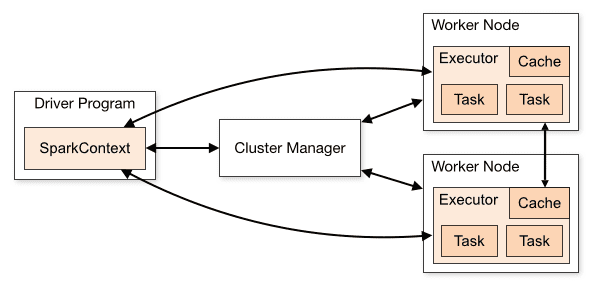 Επισκόπηση συμπλέγματος
Επισκόπηση συμπλέγματος
Ο κώδικας σπινθήρων μπορεί να γραφτεί σε πολλές διαφορετικές γλώσσες. Η κονσόλα Spark, που ονομάζεται Spark Shell, είναι διαδραστική για εκμάθηση και εξερεύνηση δεδομένων.
Η λεγόμενη εφαρμογή Spark αποτελείται από μία ή περισσότερες εργασίες, επιτρέποντας την υποστήριξη μεγάλης κλίμακας επεξεργασίας δεδομένων.
Όταν μιλάμε για εκτέλεση, το Spark έχει δύο τρόπους:
- Πελάτης: Το πρόγραμμα οδήγησης εκτελείται απευθείας στον υπολογιστή-πελάτη, ο οποίος δεν περνά από τη Διαχείριση πόρων.
- Cluster: Πρόγραμμα οδήγησης που εκτελείται στο Application Master μέσω του Resource Manager (Σε λειτουργία Cluster, εάν ο πελάτης αποσυνδεθεί, η εφαρμογή θα συνεχίσει να εκτελείται).
Είναι απαραίτητο να χρησιμοποιείτε σωστά το Spark, ώστε οι συνδεδεμένες υπηρεσίες, όπως το Resource Manager, να μπορούν να εντοπίσουν την ανάγκη για κάθε εκτέλεση, παρέχοντας την καλύτερη απόδοση. Επομένως, εναπόκειται στον προγραμματιστή να γνωρίζει τον καλύτερο τρόπο εκτέλεσης των εργασιών Spark του, δομώντας την κλήση που πραγματοποιήθηκε, και για αυτό, μπορείτε να δομήσετε και να διαμορφώσετε τους εκτελεστές Spark όπως θέλετε.
Οι εργασίες Spark χρησιμοποιούν κυρίως μνήμη, επομένως είναι σύνηθες να προσαρμόζονται οι τιμές διαμόρφωσης Spark για εκτελεστές κόμβων εργασίας. Ανάλογα με τον φόρτο εργασίας του Spark, είναι δυνατό να προσδιοριστεί ότι μια συγκεκριμένη μη τυπική διαμόρφωση Spark παρέχει πιο βέλτιστες εκτελέσεις. Για το σκοπό αυτό, μπορούν να πραγματοποιηθούν δοκιμές σύγκρισης μεταξύ των διαφόρων διαθέσιμων επιλογών διαμόρφωσης και της ίδιας της προεπιλεγμένης διαμόρφωσης Spark.
Θήκες χρήσεων
Το Apache Spark βοηθά στην επεξεργασία τεράστιων ποσοτήτων δεδομένων, είτε σε πραγματικό χρόνο είτε αρχειοθετημένα, δομημένα ή μη. Ακολουθούν μερικές από τις δημοφιλείς περιπτώσεις χρήσης του.
Εμπλουτισμός Δεδομένων
Συχνά οι εταιρείες χρησιμοποιούν έναν συνδυασμό ιστορικών δεδομένων πελατών με δεδομένα συμπεριφοράς σε πραγματικό χρόνο. Το Spark μπορεί να βοηθήσει στη δημιουργία ενός συνεχούς αγωγού ETL για τη μετατροπή μη δομημένων δεδομένων συμβάντων σε δομημένα δεδομένα.
Ανίχνευση συμβάντος ενεργοποίησης
Το Spark Streaming επιτρέπει την ταχεία ανίχνευση και απόκριση σε κάποια σπάνια ή ύποπτη συμπεριφορά που θα μπορούσε να υποδηλώνει πιθανό πρόβλημα ή απάτη.
Σύνθετη Ανάλυση Δεδομένων Συνεδρίας
Χρησιμοποιώντας το Spark Streaming, τα συμβάντα που σχετίζονται με τη συνεδρία του χρήστη, όπως οι δραστηριότητές του μετά τη σύνδεση στην εφαρμογή, μπορούν να ομαδοποιηθούν και να αναλυθούν. Αυτές οι πληροφορίες μπορούν επίσης να χρησιμοποιηθούν συνεχώς για την ενημέρωση μοντέλων μηχανικής εκμάθησης.
Πλεονεκτήματα
Επαναληπτική επεξεργασία
Εάν η εργασία είναι η επανειλημμένη επεξεργασία δεδομένων, τα ελαστικά κατανεμημένα σύνολα δεδομένων (RDD) του Spark επιτρέπουν πολλαπλές λειτουργίες χαρτών στη μνήμη χωρίς να χρειάζεται να γράφονται ενδιάμεσα αποτελέσματα στο δίσκο.
Γραφική επεξεργασία
Το υπολογιστικό μοντέλο του Spark με το GraphX API είναι εξαιρετικό για επαναληπτικούς υπολογισμούς τυπικούς της επεξεργασίας γραφικών.
Μηχανική μάθηση
Το Spark διαθέτει MLlib — μια ενσωματωμένη βιβλιοθήκη μηχανικής εκμάθησης που διαθέτει έτοιμους αλγόριθμους που τρέχουν επίσης στη μνήμη.
Κάφκα εναντίον Σπαρκ
Παρόλο που το ενδιαφέρον των ανθρώπων τόσο για τον Κάφκα όσο και για τον Σπαρκ ήταν σχεδόν παρόμοιο, υπάρχουν κάποιες σημαντικές διαφορές μεταξύ των δύο. Ας ρίξουμε μια ματιά.
#1. Επεξεργασία δεδομένων
Το Kafka είναι ένα εργαλείο ροής και αποθήκευσης δεδομένων σε πραγματικό χρόνο που είναι υπεύθυνο για τη μεταφορά δεδομένων μεταξύ εφαρμογών, αλλά δεν αρκεί για τη δημιουργία μιας ολοκληρωμένης λύσης. Επομένως, χρειάζονται άλλα εργαλεία για εργασίες που δεν κάνει ο Κάφκα, όπως το Spark. Το Spark, από την άλλη πλευρά, είναι μια πλατφόρμα επεξεργασίας δεδομένων πρώτης παρτίδας που αντλεί δεδομένα από θέματα του Κάφκα και τα μετατρέπει σε συνδυασμένα σχήματα.
#2. Διαχείριση μνήμης
Το Spark χρησιμοποιεί Robust Distributed Datasets (RDD) για τη διαχείριση της μνήμης. Αντί να προσπαθεί να επεξεργαστεί τεράστια σύνολα δεδομένων, τα διανέμει σε πολλούς κόμβους σε ένα σύμπλεγμα. Αντίθετα, ο Kafka χρησιμοποιεί διαδοχική πρόσβαση παρόμοια με το HDFS και αποθηκεύει δεδομένα σε μια προσωρινή μνήμη.
#3. Μετασχηματισμός ETL
Τόσο το Spark όσο και ο Kafka υποστηρίζουν τη διαδικασία μετασχηματισμού ETL, η οποία αντιγράφει εγγραφές από τη μια βάση δεδομένων στην άλλη, συνήθως από μια βάση συναλλαγών (OLTP) σε μια αναλυτική βάση (OLAP). Ωστόσο, σε αντίθεση με το Spark, το οποίο διαθέτει ενσωματωμένη δυνατότητα για τη διαδικασία ETL, ο Kafka βασίζεται στο Streams API για να το υποστηρίξει.
#4. Εμμονή δεδομένων

Η χρήση του RRD από το Spark σάς επιτρέπει να αποθηκεύετε τα δεδομένα σε πολλές τοποθεσίες για μελλοντική χρήση, ενώ στο Kafka, πρέπει να ορίσετε αντικείμενα δεδομένων σε διαμόρφωση για να διατηρούνται δεδομένα.
#5. Δυσκολία
Το Spark είναι μια ολοκληρωμένη λύση και ευκολότερη εκμάθηση λόγω της υποστήριξής του σε διάφορες γλώσσες προγραμματισμού υψηλού επιπέδου. Ο Kafka εξαρτάται από μια σειρά από διαφορετικά API και λειτουργικές μονάδες τρίτων, γεγονός που μπορεί να δυσκολέψει την εργασία.
#6. Ανάκτηση
Τόσο το Spark όσο και το Kafka παρέχουν επιλογές ανάκτησης. Το Spark χρησιμοποιεί το RRD, το οποίο του επιτρέπει να αποθηκεύει δεδομένα συνεχώς, και εάν υπάρχει αποτυχία συμπλέγματος, μπορεί να ανακτηθεί.

Ο Κάφκα αναπαράγει συνεχώς δεδομένα μέσα στο σύμπλεγμα και αναπαράγει σε μεσίτες, κάτι που σας επιτρέπει να μεταβείτε στους διαφορετικούς μεσίτες εάν υπάρχει αποτυχία.
Ομοιότητες μεταξύ Spark και Kafka
Apache SparkApache KafkaOpenSourceOpenSourceBuild Ροή Δεδομένων ApplicationBuild Ροή Δεδομένων ApplicationSupports Stateful ProcessingΥποστηρίζει Stateful ProcessingΥποστηρίζει SQLSΥποστηρίζει SQLSομοιότητες μεταξύ Spark και Kafka
Τελικές Λέξεις
Το Kafka και το Spark είναι και τα δύο εργαλεία ανοιχτού κώδικα γραμμένα σε Scala και Java, τα οποία σας επιτρέπουν να δημιουργείτε εφαρμογές ροής δεδομένων σε πραγματικό χρόνο. Έχουν πολλά κοινά πράγματα, συμπεριλαμβανομένης της stateful processing, της υποστήριξης για SQL και ETL. Το Kafka και το Spark μπορούν επίσης να χρησιμοποιηθούν ως συμπληρωματικά εργαλεία για να βοηθήσουν στην επίλυση του προβλήματος της πολυπλοκότητας της μεταφοράς δεδομένων μεταξύ εφαρμογών.